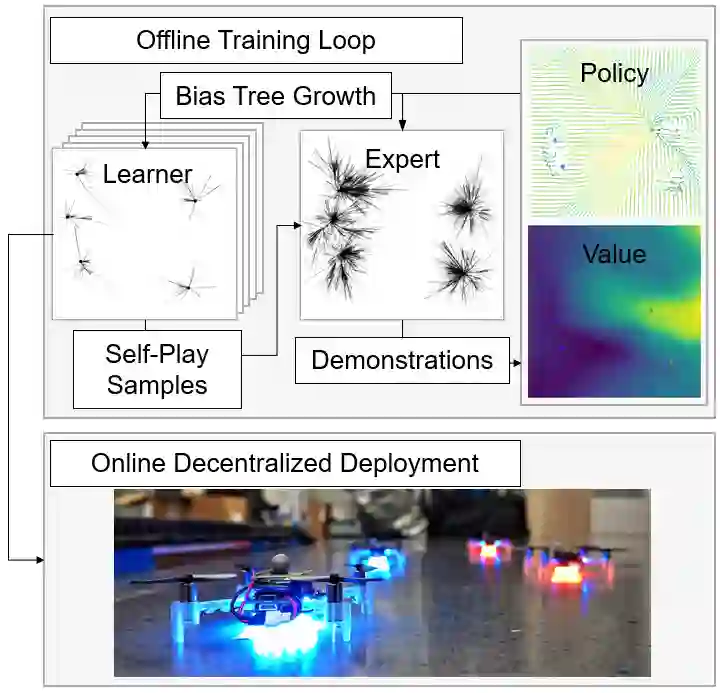
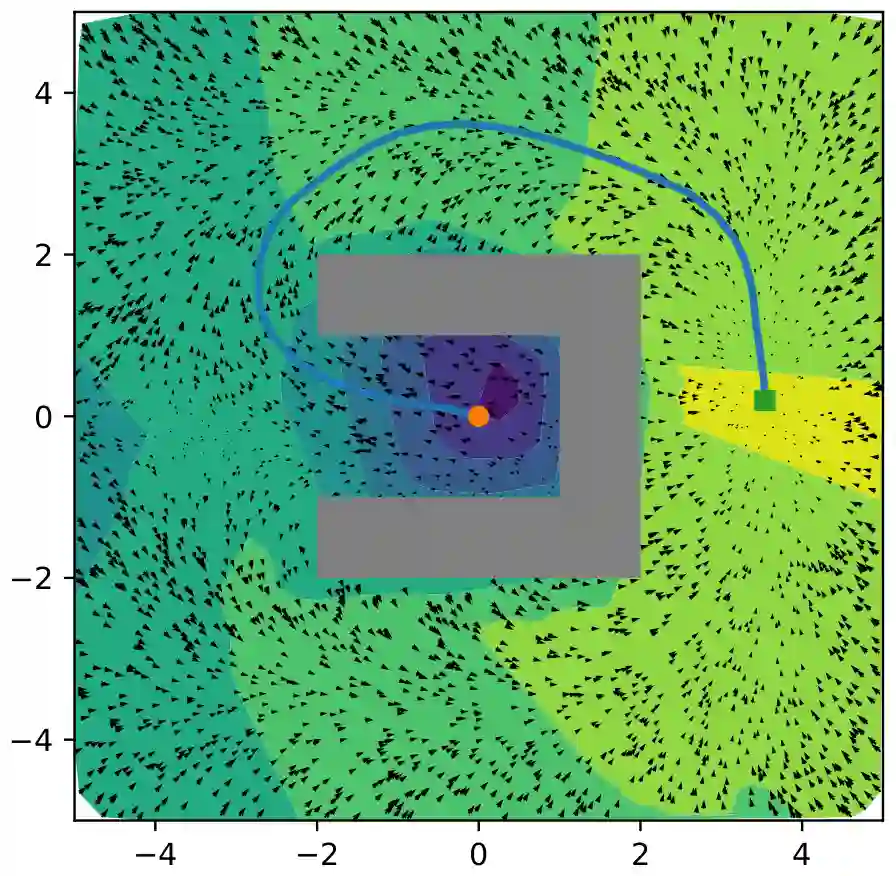
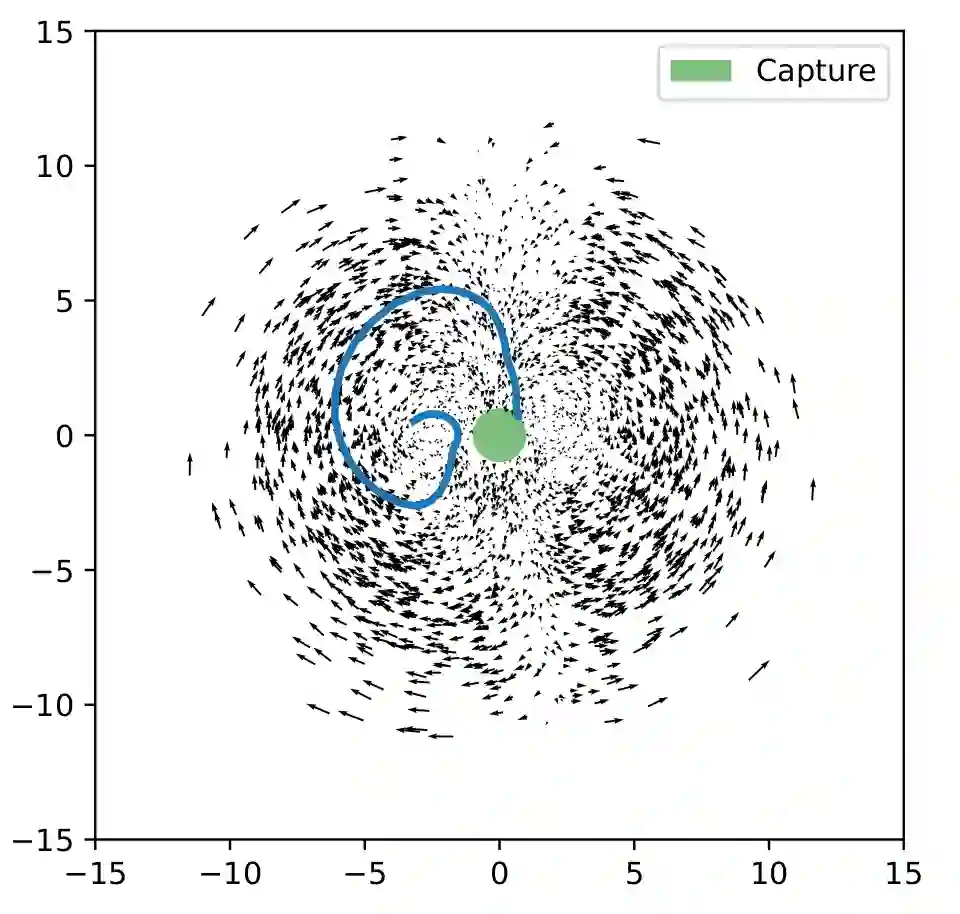
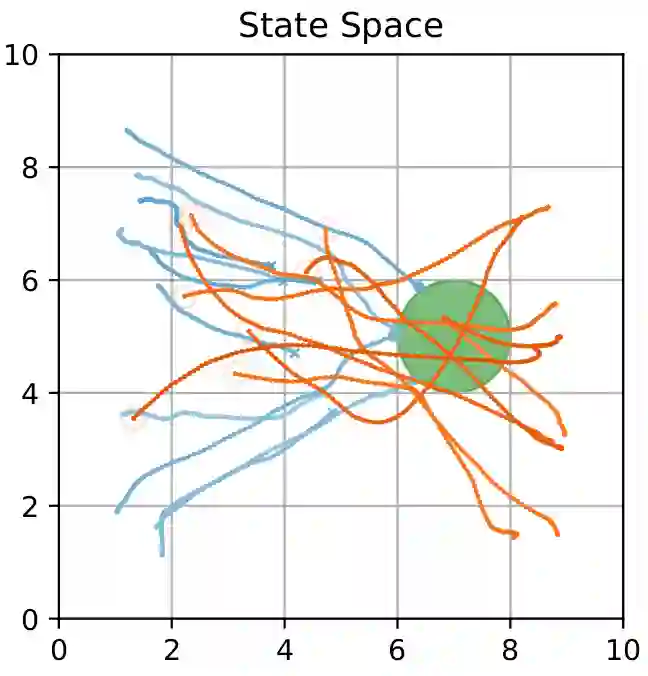
We present a self-improving, Neural Tree Expansion (NTE) method for multi-robot online planning in non-cooperative environments, where each robot attempts to maximize its cumulative reward while interacting with other self-interested robots. Our algorithm adapts the centralized, perfect information, discrete-action space method from AlphaZero to a decentralized, partial information, continuous action space setting for multi-robot applications. Our method has three interacting components: (i) a centralized, perfect-information "expert" Monte Carlo Tree Search (MCTS) with large computation resources that provides expert demonstrations, (ii) a decentralized, partial-information "learner" MCTS with small computation resources that runs in real-time and provides self-play examples, and (iii) policy & value neural networks that are trained with the expert demonstrations and bias both the expert and the learner tree growth. Our numerical experiments demonstrate Neural Tree Expansion's computational advantage by finding better solutions than a MCTS with 20 times more resources. The resulting policies are dynamically sophisticated, demonstrate coordination between robots, and play the Reach-Target-Avoid differential game significantly better than the state-of-the-art control-theoretic baseline for multi-robot, double-integrator systems. Our hardware experiments on an aerial swarm demonstrate the computational advantage of Neural Tree Expansion, enabling online planning at 20Hz with effective policies in complex scenarios.
翻译:我们提出了一种自我改进、神经树扩展(NTE)方法,用于在不合作的环境中进行多机器人在线规划,在这种环境中,每个机器人都试图在与其他自感兴趣的机器人互动的同时,最大限度地增加累积的奖励。我们的算法将中央、完美的信息、离散的空间活动空间方法从阿尔法泽罗改造成分散的、部分的信息、多机器人应用的持续行动空间设置。我们的方法有三个互动组成部分:(一) 集中的、完美的信息“专家”蒙特卡洛树搜索(MCTS),拥有大量计算资源,提供专家演示;(二) 分散的、部分信息“Learner” MCTS,拥有实时运行的小型计算资源,并提供自玩范例;以及(三) 政策和价值神经神经网络,经过专家演示的训练,对专家和学习者树的增长抱有偏见。我们的数字实验显示,神经树扩展的优势在于找到比复杂20倍资源的MCTTS(MTS)的更佳的解决方案。由此形成的政策是动态复杂的,展示机器人之间的协调,以及在我们20级的双轨(Orige-Tal-Tarial-Hareal-al-alalalalal-alalalalalal-chailalal)的游戏基底系统上,比更能性地展示我们的20-real-real-real-real-traal-traal-traction-traction-traction-traction-traction-traction-traction-traction-traction-traction-traction-tragystegystegystegrogrogystegystegystegystegystegystection系统要好得多。