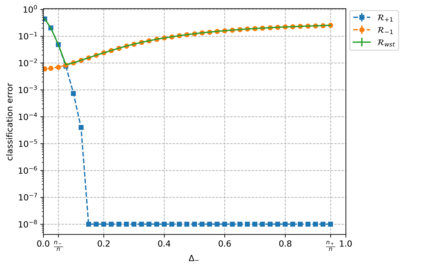
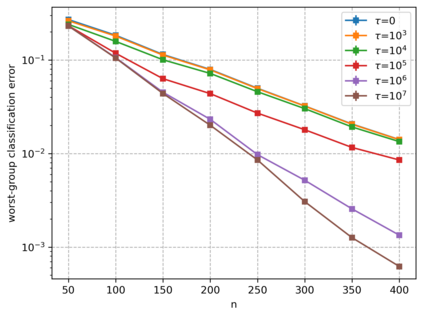
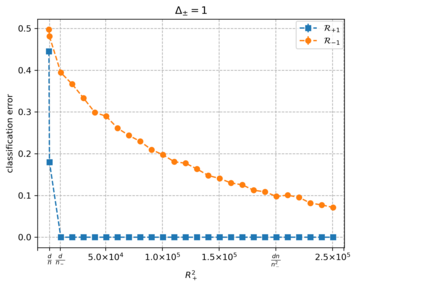
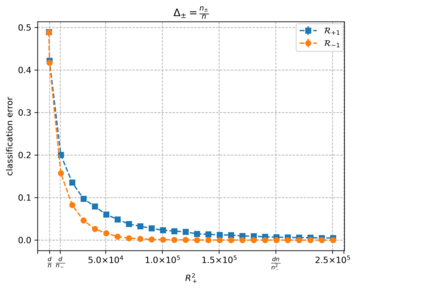
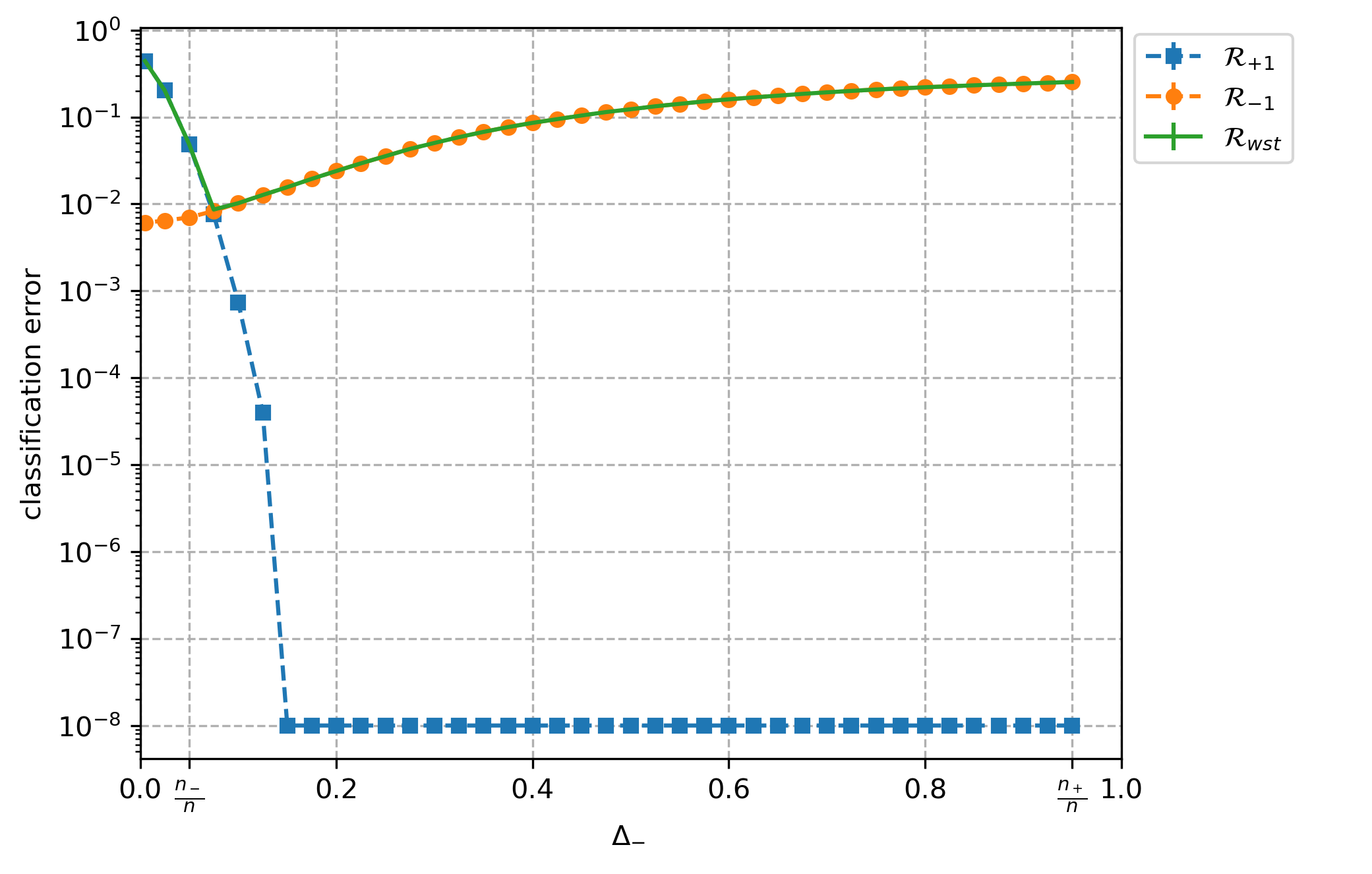
Overparameterized models that achieve zero training error are observed to generalize well on average, but degrade in performance when faced with data that is under-represented in the training sample. In this work, we study an overparameterized Gaussian mixture model imbued with a spurious feature, and sharply analyze the in-distribution and out-of-distribution test error of a cost-sensitive interpolating solution that incorporates "importance weights". Compared to recent work Wang et al. (2021), Behnia et al. (2022), our analysis is sharp with matching upper and lower bounds, and significantly weakens required assumptions on data dimensionality. Our error characterizations also apply to any choice of importance weights and unveil a novel tradeoff between worst-case robustness to distribution shift and average accuracy as a function of the importance weight magnitude.
翻译:暂无翻译