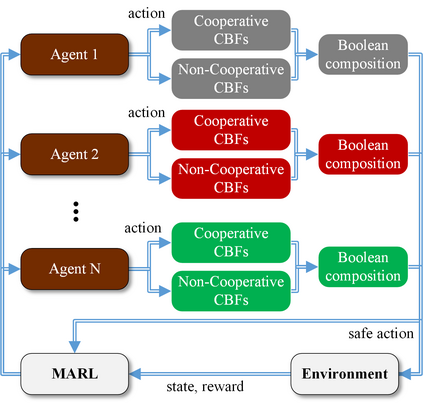
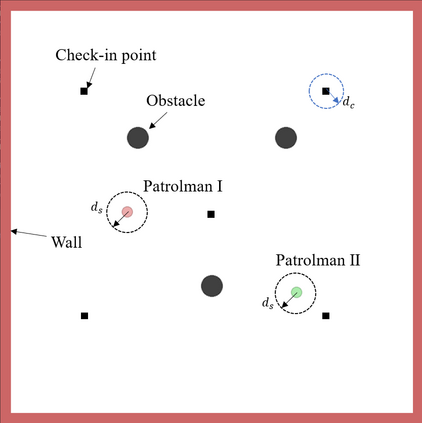
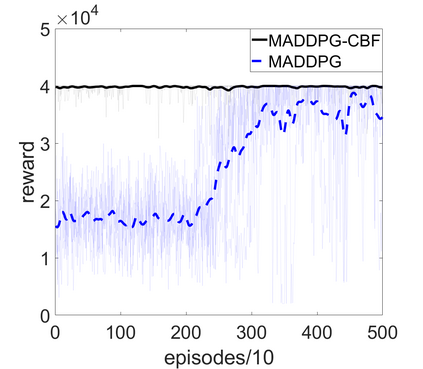
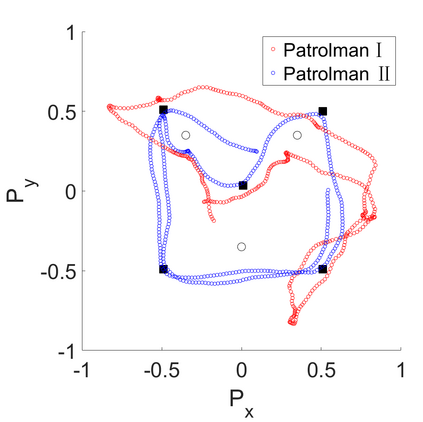
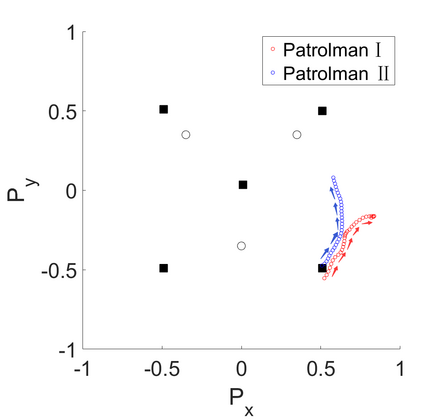
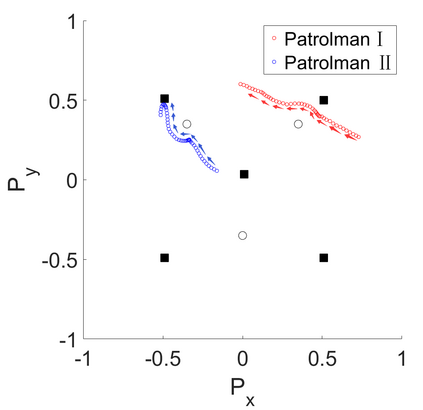
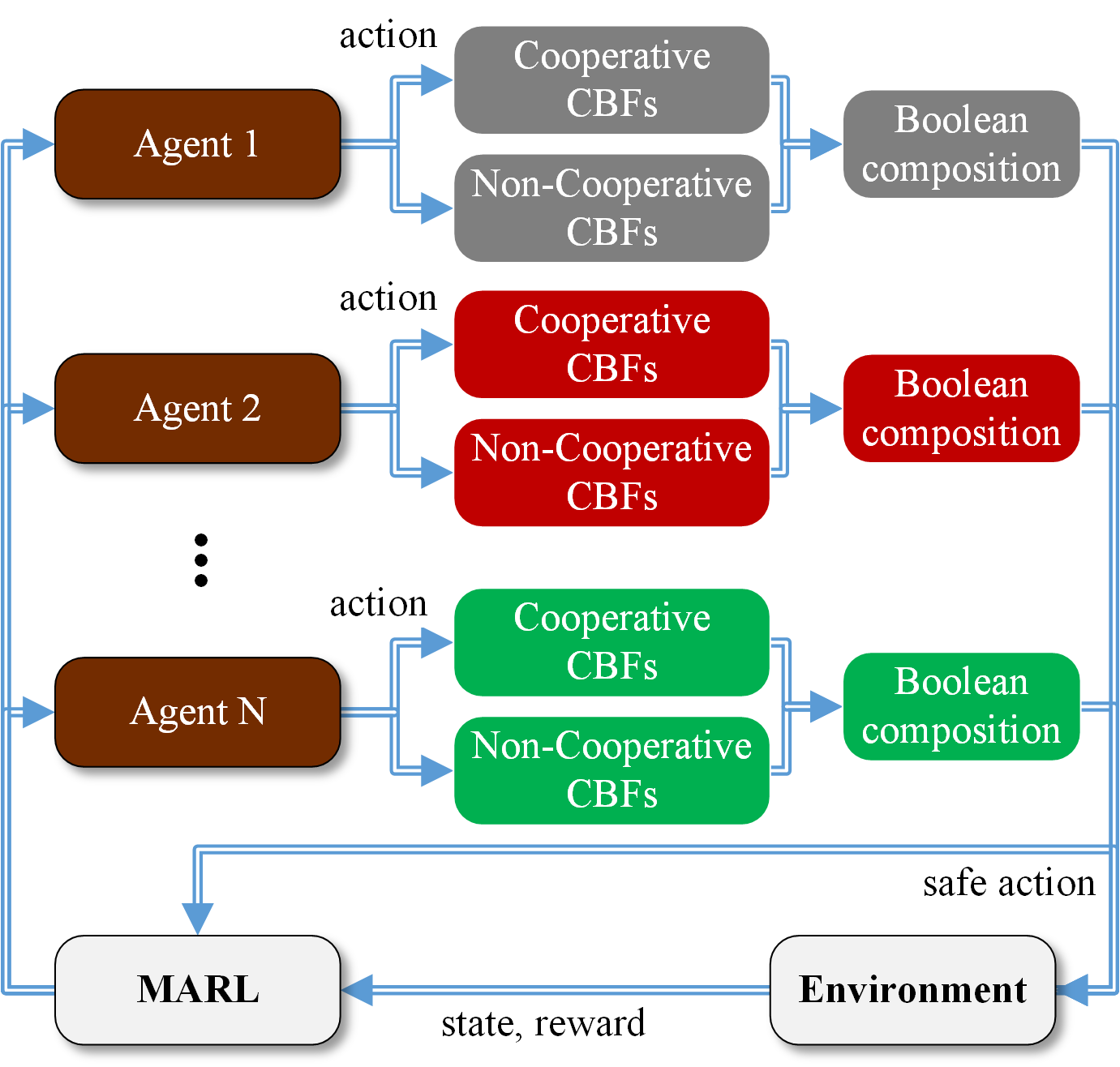
Multi-Agent Reinforcement Learning (MARL) algorithms show amazing performance in simulation in recent years, but placing MARL in real-world applications may suffer safety problems. MARL with centralized shields was proposed and verified in safety games recently. However, centralized shielding approaches can be infeasible in several real-world multi-agent applications that involve non-cooperative agents or communication delay. Thus, we propose to combine MARL with decentralized Control Barrier Function (CBF) shields based on available local information. We establish a safe MARL framework with decentralized multiple CBFs and develop Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to Multi-Agent Deep Deterministic Policy Gradient with decentralized multiple Control Barrier Functions (MADDPG-CBF). Based on a collision-avoidance problem that includes not only cooperative agents but obstacles, we demonstrate the construction of multiple CBFs with safety guarantees in theory. Experiments are conducted and experiment results verify that the proposed safe MARL framework can guarantee the safety of agents included in MARL.
翻译:近些年来,多机构强化学习(MARL)算法在模拟中表现出惊人的性能,但将MARL置于现实世界应用中可能会遇到安全问题。在安全游戏中,提出并核实了使用中央防护盾的MARL。然而,在涉及不合作剂或通信延迟的若干现实世界多剂应用中,集中防护办法可能行不通。因此,我们提议根据当地现有信息,将MARL与分散控制屏障功能盾牌结合起来。我们建立了一个安全MARL框架,分权多个CBFs,并制定了多级、深层决定力政策梯度(MADDPG),以多级、低级控制屏障功能(MADPG-CBF)为主。基于一个碰撞避免问题,不仅包括合作剂,而且包括障碍。我们展示了多个CBFS和理论安全保障的构建过程。我们进行了实验,实验结果证实,拟议的安全MARL框架能够保证MARL所列代理人的安全。