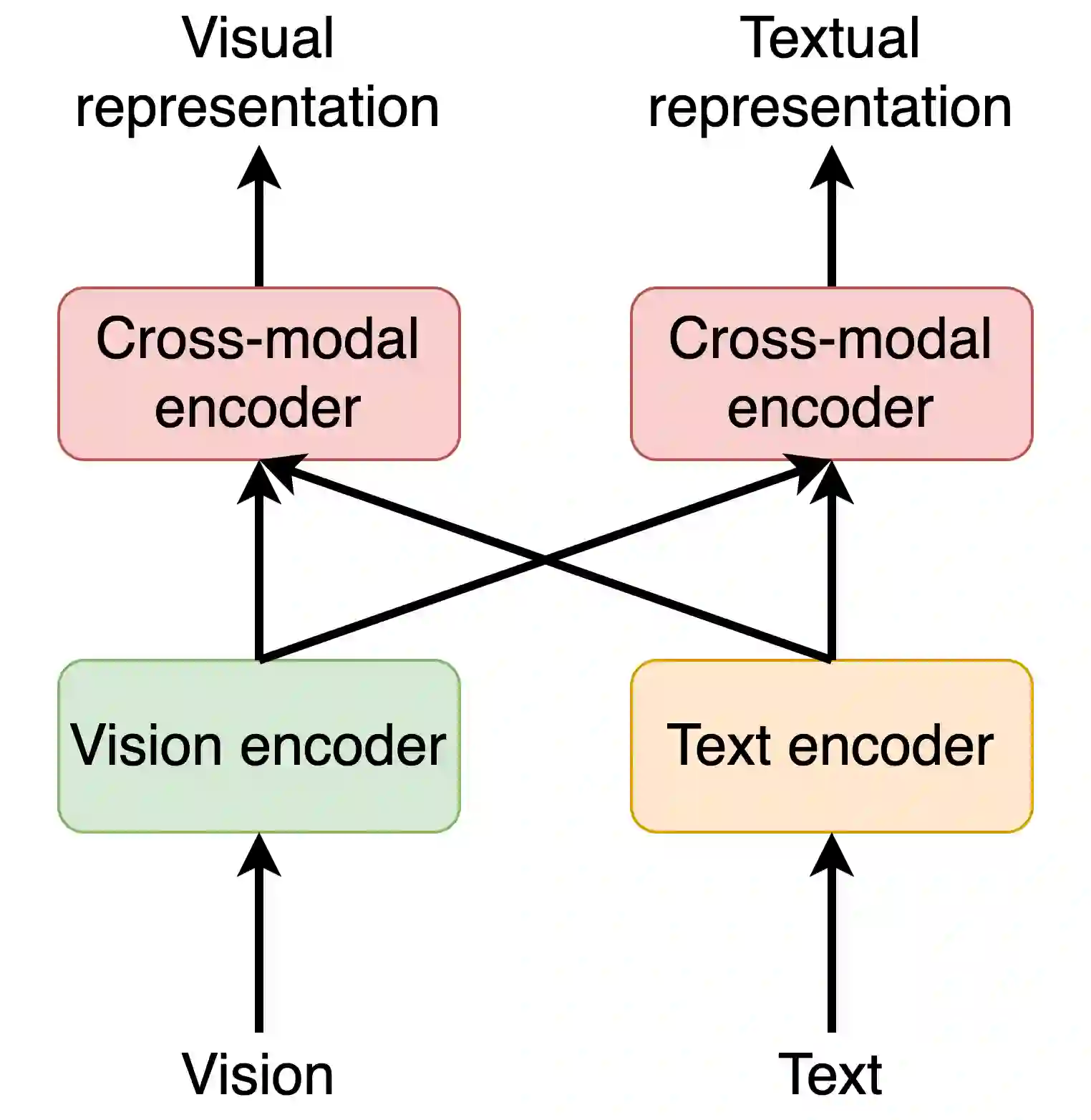
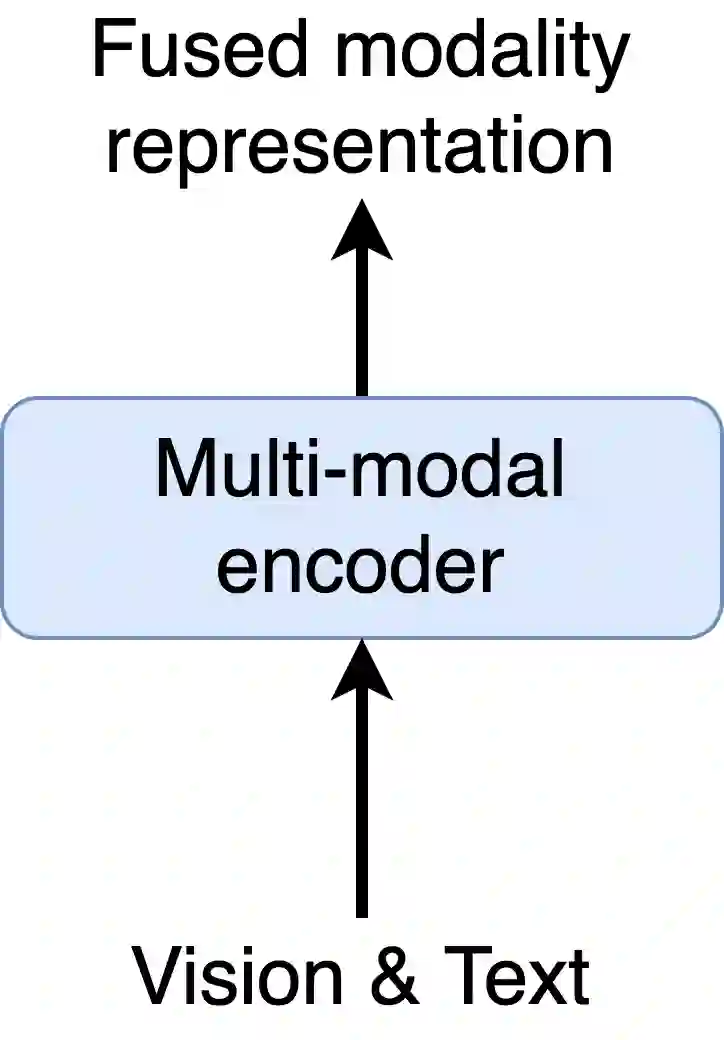
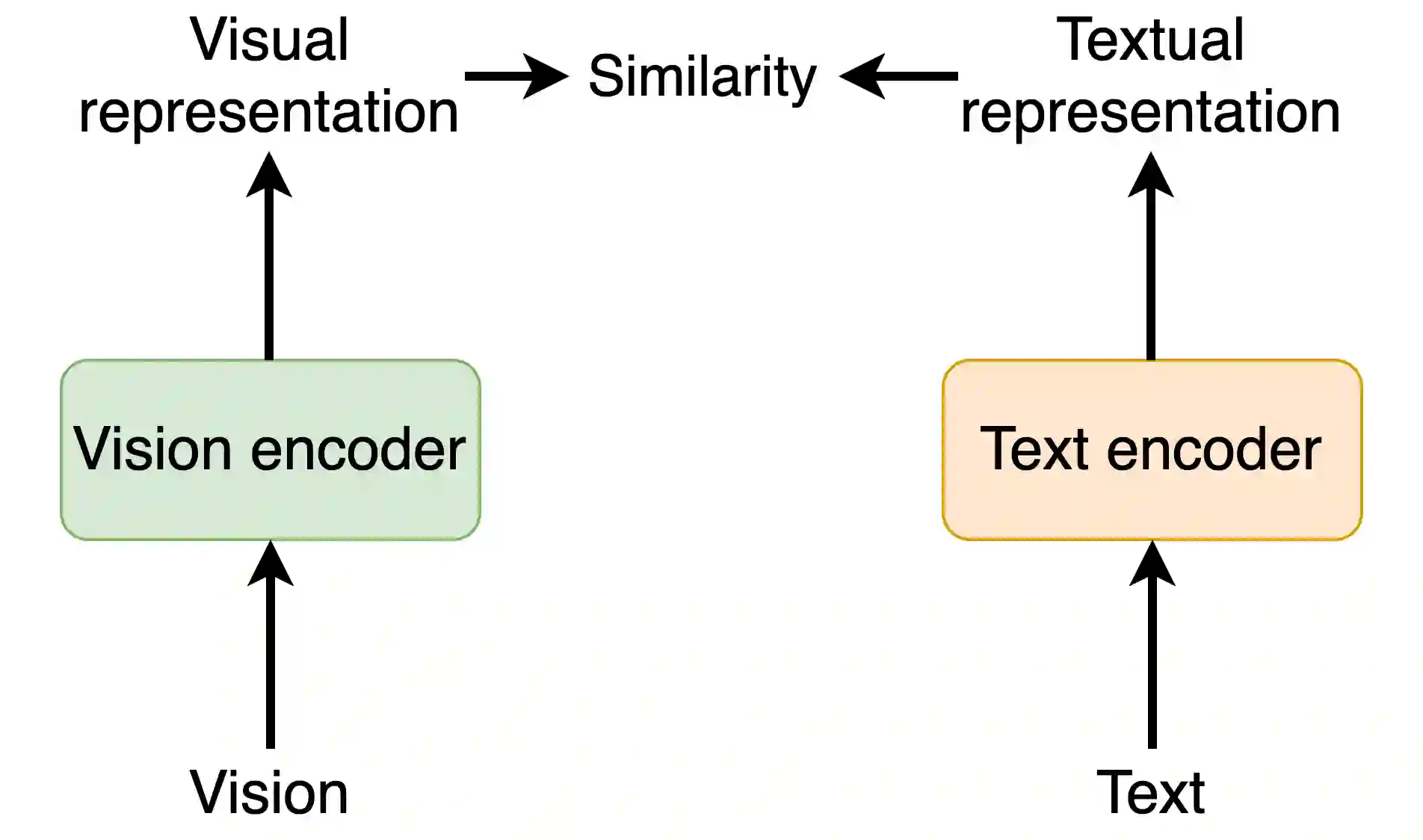
To solve video-and-language grounding tasks, the key is for the network to understand the connection between the two modalities. For a pair of video and language description, their semantic relation is reflected by their encodings' similarity. A good multi-modality encoder should be able to well capture both inputs' semantics and encode them in the shared feature space where embedding distance gets properly translated into their semantic similarity. In this work, we focused on this semantic connection between video and language, and developed a multi-level alignment training scheme to directly shape the encoding process. Global and segment levels of video-language alignment pairs were designed, based on the information similarity ranging from high-level context to fine-grained semantics. The contrastive loss was used to contrast the encodings' similarities between the positive and negative alignment pairs, and to ensure the network is trained in such a way that similar information is encoded closely in the shared feature space while information of different semantics is kept apart. Our multi-level alignment training can be applied to various video-and-language grounding tasks. Together with the task-specific training loss, our framework achieved comparable performance to previous state-of-the-arts on multiple video QA and retrieval datasets.
翻译:要解决视频和语言的定位任务,关键在于网络了解两种模式之间的联系。对于一对视频和语言描述,它们的语义关系通过编码相似性反映出来。好的多式编码器应该能够很好地捕捉输入的语义和编码在共同的特征空间中,其中嵌入的距离被适当地转化成其语义相似性。在这项工作中,我们侧重于视频和语言之间的语义联系,并制定了一个多层次的校正培训计划,以直接塑造编码进程。视频和语言对齐组的全球和部分级别是设计出来的,其信息相似性从高层次背景到精细拼凑的语义。对比性损失被用来对比正对和负对齐对齐的语义的校正和负对,并确保对网络进行培训的方式是,使类似信息在共享的语义空间中被密切编码,同时将不同语义的信息分开。我们多层次的校正培训可以应用于各种视频和语言对齐的定位任务,同时将我们以前完成的视频和语言对齐的图像检索框架与我们以往的具体任务损失的图像检索结合起来。