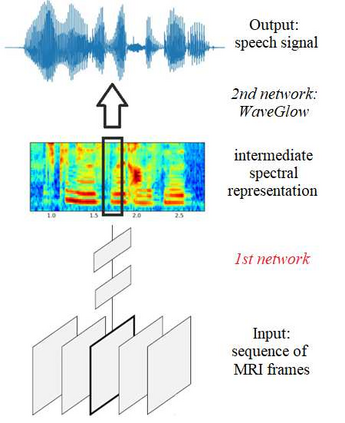
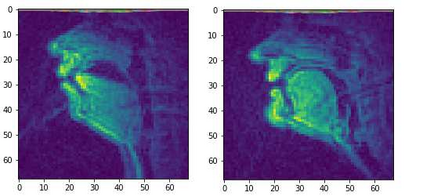
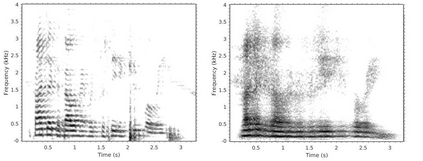
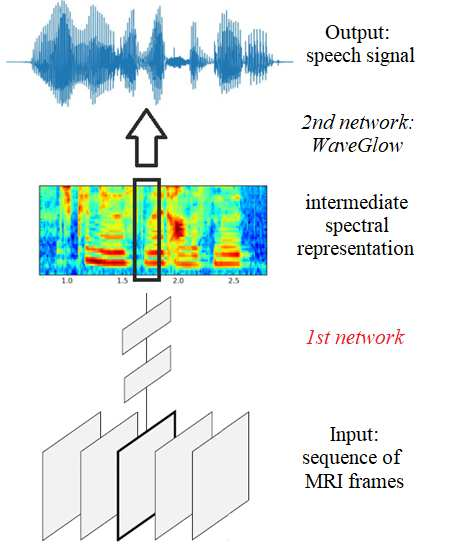
Several approaches exist for the recording of articulatory movements, such as eletromagnetic and permanent magnetic articulagraphy, ultrasound tongue imaging and surface electromyography. Although magnetic resonance imaging (MRI) is more costly than the above approaches, the recent developments in this area now allow the recording of real-time MRI videos of the articulators with an acceptable resolution. Here, we experiment with the reconstruction of the speech signal from a real-time MRI recording using deep neural networks. Instead of estimating speech directly, our networks are trained to output a spectral vector, from which we reconstruct the speech signal using the WaveGlow neural vocoder. We compare the performance of three deep neural architectures for the estimation task, combining convolutional (CNN) and recurrence-based (LSTM) neural layers. Besides the mean absolute error (MAE) of our networks, we also evaluate our models by comparing the speech signals obtained using several objective speech quality metrics like the mean cepstral distortion (MCD), Short-Time Objective Intelligibility (STOI), Perceptual Evaluation of Speech Quality (PESQ) and Signal-to-Distortion Ratio (SDR). The results indicate that our approach can successfully reconstruct the gross spectral shape, but more improvements are needed to reproduce the fine spectral details.
翻译:存在几种记录动脉动的方法,例如电磁和永久磁动脉动、超声波舌成像和地表电动学。虽然磁共振成像比上述方法更昂贵,但最近这一领域的发展使得能够以可接受的分辨率实时记录动脉动的MRI视频。在这里,我们试验利用深神经网络从实时MRI录音中重建语音信号。我们的网络不是直接估计讲话,而是训练一个光谱矢量器,我们从中利用波格罗神经电动器重建语音信号。我们比较了三种深神经结构的性能,以估计任务为目的,将进动(CNN)和复发(LSTM)神经层结合起来。除了我们网络的绝对偏差(MAE)之外,我们还通过比较使用一些客观的语音质量指标(例如中度扭曲)、短时端目标智能(STOI),短端感应变微图像(PS-DRR)的模型改进(SIMQ-DRBR ) 和图像(SIR-BRBR)的改进方法(S-BRIQ) 所需的总质量和(PIS-BRIS-BRRRRR) 改进结果(S-S-BRisalQ),我们所需要的总的改进)。