
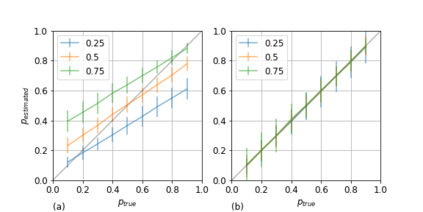
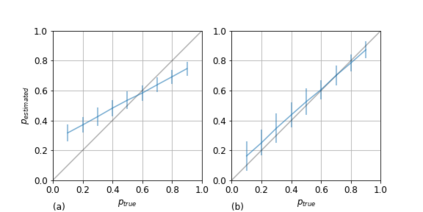
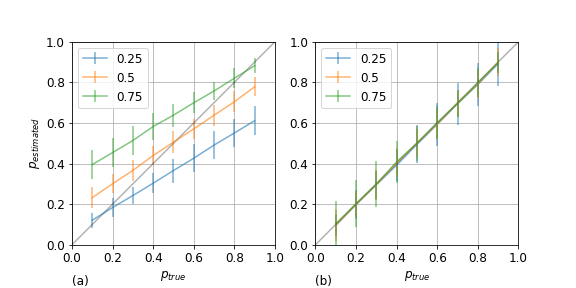
Binary classifiers trained on a certain proportion of positive items introduce a bias when applied to data sets with different proportions of positive items. Most solutions for dealing with this issue assume that some information on the latter distribution is known. However, this is not always the case, certainly when this proportion is the target variable. In this paper a maximum likelihood estimator for the true proportion of positives in data sets is suggested and tested on synthetic and real world data.
翻译:就一定比例的正值项目接受过培训的二分位分类人员在对不同比例的正值项目数据集适用时会引入偏差,处理该问题的多数解决办法假定已经知道关于后一种分布的某些信息,但情况并非总是如此,当然当该比例是目标变量时也是如此。本文建议并用合成和真实世界数据测试数据集正值真实比例的最大可能性估计值。
相关内容

专知会员服务
54+阅读 · 2020年3月5日
Arxiv
0+阅读 · 2021年4月8日
Arxiv
11+阅读 · 2018年7月12日

相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
相关资讯
相关论文
Arxiv
0+阅读 · 2021年4月8日
Arxiv
11+阅读 · 2018年7月12日