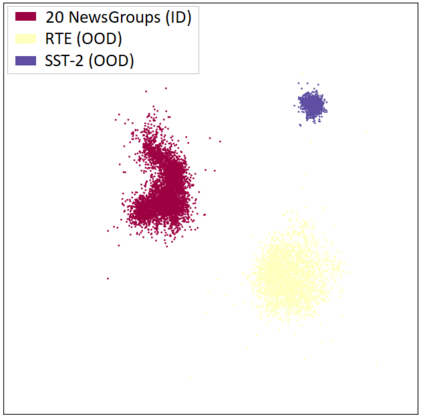
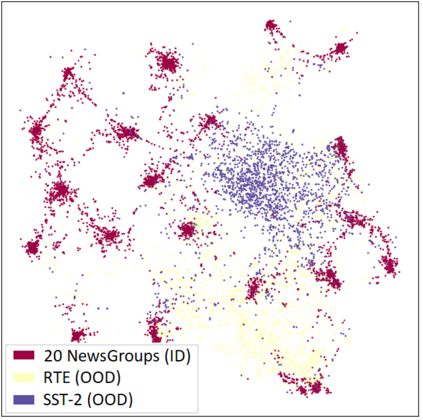
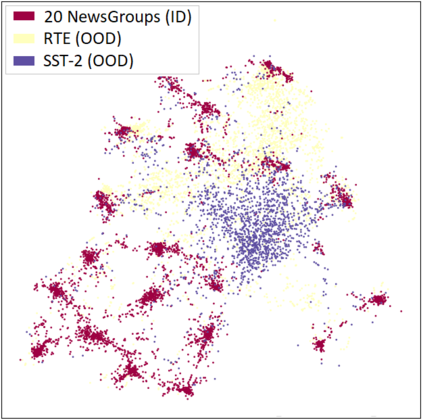
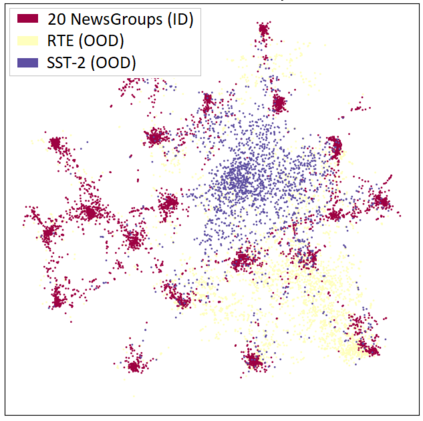
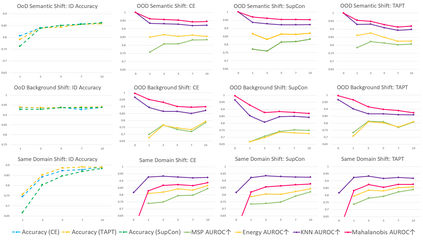
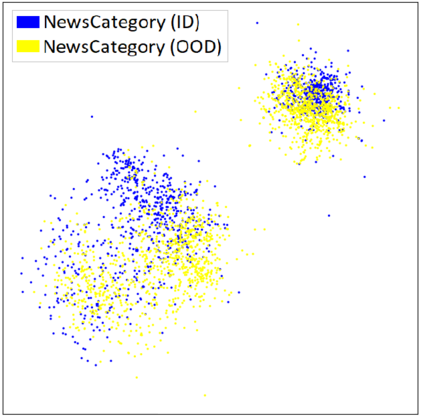
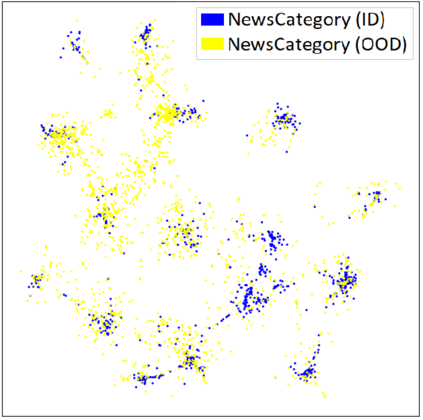
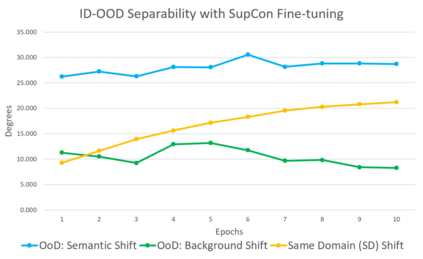
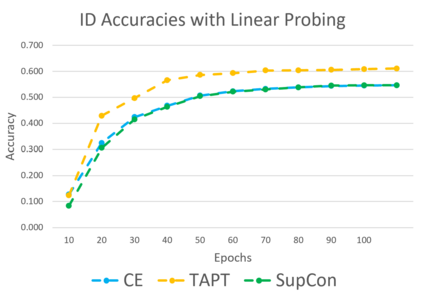
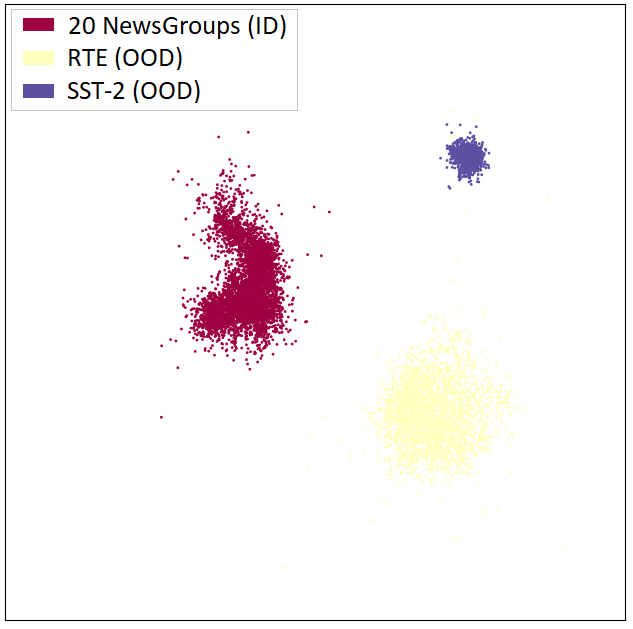
Out-of-distribution (OOD) detection is a critical task for reliable predictions over text. Fine-tuning with pre-trained language models has been a de facto procedure to derive OOD detectors with respect to in-distribution (ID) data. Despite its common use, the understanding of the role of fine-tuning and its necessity for OOD detection is largely unexplored. In this paper, we raise the question: is fine-tuning necessary for OOD detection? We present a study investigating the efficacy of directly leveraging pre-trained language models for OOD detection, without any model fine-tuning on the ID data. We compare the approach with several competitive fine-tuning objectives, and offer new insights under various types of distributional shifts. Extensive evaluations on 8 diverse ID-OOD dataset pairs demonstrate near-perfect OOD detection performance (with 0% FPR95 in many cases), strongly outperforming its fine-tuned counterparts. We show that using distance-based detection methods, pre-trained language models are near-perfect OOD detectors when the distribution shift involves a domain change. Furthermore, we study the effect of fine-tuning on OOD detection and identify how to balance ID accuracy with OOD detection performance. Our code is publically available at https://github.com/Uppaal/lm-ood.
翻译:暂无翻译