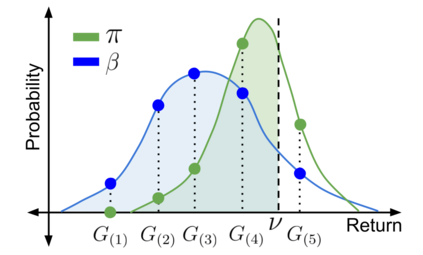
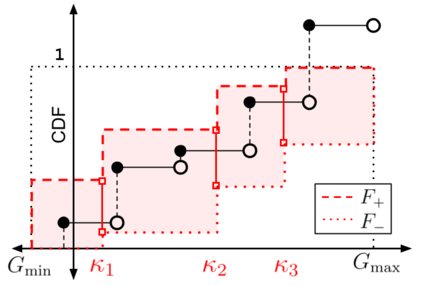
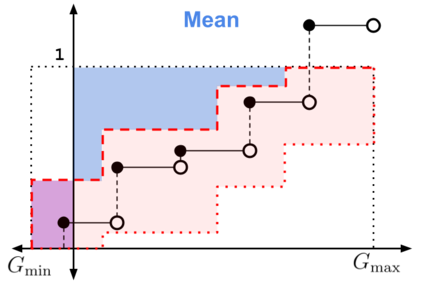
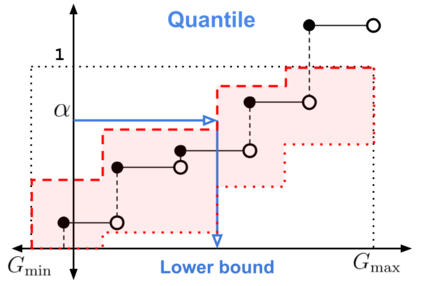
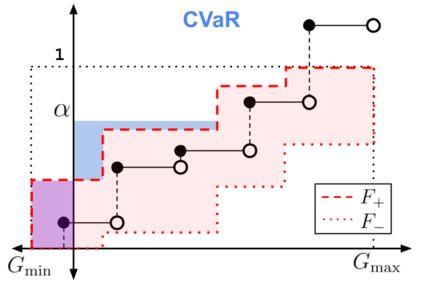
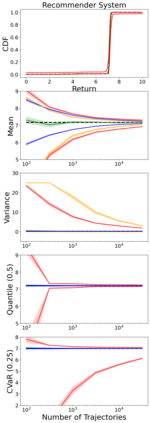
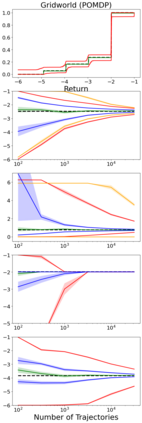
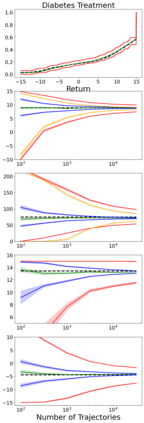
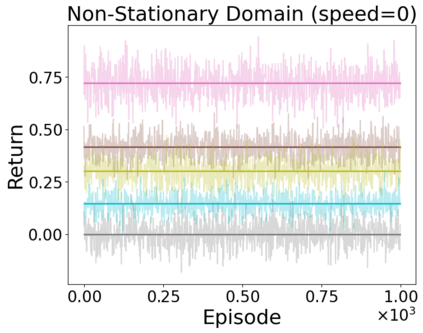
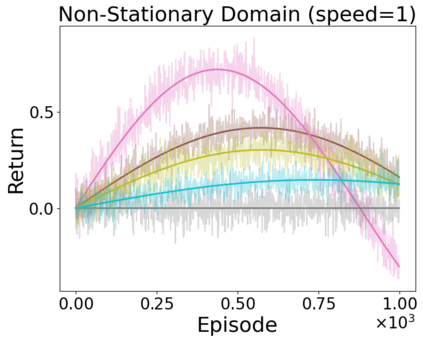
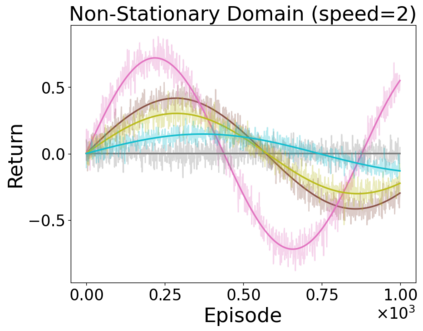
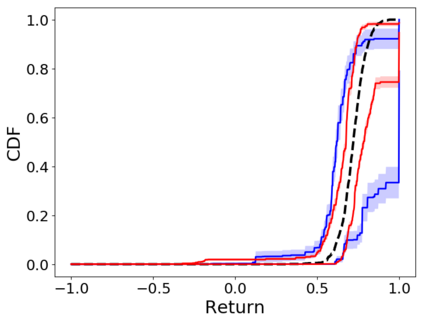
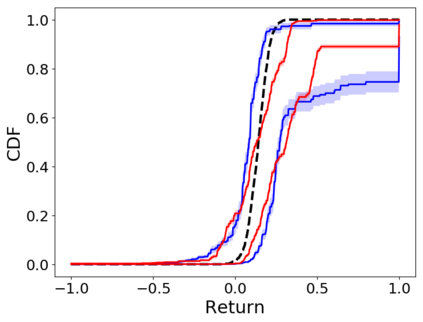
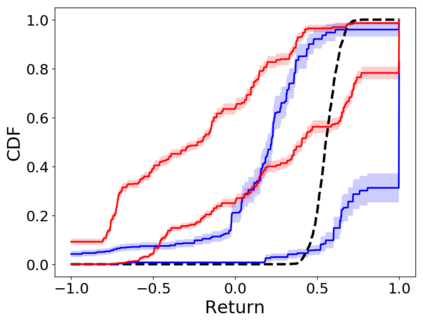
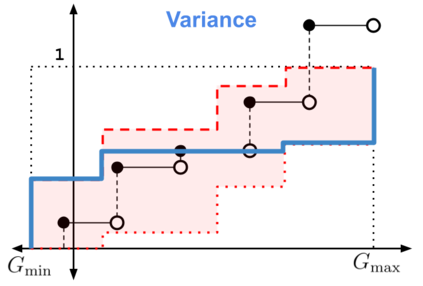
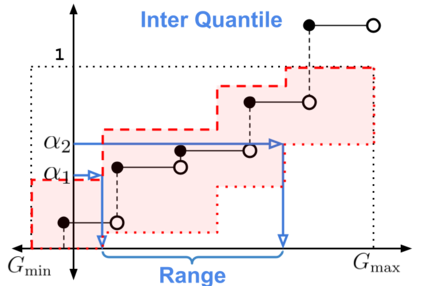
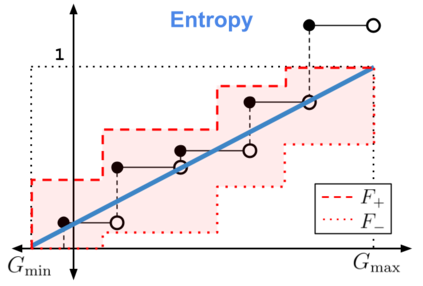
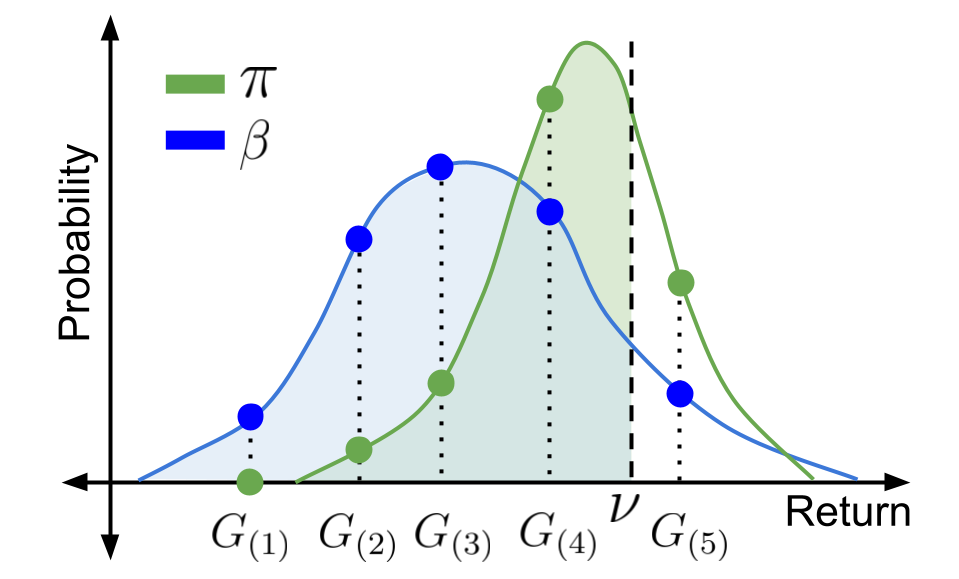
When faced with sequential decision-making problems, it is often useful to be able to predict what would happen if decisions were made using a new policy. Those predictions must often be based on data collected under some previously used decision-making rule. Many previous methods enable such off-policy (or counterfactual) estimation of the expected value of a performance measure called the return. In this paper, we take the first steps towards a universal off-policy estimator (UnO) -- one that provides off-policy estimates and high-confidence bounds for any parameter of the return distribution. We use UnO for estimating and simultaneously bounding the mean, variance, quantiles/median, inter-quantile range, CVaR, and the entire cumulative distribution of returns. Finally, we also discuss Uno's applicability in various settings, including fully observable, partially observable (i.e., with unobserved confounders), Markovian, non-Markovian, stationary, smoothly non-stationary, and discrete distribution shifts.
翻译:在面临一系列决策问题时,如果使用新的政策作出决定,预测会发生什么情况往往是有益的。这些预测往往必须基于根据以前使用的一些决策规则收集的数据。许多以前的方法使得能够对称为返回的业绩计量的预期价值进行这种非政策性(或反事实性)估计。在本文件中,我们迈出第一步,争取建立一个普遍的非政策性估计符(UNO) -- -- 一个为返回分布的任何参数提供非政策性估计和高度信心界限。我们使用UNO来估计和同时约束平均值、差异、定量/中间值、量间分布、CVaR和整个累积的回报分布。最后,我们还讨论了Uno在各种环境中的适用性,包括完全可观察、部分可观察(即有未观察的征服者)、Markovian、非马尔科维安、固定性、平稳的非静止性、分散性分布变化。