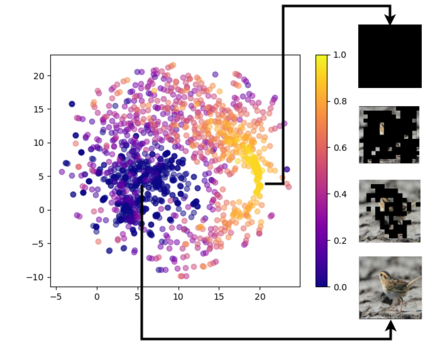
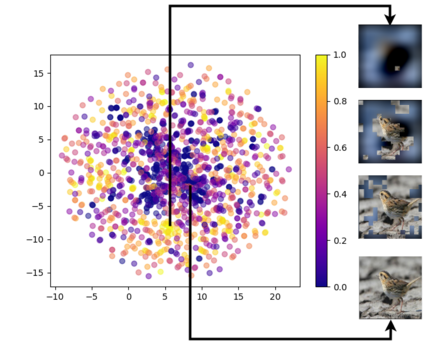
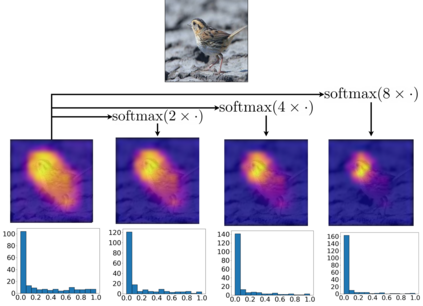
Due to the black-box nature of deep learning models, there is a recent development of solutions for visual explanations of CNNs. Given the high cost of user studies, metrics are necessary to compare and evaluate these different methods. In this paper, we critically analyze the Deletion Area Under Curve (DAUC) and Insertion Area Under Curve (IAUC) metrics proposed by Petsiuk et al. (2018). These metrics were designed to evaluate the faithfulness of saliency maps generated by generic methods such as Grad-CAM or RISE. First, we show that the actual saliency score values given by the saliency map are ignored as only the ranking of the scores is taken into account. This shows that these metrics are insufficient by themselves, as the visual appearance of a saliency map can change significantly without the ranking of the scores being modified. Secondly, we argue that during the computation of DAUC and IAUC, the model is presented with images that are out of the training distribution which might lead to an unreliable behavior of the model being explained. To complement DAUC/IAUC, we propose new metrics that quantify the sparsity and the calibration of explanation methods, two previously unstudied properties. Finally, we give general remarks about the metrics studied in this paper and discuss how to evaluate them in a user study.
翻译:由于深层学习模式的黑箱性质,最近出现了对有线电视新闻网进行直观解释的解决方案。鉴于用户研究费用高昂,有必要制定衡量尺度来比较和评价这些不同方法。在本文中,我们严格分析Petsiuk等人(2018年)建议的曲线下去入区和曲线下插入区(IAUC)衡量尺度。这些衡量尺度旨在评价诸如Grad-CAM或RISE等通用方法生成的突出地图的准确性。首先,我们表明,由于只考虑分数的排名,突出地图给出的实际显著分数值被忽略。这说明,这些衡量尺度本身是不够的,因为突出地图的视觉外观在不修改分数的排名的情况下可以发生重大变化。第二,我们争辩说,在计算DAUC和IAUC等通用方法时,模型所展示的图像在培训分布中可能会导致模型不可靠的行为。为了补充DAUC/IAUC,我们提出了新的衡量尺度,以量化这些分数,我们在以往研究的纸质分析中如何解释这些数值和校准方法。