
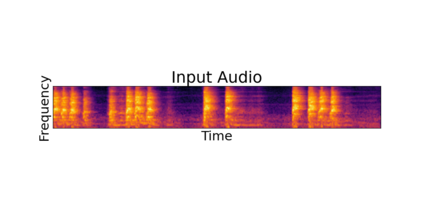
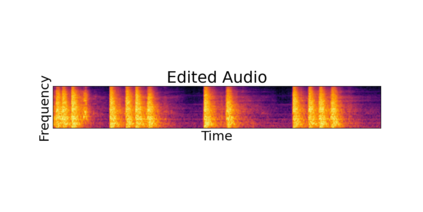
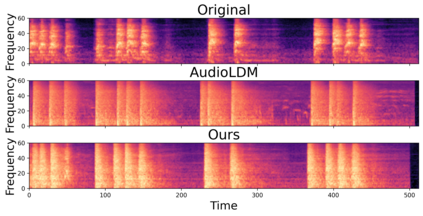
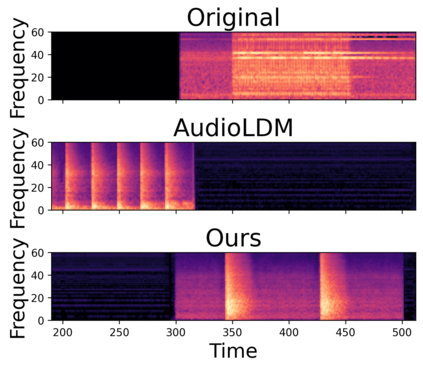
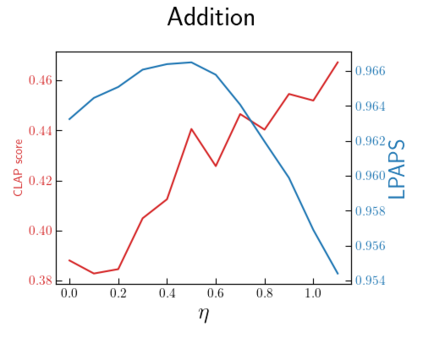
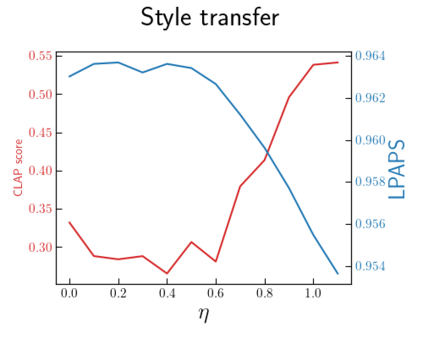
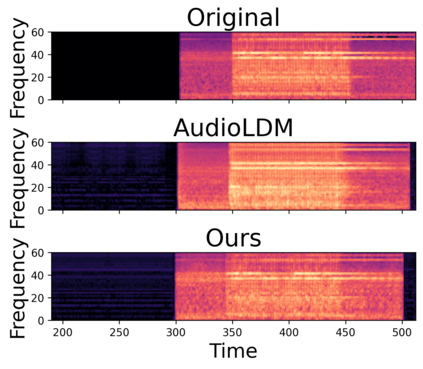
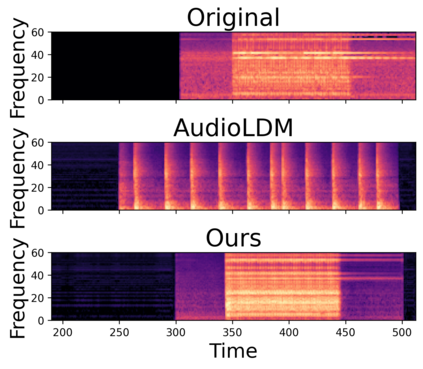
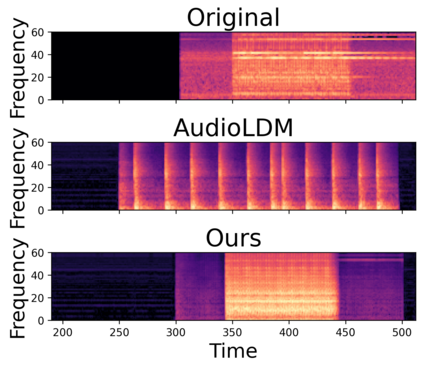
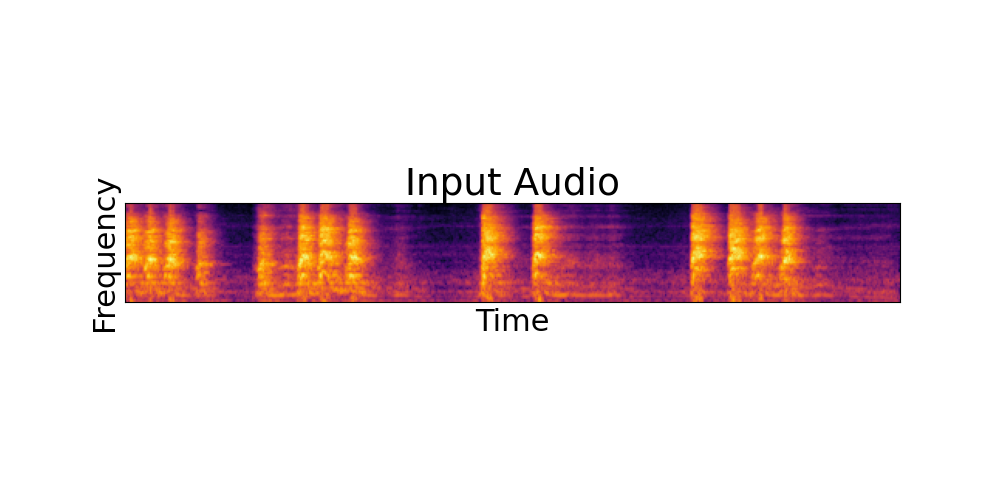
In this paper, we explore audio-editing with non-rigid text edits. We show that the proposed editing pipeline is able to create audio edits that remain faithful to the input audio. We explore text prompts that perform addition, style transfer, and in-painting. We quantitatively and qualitatively show that the edits are able to obtain results which outperform Audio-LDM, a recently released text-prompted audio generation model. Qualitative inspection of the results points out that the edits given by our approach remain more faithful to the input audio in terms of keeping the original onsets and offsets of the audio events.
翻译:暂无翻译



相关内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2023年12月4日


相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2023年12月4日