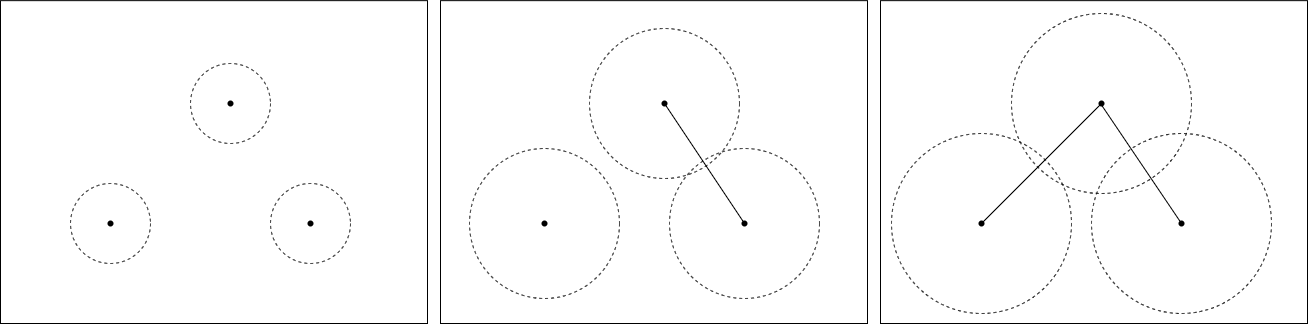
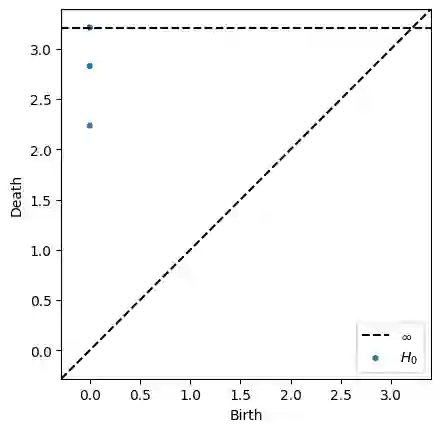
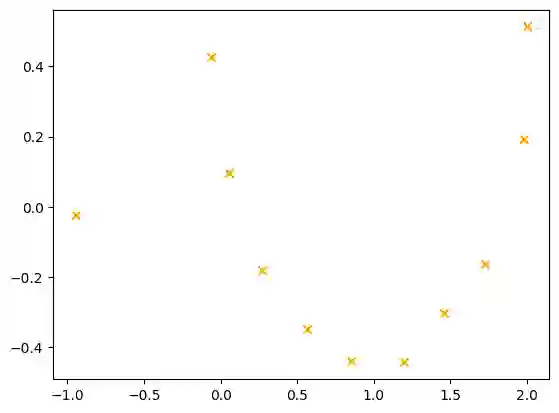
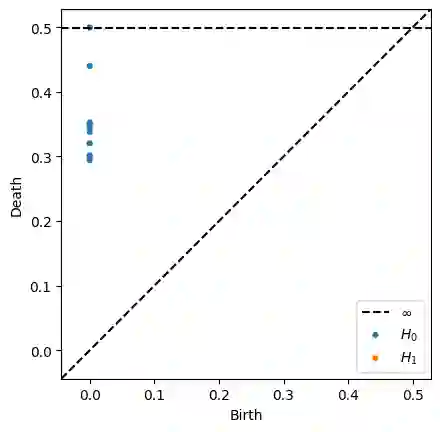
Nowadays, Machine Learning and Deep Learning methods have become the state-of-the-art approach to solve data classification tasks. In order to use those methods, it is necessary to acquire and label a considerable amount of data; however, this is not straightforward in some fields, since data annotation is time consuming and might require expert knowledge. This challenge can be tackled by means of semi-supervised learning methods that take advantage of both labelled and unlabelled data. In this work, we present new semi-supervised learning methods based on techniques from Topological Data Analysis (TDA), a field that is gaining importance for analysing large amounts of data with high variety and dimensionality. In particular, we have created two semi-supervised learning methods following two different topological approaches. In the former, we have used a homological approach that consists in studying the persistence diagrams associated with the data using the Bottleneck and Wasserstein distances. In the latter, we have taken into account the connectivity of the data. In addition, we have carried out a thorough analysis of the developed methods using 3 synthetic datasets, 5 structured datasets, and 2 datasets of images. The results show that the semi-supervised methods developed in this work outperform both the results obtained with models trained with only manually labelled data, and those obtained with classical semi-supervised learning methods, reaching improvements of up to a 16%.
翻译:目前,机器学习和深层学习方法已成为解决数据分类任务的最先进方法。为了使用这些方法,有必要获取和标出大量数据;然而,在某些领域,这并非直截了当,因为数据批注耗时,可能需要专家知识。这一挑战可以通过半监督的学习方法来应对,利用标签和无标签数据。在这项工作中,我们根据地形数据分析技术(ATA)提出了新的半监督的学习方法。这个领域对于分析大量种类和多面性的数据越来越重要。特别是,我们根据两种不同的表层学方法创建了两种半监督的学习方法。在前者,我们采用了一种同质方法,即通过使用标签和无标签的数据来研究与数据相关的持久性图表。在后者,我们考虑了数据的连接性。此外,我们利用3个合成数据集、5个结构化数据集和多面性数据分析,对开发的先进方法进行了彻底分析。我们采用了两种半监督的学习方法,其中一种是经过培训的模型,两种是用经过测试的模型的16个结果。我们只用经过了16个分析的模型,用这些模型和2个得到的半结构化的模型来显示。