
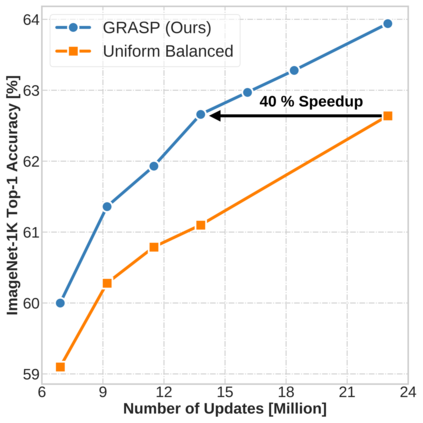
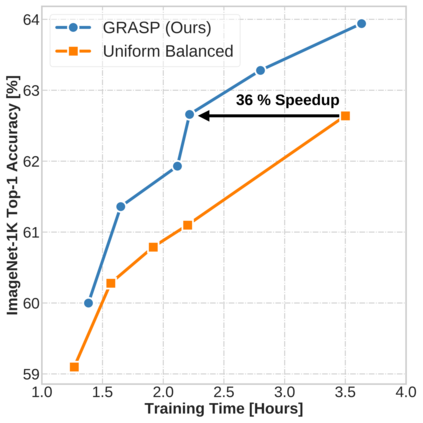
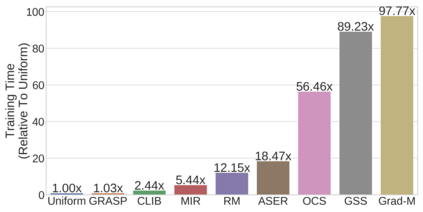
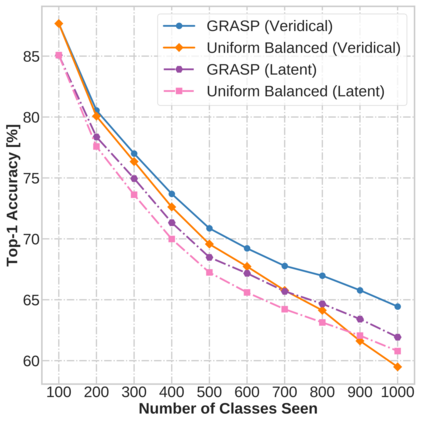
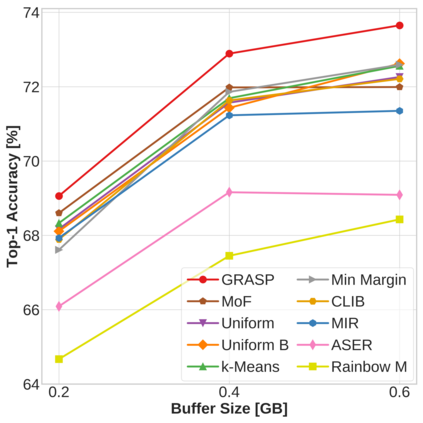
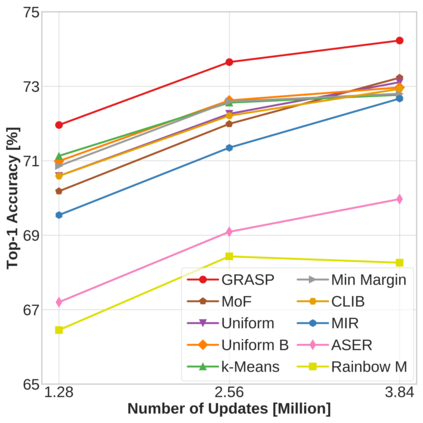
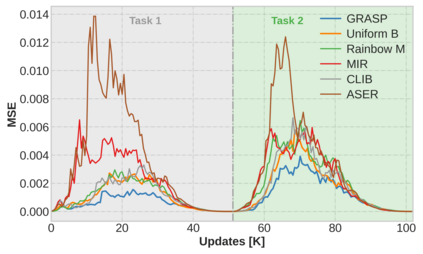
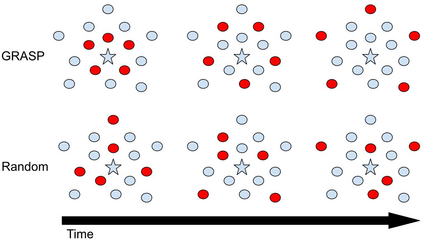
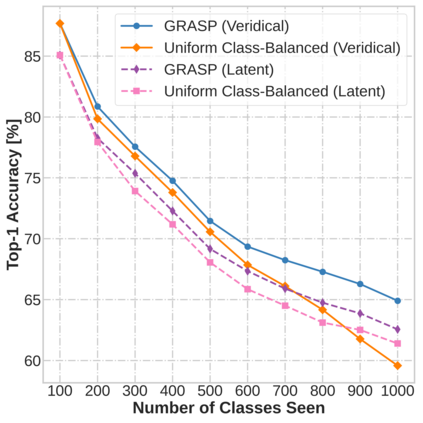
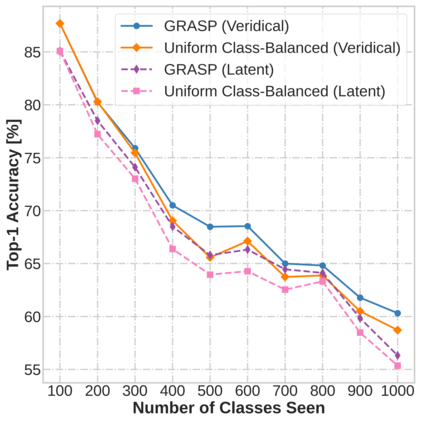
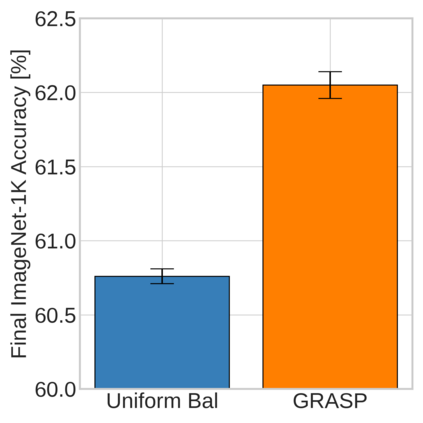
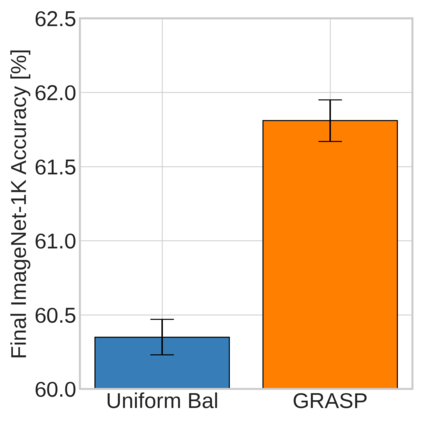
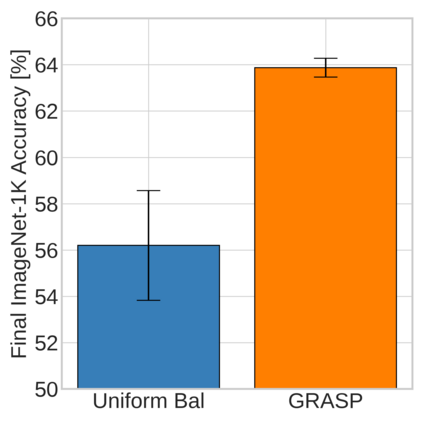
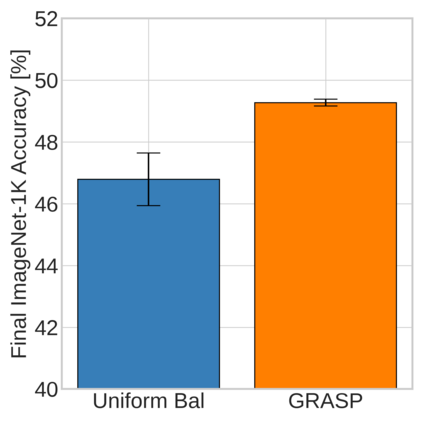
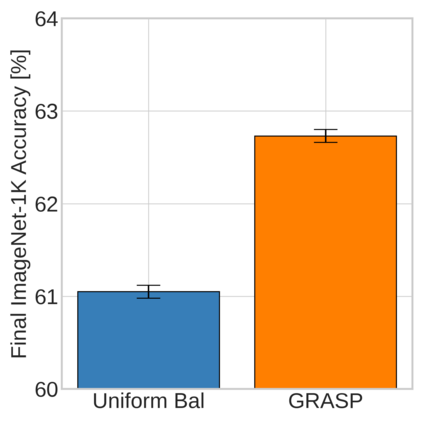
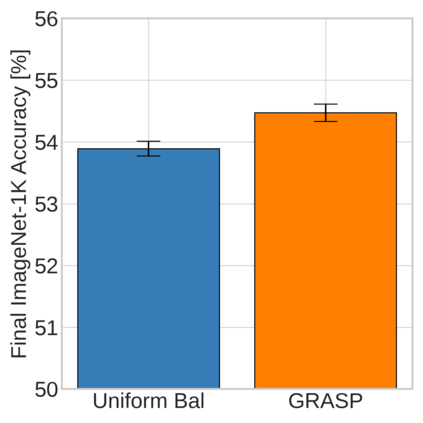
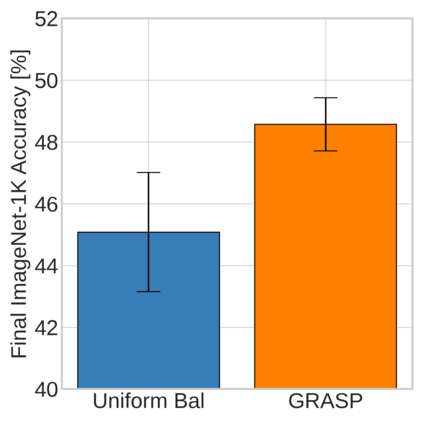
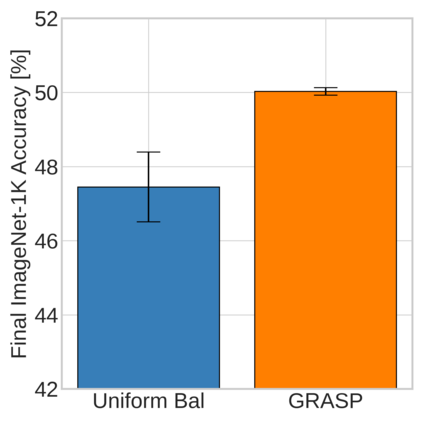
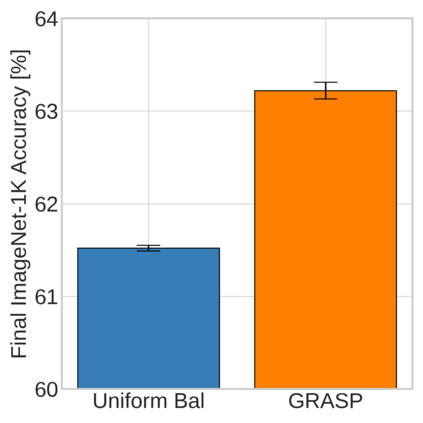
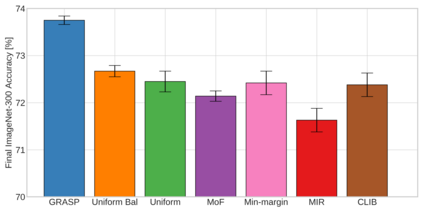
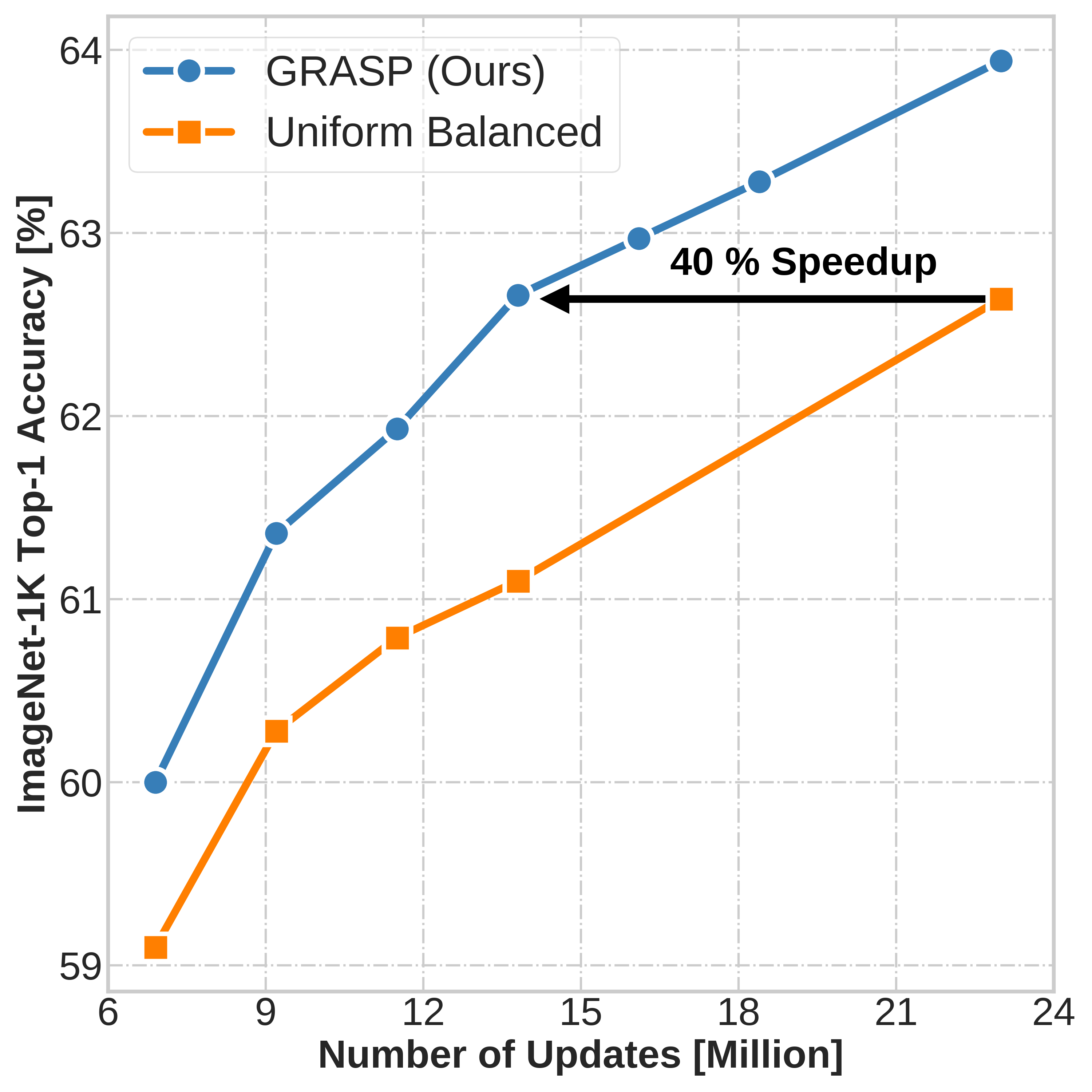
Continual learning (CL) in deep neural networks (DNNs) involves incrementally accumulating knowledge in a DNN from a growing data stream. A major challenge in CL is that non-stationary data streams cause catastrophic forgetting of previously learned abilities. A popular solution is rehearsal: storing past observations in a buffer and then sampling the buffer to update the DNN. Uniform sampling in a class-balanced manner is highly effective, and better sample selection policies have been elusive. Here, we propose a new sample selection policy called GRASP that selects the most prototypical (easy) samples first and then gradually selects less prototypical (harder) examples. GRASP has little additional compute or memory overhead compared to uniform selection, enabling it to scale to large datasets. Compared to 17 other rehearsal policies, GRASP achieves higher accuracy in CL experiments on ImageNet. Compared to uniform balanced sampling, GRASP achieves the same performance with 40% fewer updates. We also show that GRASP is effective for CL on five text classification datasets.
翻译:暂无翻译
相关内容

Source: Apple - iOS 8

