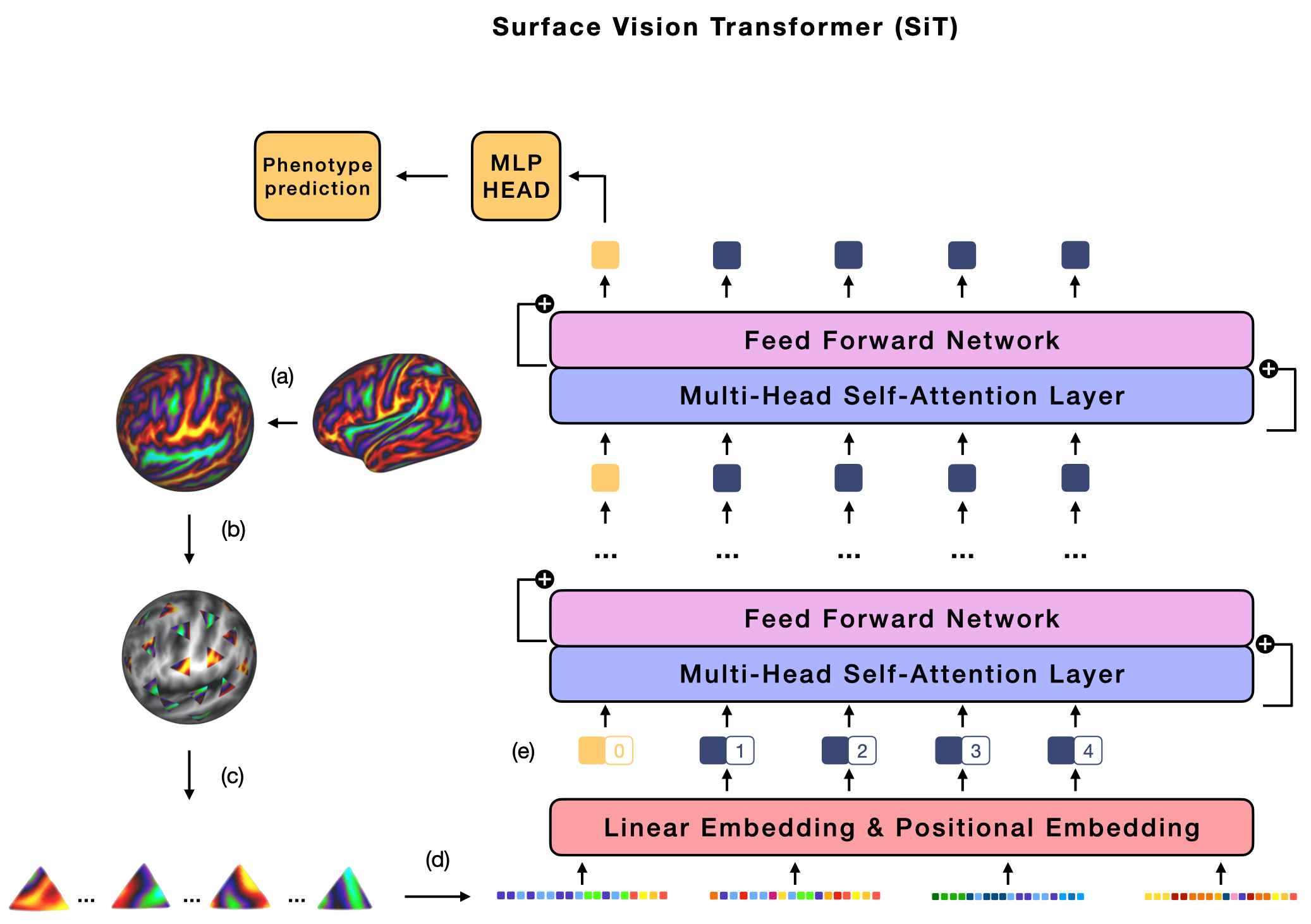
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Recent state-of-the-art performance of Vision Transformers (ViTs) demonstrates that a general-purpose architecture, which implements self-attention, could replace the local feature learning operations of CNNs. Motivated by the success of attention-modelling in computer vision, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence problem and propose a patching mechanism for surface meshes. We validate the performance of the proposed Surface Vision Transformer (SiT) on two brain age prediction tasks in the developing Human Connectome Project (dHCP) dataset and investigate the impact of pre-training on model performance. Experiments show that the SiT outperforms many surface CNNs, while indicating some evidence of general transformation invariance. Code available at https://github.com/metrics-lab/surface-vision-transformers
翻译:进化神经网络(CNNs)扩展到非欧洲的地貌外观已经导致多个研究多元体的框架,其中许多方法都显示出设计上的局限性,导致长距离联系模型的建模不完善,因为向非正常表面的演化是非三角的。视觉变异器(VITs)最近的最先进的性能显示,采用自我注意的通用结构可以取代CNN的本地特征学习操作。受计算机视觉关注建模成功激励,我们通过重塑表层学习任务作为顺序到顺序问题,将VIT扩大到表面,并提出表面模具的补补补机制。我们验证了拟议的地面视觉变异器(SiT)在开发人类连接项目(dHCP)数据组的两个大脑年龄预测任务上的性能,并调查培训前训练对模型性能的影响。实验显示,SiT超越了许多表面CNN,同时显示一些一般视野变换/表面变形的证据。我们在 http://httpsurvical-tariblas-stroductions。