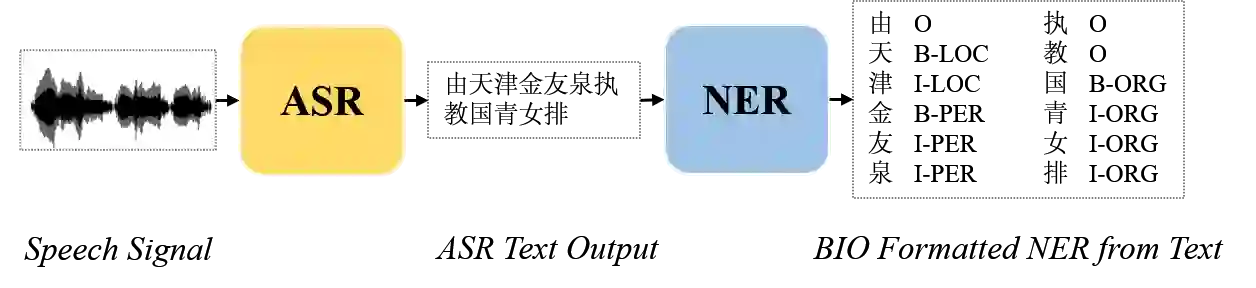
Named Entity Recognition (NER) from speech is among Spoken Language Understanding (SLU) tasks, aiming to extract semantic information from the speech signal. NER from speech is usually made through a two-step pipeline that consists of (1) processing the audio using an Automatic Speech Recognition (ASR) system and (2) applying an NER tagger to the ASR outputs. Recent works have shown the capability of the End-to-End (E2E) approach for NER from English and French speech, which is essentially entity-aware ASR. However, due to the many homophones and polyphones that exist in Chinese, NER from Chinese speech is effectively a more challenging task. In this paper, we introduce a new dataset AISEHLL-NER for NER from Chinese speech. Extensive experiments are conducted to explore the performance of several state-of-the-art methods. The results demonstrate that the performance could be improved by combining entity-aware ASR and pretrained NER tagger, which can be easily applied to the modern SLU pipeline. The dataset is publicly available at github.com/Alibaba-NLP/AISHELL-NER.
翻译:从演讲中命名实体识别(NER)是语言理解(SLU)的一项任务,目的是从语音信号中提取语义信息。语言识别(NER)通常通过两步管道完成,其中包括:(1) 使用自动语音识别(ASR)系统处理音频,(2) 对ASR产出应用NER制动器。最近的工作表明,从英语到法语演讲(E2E)对NER采用端到端(E2E)的方法的能力,这基本上是实体认知的ASR。然而,由于中文中文本中有许多同音和多部电话,因此,中文发言中文本中的NER实际上是一项更具挑战性的任务。在本文中,我们为中国演讲中文本中的NER引入了一个新的数据集AISEHLL-NER。进行了广泛的实验,以探索若干最新方法的性能。结果显示,通过将实体认知的ASR和预先培训的NERTger相结合,可以改进工作,这可以很容易地应用于现代SLU管道。数据设置在Githhub.com/Alib-Aliba-LA.NLA.NA.A.N.NA.N.ARIaba-LA.LA.LA.N.A.N.N.L.L.A.L.L.A.AG.AG.L.A.L.L.L.L.L.AG.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.L.L.L.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.L.L.A.L.L.A.L.A.A.A.L.L.A.A.L.L.L.A.A.A.A.A.A.A.A.L.L.A.A.A.A.A.A.A.A.L.L.L.L.L.L.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.A.L.L.