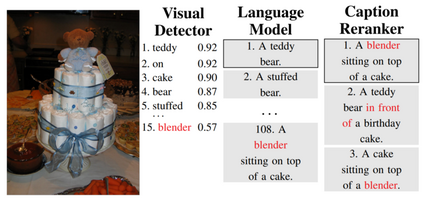
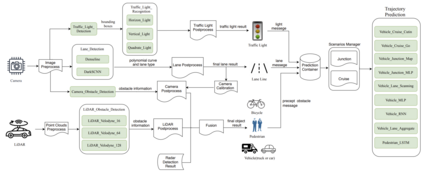
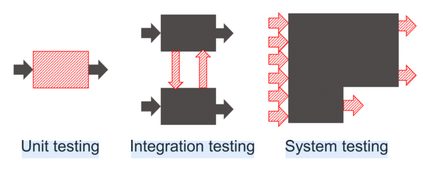
The lack of specifications is a key difference between traditional software engineering and machine learning. We discuss how it drastically impacts how we think about divide-and-conquer approaches to system design, and how it impacts reuse, testing and debugging activities. Traditionally, specifications provide a cornerstone for compositional reasoning and for the divide-and-conquer strategy of how we build large and complex systems from components, but those are hard to come by for machine-learned components. While the lack of specification seems like a fundamental new problem at first sight, in fact software engineers routinely deal with iffy specifications in practice: we face weak specifications, wrong specifications, and unanticipated interactions among components and their specifications. Machine learning may push us further, but the problems are not fundamentally new. Rethinking machine-learning model composition from the perspective of the feature interaction problem, we may even teach us a thing or two on how to move forward, including the importance of integration testing, of requirements engineering, and of design.
翻译:缺乏规格是传统软件工程和机器学习之间的一个关键区别。 我们讨论它如何极大地影响我们对系统设计分而治之方法的思考,以及如何影响再利用、测试和调试活动。 传统上,规格提供了组成推理和分而治之战略的基石,即我们如何从部件中构建大型和复杂系统,但对于机器学习组件来说很难找到这些系统。 缺乏规格似乎是初见即是根本性的新问题,而事实上软件工程师经常在实际操作中处理简易规格:我们面对规格薄弱、规格错误、各部件及其规格之间意外的相互作用。 机器学习可能进一步推动我们,但问题并不是根本上的新问题。 从特征互动问题的角度重新思考机器学习模型的构成,我们甚至可以教导我们如何前进,包括一体化测试、要求工程和设计的重要性。