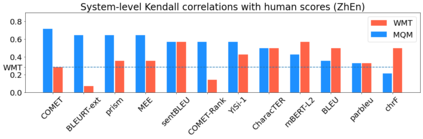
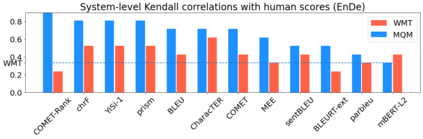
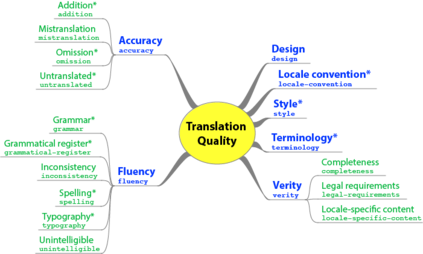
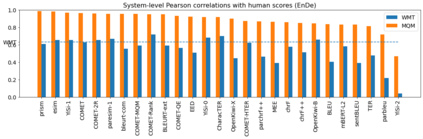
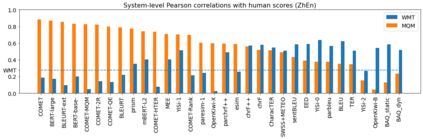
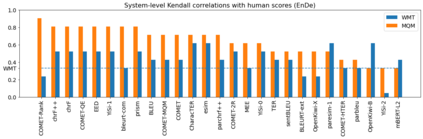
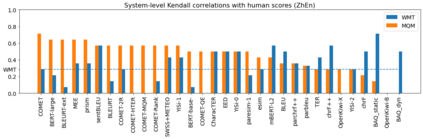
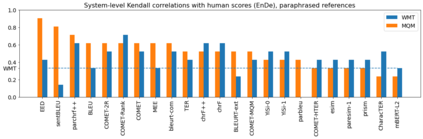
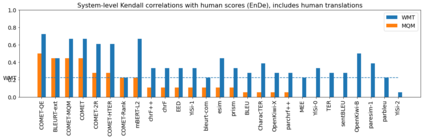
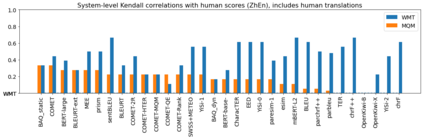
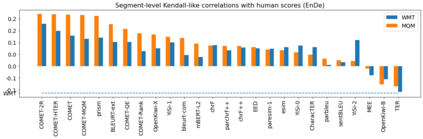
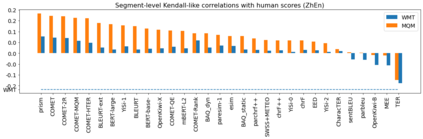
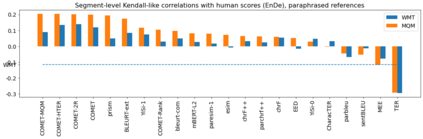
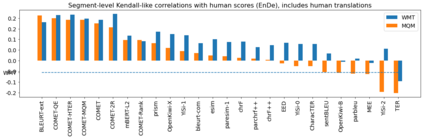
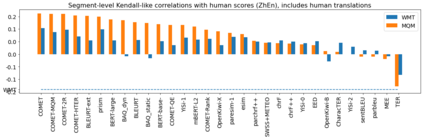
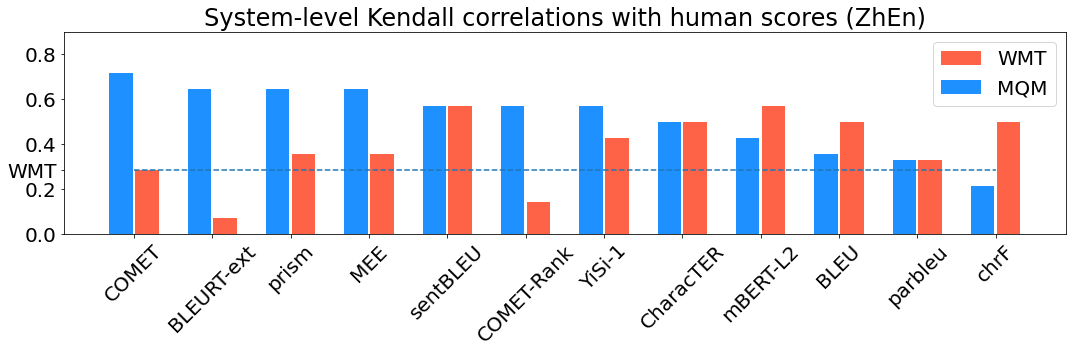
Human evaluation of modern high-quality machine translation systems is a difficult problem, and there is increasing evidence that inadequate evaluation procedures can lead to erroneous conclusions. While there has been considerable research on human evaluation, the field still lacks a commonly-accepted standard procedure. As a step toward this goal, we propose an evaluation methodology grounded in explicit error analysis, based on the Multidimensional Quality Metrics (MQM) framework. We carry out the largest MQM research study to date, scoring the outputs of top systems from the WMT 2020 shared task in two language pairs using annotations provided by professional translators with access to full document context. We analyze the resulting data extensively, finding among other results a substantially different ranking of evaluated systems from the one established by the WMT crowd workers, exhibiting a clear preference for human over machine output. Surprisingly, we also find that automatic metrics based on pre-trained embeddings can outperform human crowd workers. We make our corpus publicly available for further research.
翻译:对现代高质量机器翻译系统进行人类评价是一个棘手的问题,越来越多的证据表明,评价程序不足可能导致错误的结论。虽然对人的评价进行了大量研究,但该领域仍缺乏普遍接受的标准程序。作为实现这一目标的一个步骤,我们根据多层面高质量计量(MQM)框架,提出了一个基于明确错误分析的评价方法。我们进行了迄今为止最大的MQM研究,利用专业笔译员提供的全面文件背景说明,用两种语文对WMT 2020 顶级系统的产出进行评分,用两种语文分担任务。我们广泛分析了由此产生的数据,除其他结果外,我们发现所评价的系统与WMT人群工人建立的系统有显著差异,明显偏重于人类而不是机器产出。令人惊讶的是,我们还发现基于预先训练的嵌入的自动测量仪能够超越人类人群工人。我们公开提供我们的软件,以供进一步研究。