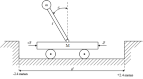
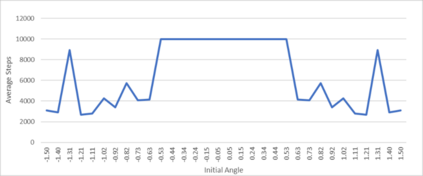
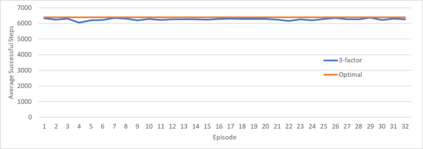
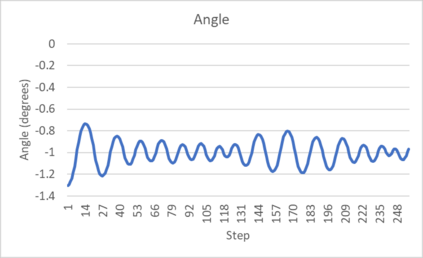
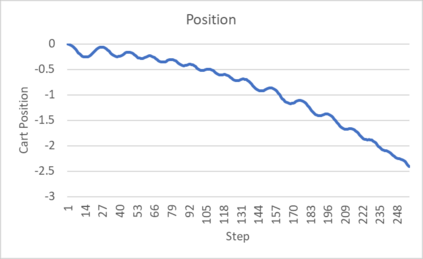
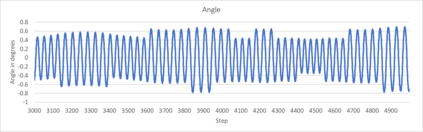
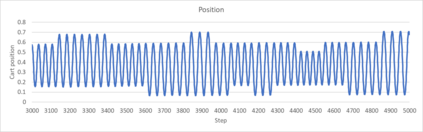
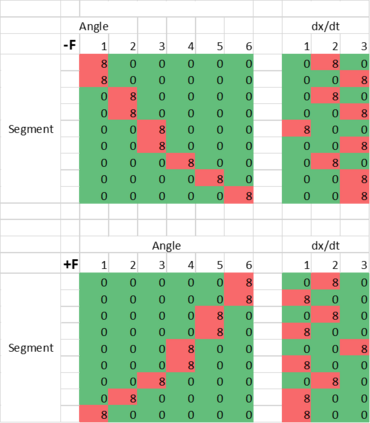
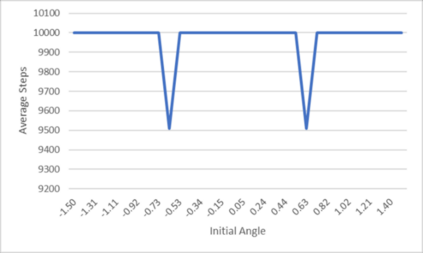
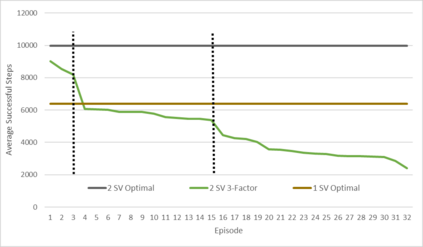
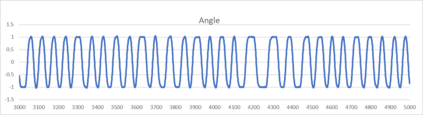
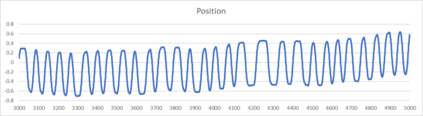
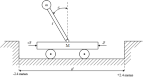
An agent employing reinforcement learning takes inputs (state variables) from an environment and performs actions that affect the environment in order to achieve some objective. Rewards (positive or negative) guide the agent toward improved future actions. This paper builds on prior clustering neural network research by constructing an agent with biologically plausible neo-Hebbian three-factor synaptic learning rules, with a reward signal as the third factor (in addition to pre- and post-synaptic spikes). The classic cart-pole problem (balancing an inverted pendulum) is used as a running example throughout the exposition. Simulation results demonstrate the efficacy of the approach, and the proposed method may eventually serve as a low-level component of a more general method.
翻译:暂无翻译