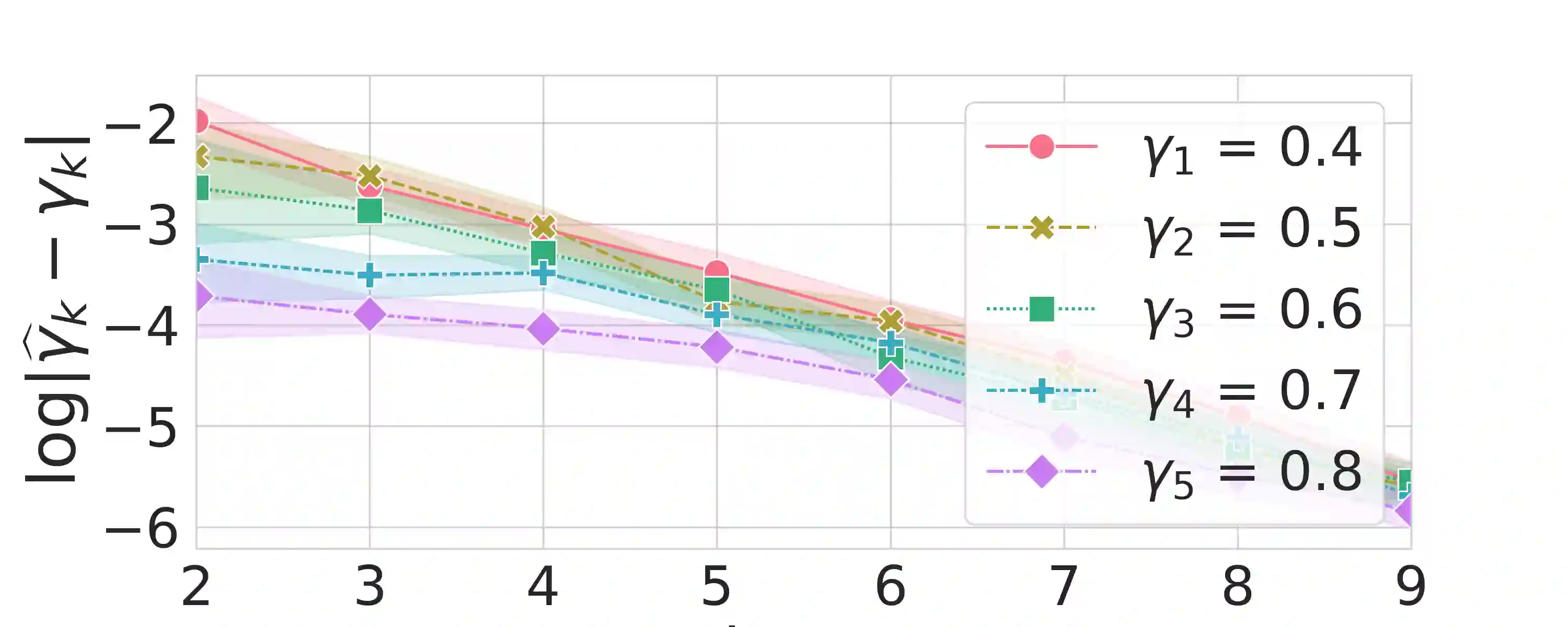
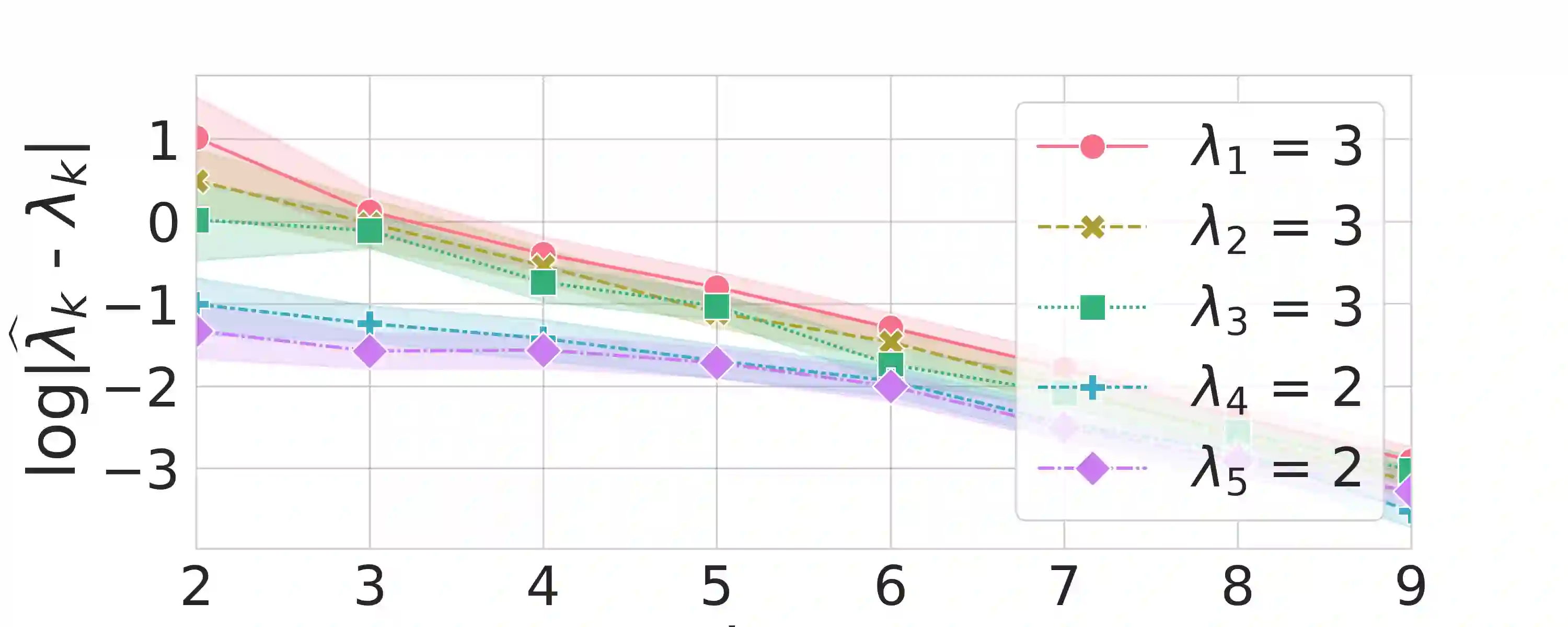
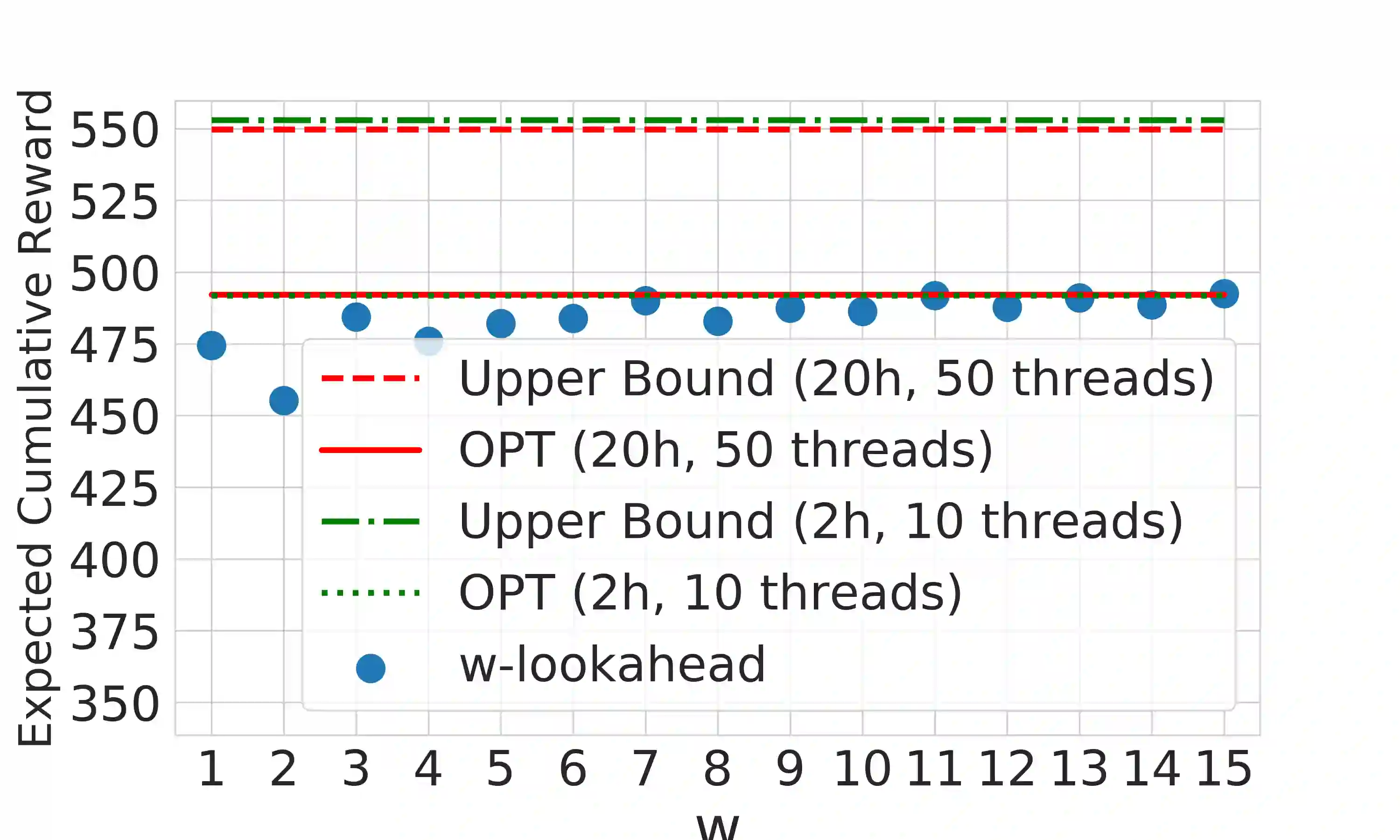
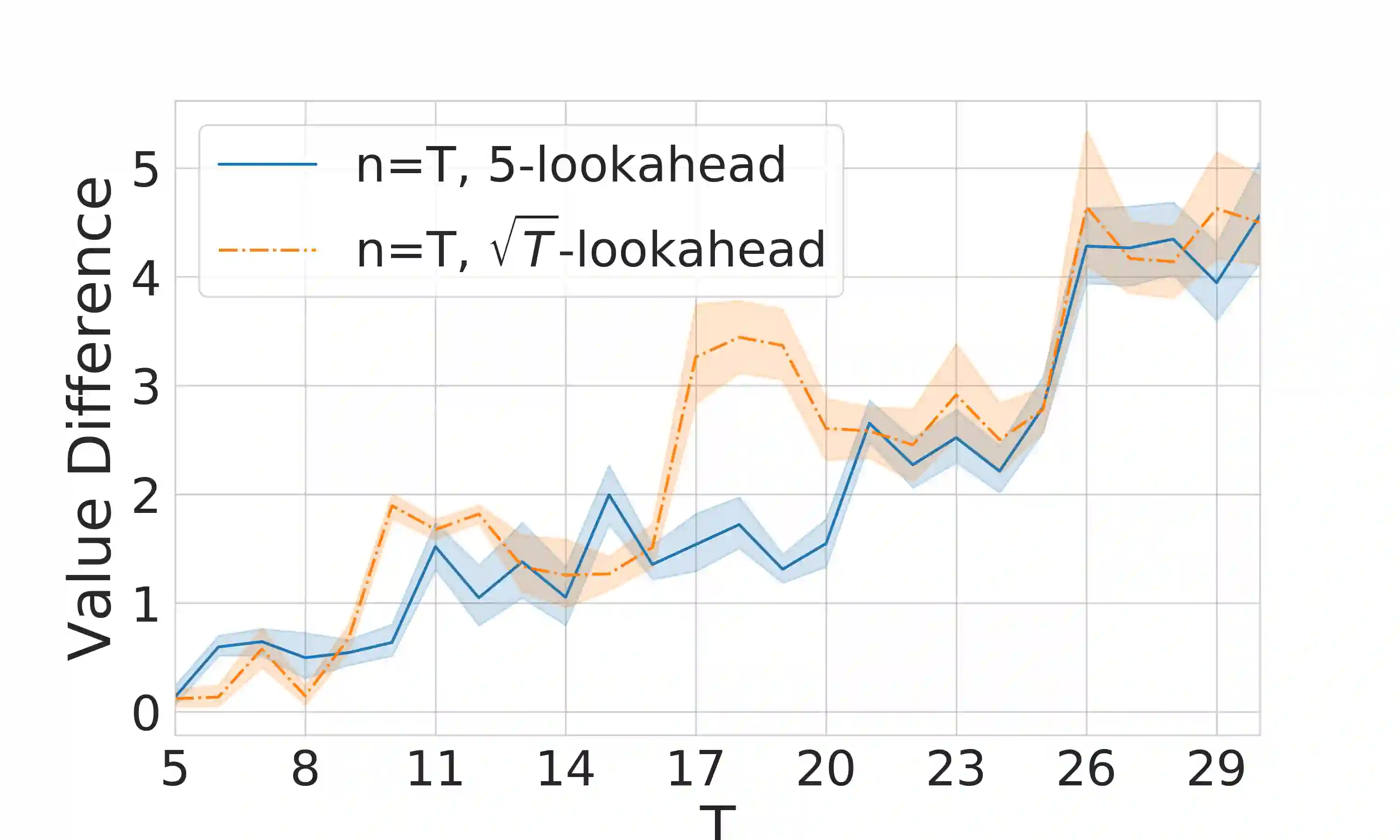
A large body of psychological research shows that enjoyment of many goods is subject to satiation, with short-term satisfaction declining after repeated exposures to the same item. Nevertheless, proposed algorithms for powering recommender systems seldom model these dynamics, instead proceeding as though user preferences were fixed in time. In this work, we adopt a multi-armed bandit setup, modeling satiation dynamics as a time-invariant linear dynamical system. In our model, the expected rewards for each arm decline monotonically with consecutive exposures to the same item and rebound towards the initial reward whenever that arm is not pulled. We analyze this model, showing that when the arms exhibit identical deterministic dynamics, our problem is equivalent to a specific instance of Max K-Cut. In this case, a greedy policy, which plays the arms in a cyclic order, is optimal. To handle the case when the parameters governing the satiation dynamics can vary across arms, we propose a lookahead policy that generalizes the greedy policy. When the satiation dynamics are stochastic and governed by different (unknown) parameters, we propose an algorithm that first uses offline data to identify an affine dynamical system specified by the reward model and then plans using the lookahead policy.
翻译:大量的心理研究显示,许多商品的享受都需满足,在反复接触同一物品后,短期满意度下降。然而,为建议者系统提供动力的拟议算法很少模拟这些动态,而很少模拟这些动态,相反,似乎用户的偏好是固定的。在这项工作中,我们采用了多臂强盗设置,将饱和动态建模作为一种时间变化的线性动态系统。在我们的模式中,每只手臂的预期奖励单向地下降,连续接触同一物品,并在不拉动手臂时反弹到最初的奖励。我们分析这一模型,表明当武器表现出相同的确定性动态时,我们的问题就相当于Max K-Cut的具体实例。在这种情况下,我们采用一种贪婪政策,在周期性秩序中玩弄武器,是最佳的。当调制满足性动态参数在不同臂之间变化时,我们建议一种直观政策政策。当满足性动态动态动态动态动态动态动态动态动态动态动态发生时,由不同的(已知的)参数来调整(未知的),我们提出一种算法,然后用一种离动政策系统来确定一个反动性的政策。