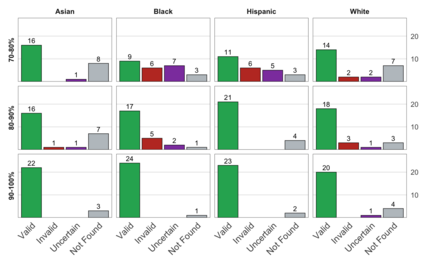
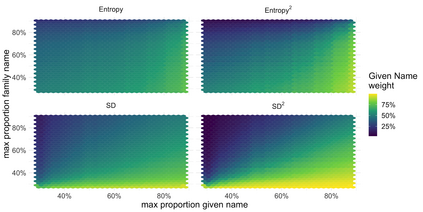
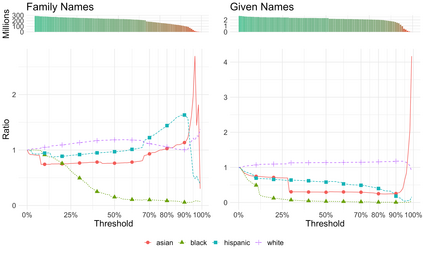
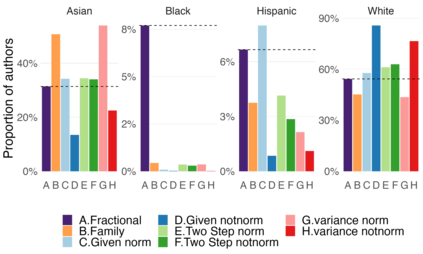
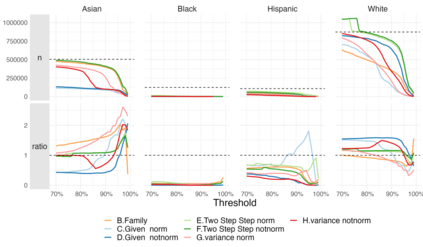
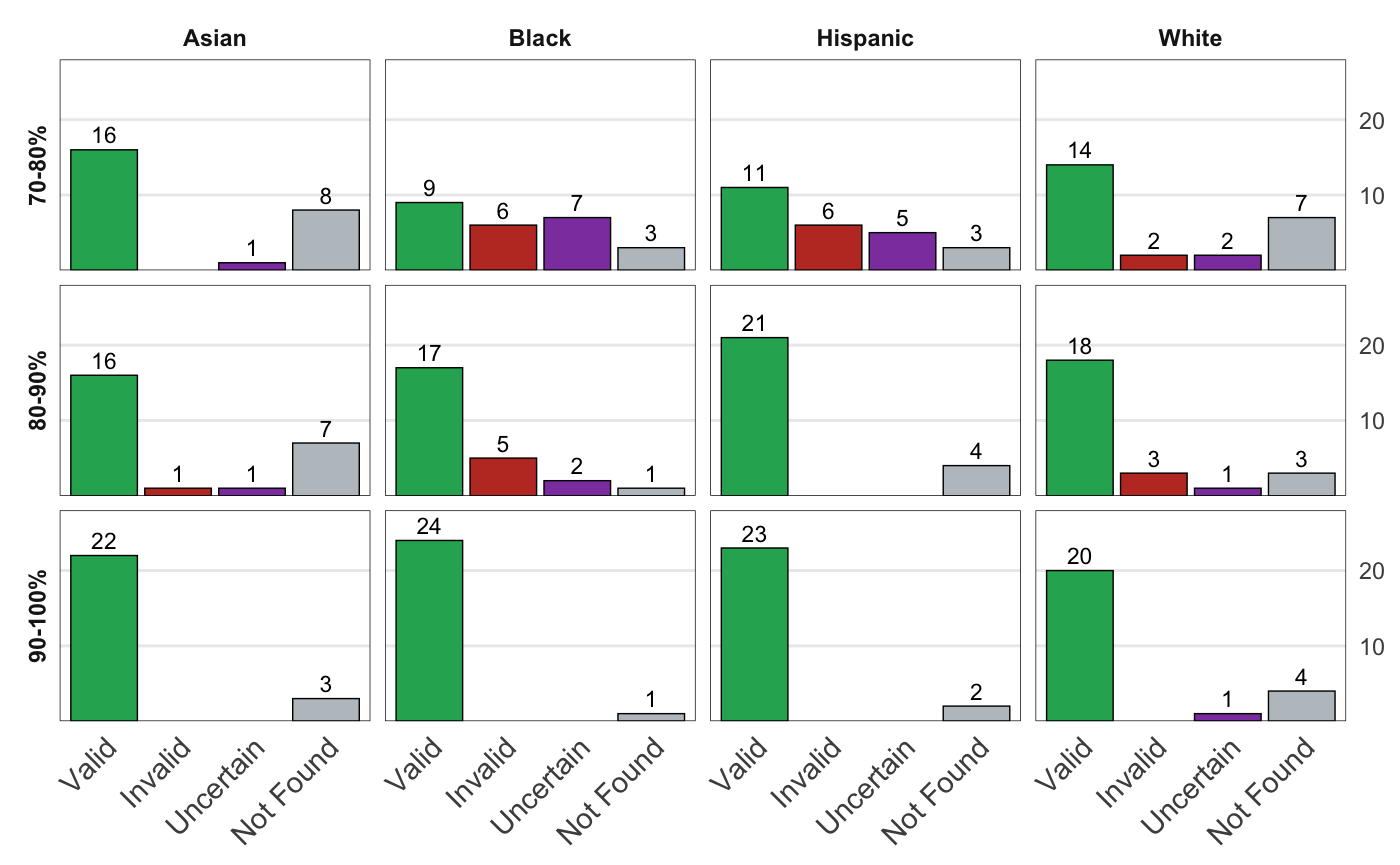
Racial disparity in academia is a widely acknowledged problem. The quantitative understanding of racial based systemic inequalities is an important step towards a more equitable research system. However, because of the lack of robust information on authors' race, few large scale analyses have been performed on this topic. Algorithmic approaches offer one solution, using known information about authors, such as their names, to infer their perceived race. As with any other algorithm, the process of racial inference can generate biases if it is not carefully considered. The goal of this article is to assess the extent to which algorithmic bias is introduced using different approaches for name based racial inference. We use information from the U.S. Census and mortgage applications to infer the race of U.S. affiliated authors in the Web of Science. We estimate the effects of using given and family names, thresholds or continuous distributions, and imputation. Our results demonstrate that the validity of name based inference varies by race/ethnicity and that threshold approaches underestimate Black authors and overestimate White authors. We conclude with recommendations to avoid potential biases. This article lays the foundation for more systematic and less biased investigations into racial disparities in science.
翻译:学术界的种族差异是一个广泛公认的问题。对基于种族的系统性种族不平等的定量理解是迈向更公平研究制度的一个重要步骤。然而,由于缺乏关于作者种族的可靠信息,因此,很少对这一专题进行大规模分析。分析方法提供了一种解决办法,利用关于作者的已知信息,例如他们的姓名,推断他们认为的种族。与任何其他算法一样,种族推论过程如果不仔细考虑,就会产生偏见。本文章的目的是评估算法偏见在多大程度上采用不同方法来进行基于种族的推论。我们利用美国人口普查和抵押申请中的信息来推断科学网中的美国附属作者的种族。我们估计了使用特定名称和家族名称、阈值或连续分布以及估算的影响。我们的结果表明,基于名称推论的有效性因种族/族裔特征而不同,而且这一阈值会低估黑人作者和高估白人作者。我们最后提出了避免潜在偏见的建议。这一文章为更系统和较少偏差地调查科学中的种族差距奠定了基础。