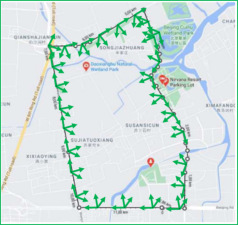
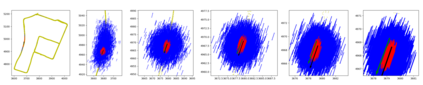
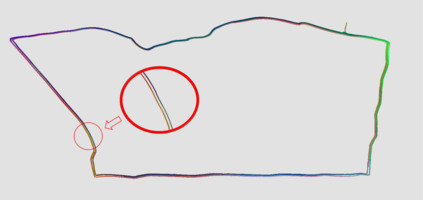
We propose a novel learning-based formulation for camera pose estimation that can perform relocalization accurately and in real-time in city-scale environments. Camera pose estimation algorithms determine the position and orientation from which an image has been captured, using a set of geo-referenced images or 3D scene representation. Our new localization paradigm, named Implicit Pose Encoding (ImPosing), embeds images and camera poses into a common latent representation with 2 separate neural networks, such that we can compute a similarity score for each image-pose pair. By evaluating candidates through the latent space in a hierarchical manner, the camera position and orientation are not directly regressed but incrementally refined. Compared to the representation used in structure-based relocalization methods, our implicit map is memory bounded and can be properly explored to improve localization performances against learning-based regression approaches. In this paper, we describe how to effectively optimize our learned modules, how to combine them to achieve real-time localization, and demonstrate results on diverse large scale scenarios that significantly outperform prior work in accuracy and computational efficiency.
翻译:我们建议为照相机设计一种新型的基于学习的配方,这种配方可以准确和实时地在城市规模的环境中进行重新定位。相机构成估计算法,可以使用一组地理参照图像或3D场景代表来决定摄取图像的位置和方向。我们新的本地化范式,名为Inmplicide Pose Encoding(Imposing),嵌入图像和照相机在两个不同的神经网络中呈现出共同的潜在代表形式,这样我们就能计算出每个相配图像的相近性分数。通过对潜在空间进行分数的分数,相机的位置和方向不会直接反移,而是逐步完善。与基于结构的重新定位方法相比,我们隐含的地图具有记忆性,可以适当地探索,以便根据基于学习的回归方法改进本地化性表现。在本文中,我们描述了如何有效地优化我们所学的模块,如何将它们结合起来实现实时本地化,并展示各种大规模情景的结果,这些情景在准确性和计算效率方面大大超过先前的工作。