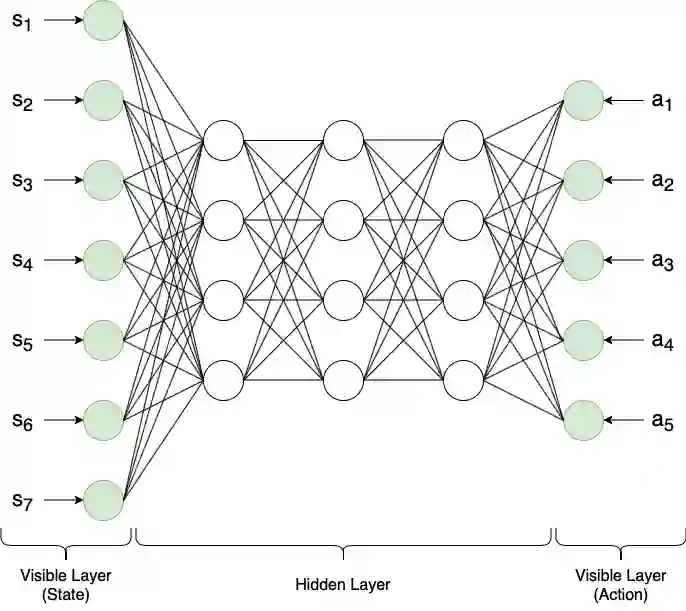
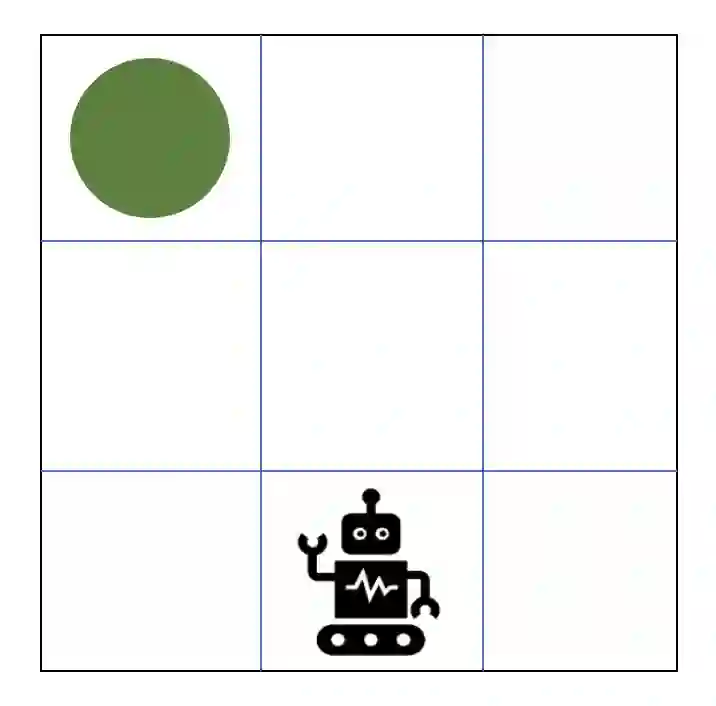
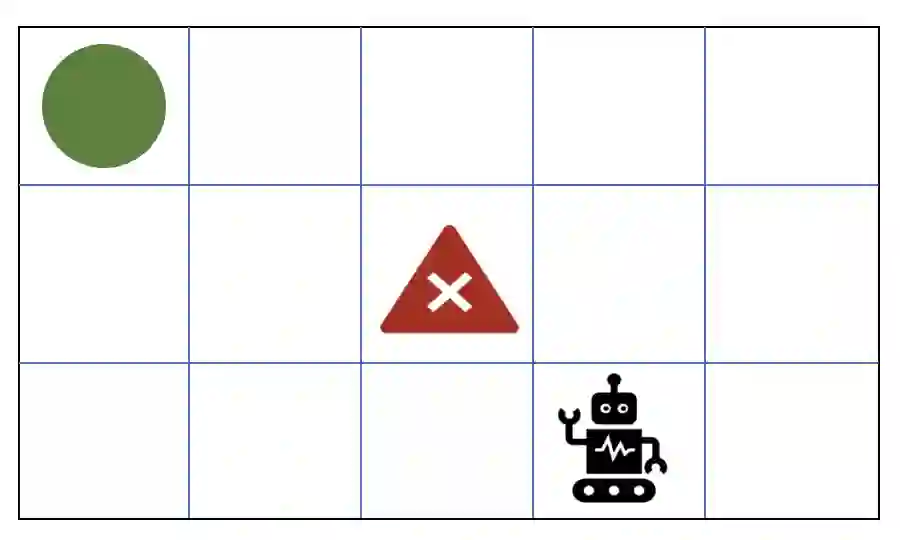
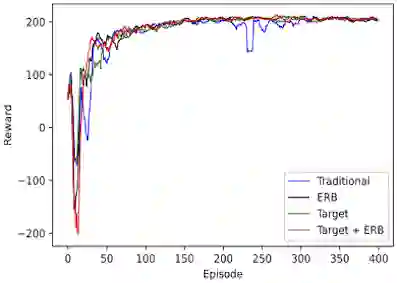
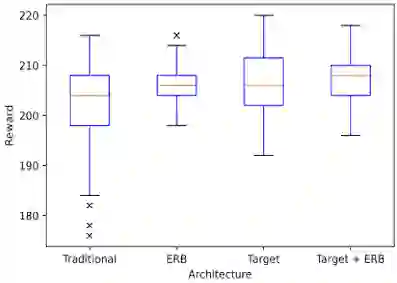
Reinforcement learning has driven impressive advances in machine learning. Simultaneously, quantum-enhanced machine learning algorithms using quantum annealing underlie heavy developments. Recently, a multi-agent reinforcement learning (MARL) architecture combining both paradigms has been proposed. This novel algorithm, which utilizes Quantum Boltzmann Machines (QBMs) for Q-value approximation has outperformed regular deep reinforcement learning in terms of time-steps needed to converge. However, this algorithm was restricted to single-agent and small 2x2 multi-agent grid domains. In this work, we propose an extension to the original concept in order to solve more challenging problems. Similar to classic DQNs, we add an experience replay buffer and use different networks for approximating the target and policy values. The experimental results show that learning becomes more stable and enables agents to find optimal policies in grid-domains with higher complexity. Additionally, we assess how parameter sharing influences the agents behavior in multi-agent domains. Quantum sampling proves to be a promising method for reinforcement learning tasks, but is currently limited by the QPU size and therefore by the size of the input and Boltzmann machine.
翻译:强化学习催生了机器学习的令人印象深刻的进步。 同时, 使用量子anneal 的量子增强机学习算法也成为了沉重的发展基础。 最近, 提出了将两种模式结合起来的多剂强化学习( MARL)架构。 这个为Q值近似使用 Quantum Boltzmann 机器(QBMs) 的新型算法比常规深度强化学习效果要好, 需要时间步骤才能汇聚。 但是, 这个算法仅限于单剂和小型 2x2 多剂网格域。 在这项工作中, 我们建议扩展原始概念, 以解决更具挑战性的问题。 类似经典的 DQNs, 我们添加了经验性缓冲, 并使用不同网络来接近目标和政策价值。 实验结果表明, 学习变得更加稳定, 使代理商能够在复杂程度更高的电网域找到最佳政策。 此外, 我们评估参数共享如何影响多剂领域的代理行为。 量抽样证明是加强学习任务的有希望的方法, 但是目前受到QPU 大小和Bolzmann 机器的限制。