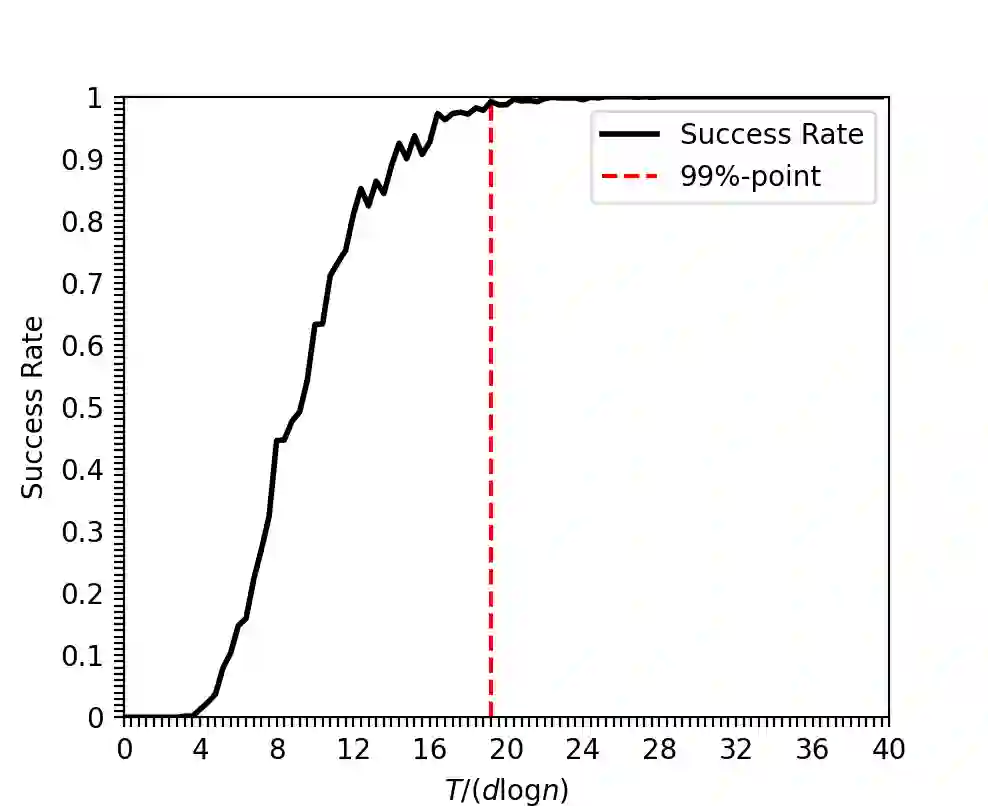
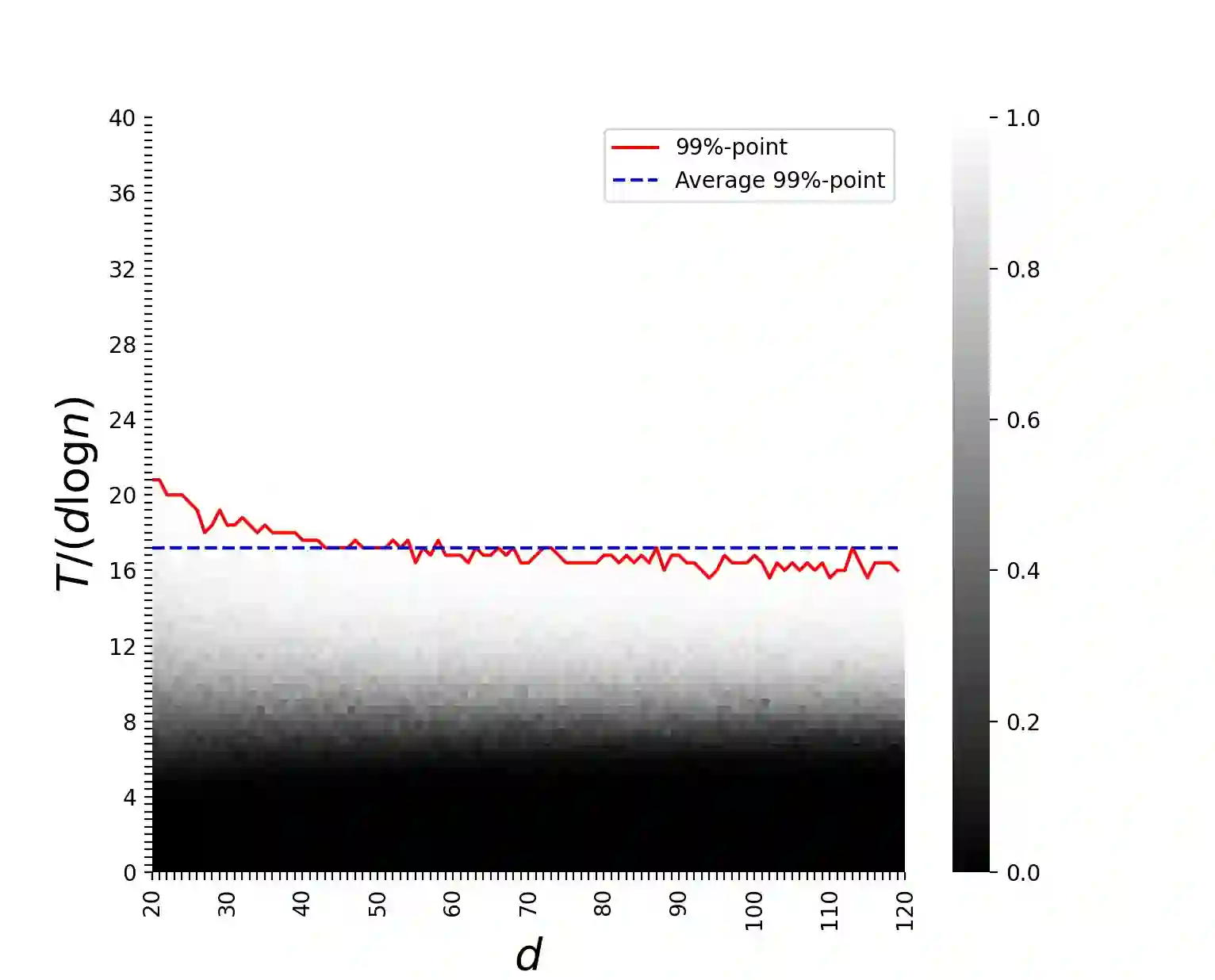
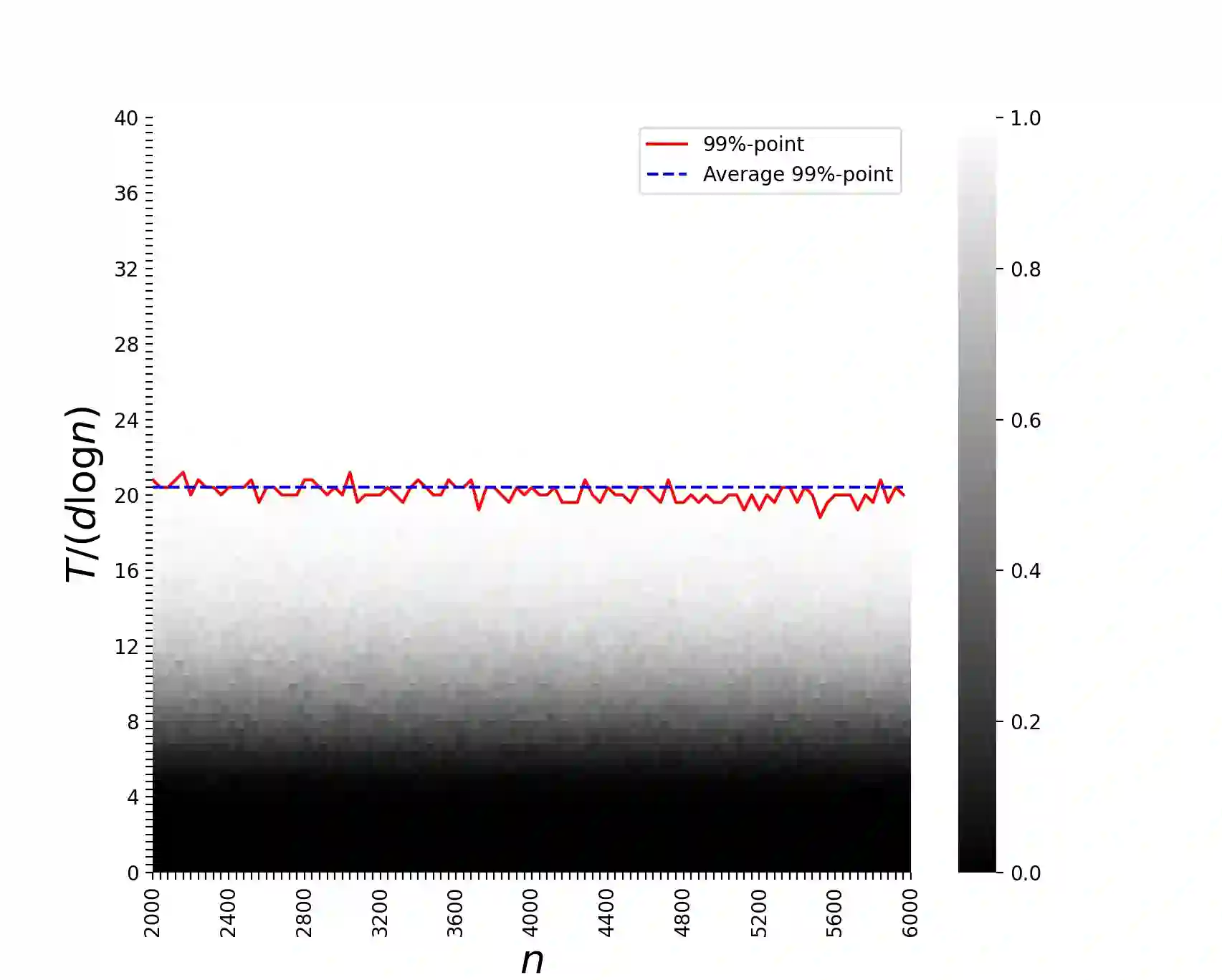
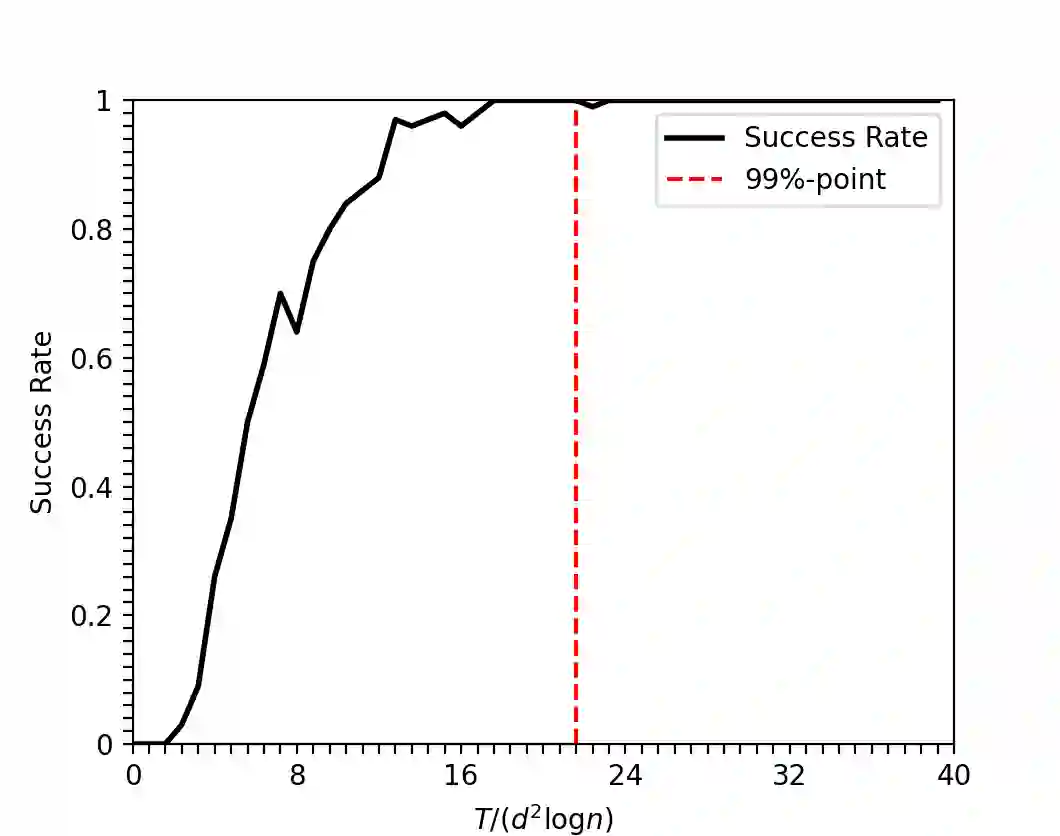
In the problem of classical group testing one aims to identify a small subset (of size $d$) diseased individuals/defective items in a large population (of size $n$). This process is based on a minimal number of suitably-designed group tests on subsets of items, where the test outcome is positive iff the given test contains at least one defective item. Motivated by physical considerations, we consider a generalized setting that includes as special cases multiple other group-testing-like models in the literature. In our setting, which subsumes as special cases a variety of noiseless and noisy group-testing models in the literature, the test outcome is positive with probability $f(x)$, where $x$ is the number of defectives tested in a pool, and $f(\cdot)$ is an arbitrary monotonically increasing (stochastic) test function. Our main contributions are as follows. 1. We present a non-adaptive scheme that with probability $1-\varepsilon$ identifies all defective items. Our scheme requires at most ${\cal O}( H(f) d\log\left(\frac{n}{\varepsilon}\right))$ tests, where $H(f)$ is a suitably defined "sensitivity parameter" of $f(\cdot)$, and is never larger than ${\cal O}\left(d^{1+o(1)}\right)$, but may be substantially smaller for many $f(\cdot)$. 2. We argue that any testing scheme (including adaptive schemes) needs at least $\Omega \left((1-\varepsilon)h(f) d\log\left(\frac n d\right)\right)$ tests to ensure reliable recovery. Here $h(f) \geq 1$ is a suitably defined "concentration parameter" of $f(\cdot)$. 3. We prove that $\frac{H(f)}{h(f)}\in\Theta(1)$ for a variety of sparse-recovery group-testing models in the literature, and $\frac {H(f)} {h(f)} \in {\cal O}\left(d^{1+o(1)}\right)$ for any other test function.
翻译:在古典组测试问题中, 我们的目标是在大型项目组中确定一个小子集( 以美元计) {( 美元计) 疾病个人/ 失效物品( 以美元计) 。 这个过程的基础是对子组项目进行最小数量的合适组测试, 如果给定的测试至少包含一个有缺陷的项目, 测试结果为正数 。 受物理考量的驱动, 我们考虑一个通用设置, 包括文献中多个类似组测试的模型。 在我们的设置中, 将各种无噪音和吵动的组测试模型作为特殊案例进行, 概率为 $( 美元计) 。 测试结果为 $( 美元) 。 美元=( 美元计) 。 美元=( 美元) 。