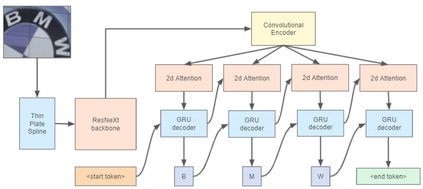
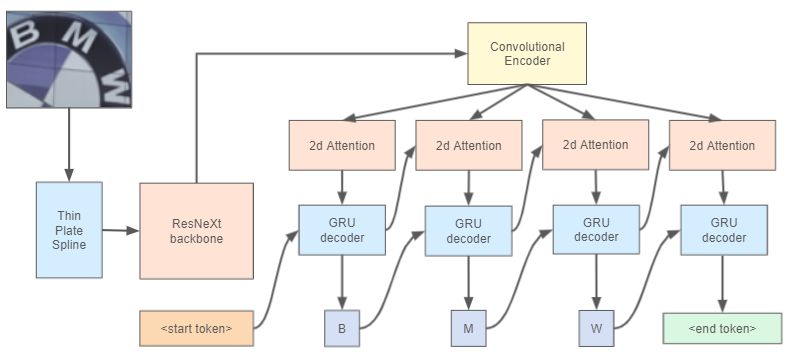
Recent works in the text recognition area have pushed forward the recognition results to the new horizons. But for a long time a lack of large human-labeled natural text recognition datasets has been forcing researchers to use synthetic data for training text recognition models. Even though synthetic datasets are very large (MJSynth and SynthTest, two most famous synthetic datasets, have several million images each), their diversity could be insufficient, compared to natural datasets like ICDAR and others. Fortunately, the recently released text-recognition annotation for OpenImages V5 dataset has comparable with synthetic dataset number of instances and more diverse examples. We have used this annotation with a Text Recognition head architecture from the Yet Another Mask Text Spotter and got comparable to the SOTA results. On some datasets we have even outperformed previous SOTA models. In this paper we also introduce a text recognition model. The model's code is available.
翻译:文本识别领域的近期工作将识别结果推向了新视野。 但长期以来,缺少大量人类标签的自然文本识别数据集迫使研究人员将合成数据用于培训文本识别模型。即使合成数据集非常庞大(MJSynth和SynthTest,两个最著名的合成数据集,每个数据集都有几百万张图像),与ICDAR等自然数据集相比,它们的多样性可能不够。幸运的是,最近发布的OpenImages V5数据集的文本识别注释与合成数据集实例和更多样的例子数量相仿。我们使用该批注与“又一个面具文本显示器”的文本识别头结构相仿,并与SOTA结果相仿。在有些数据集上,我们甚至比以往的SOTA模型还差。在本文中,我们还引入了一个文本识别模型。该模型的代码是可用的。