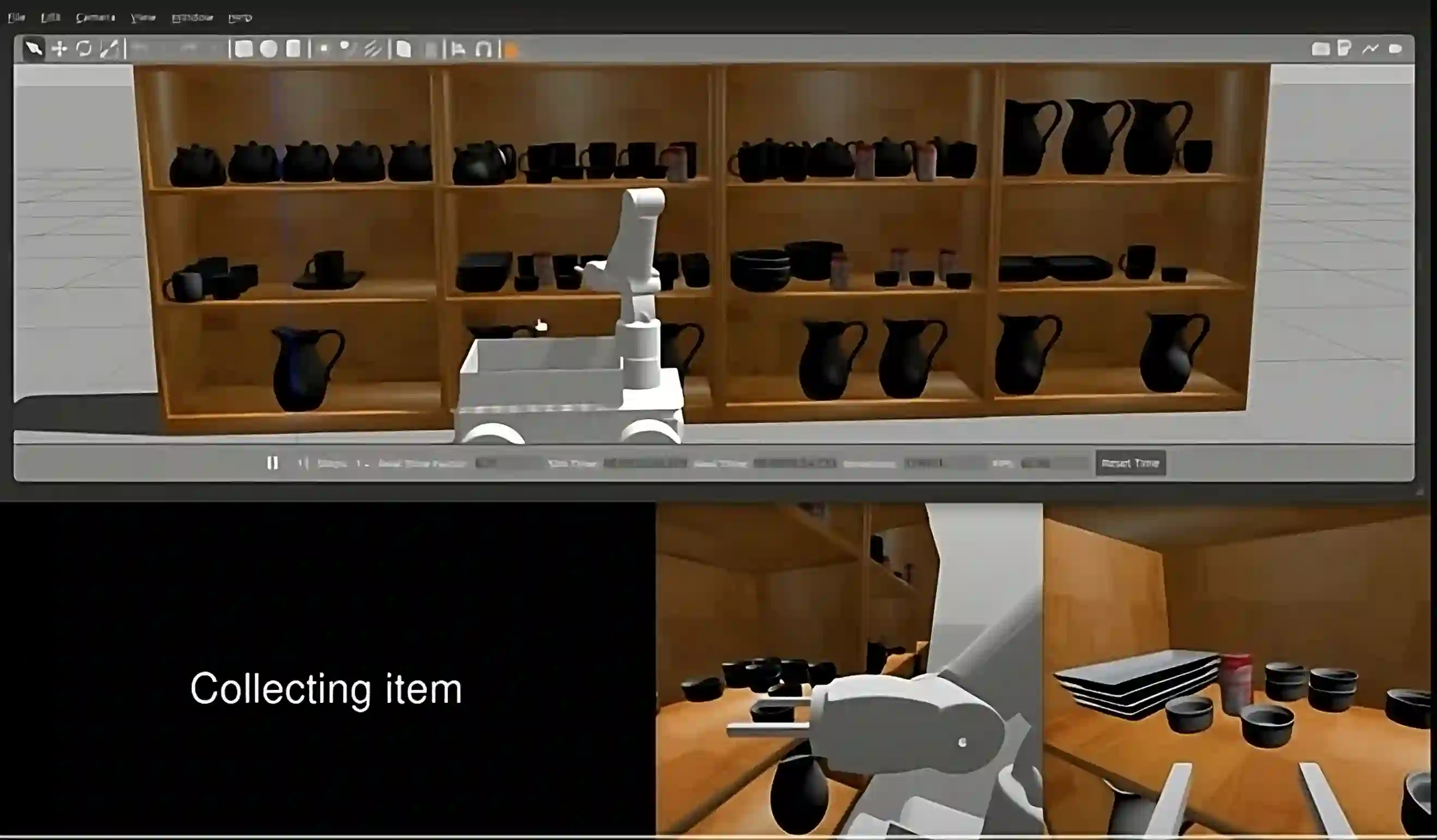
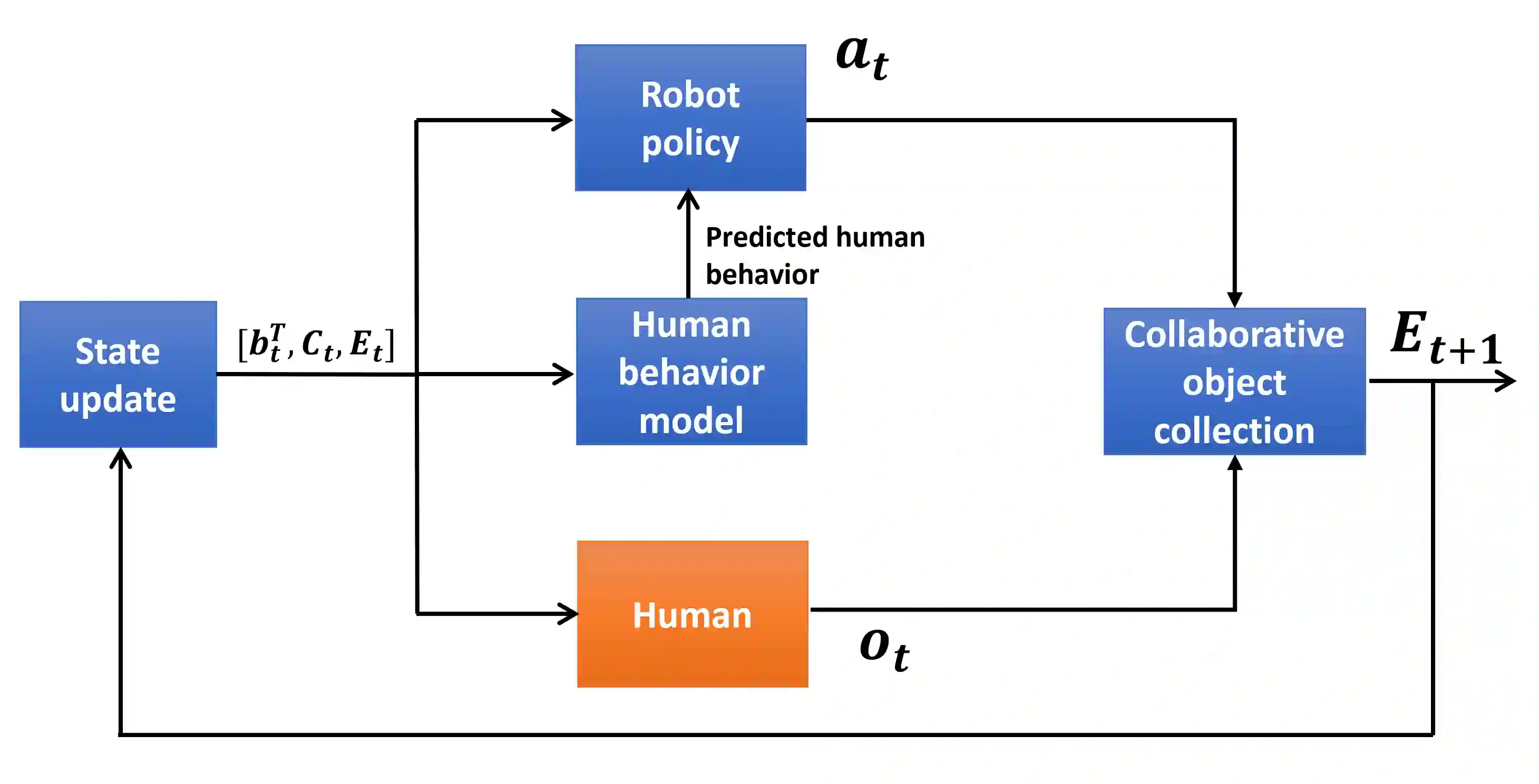
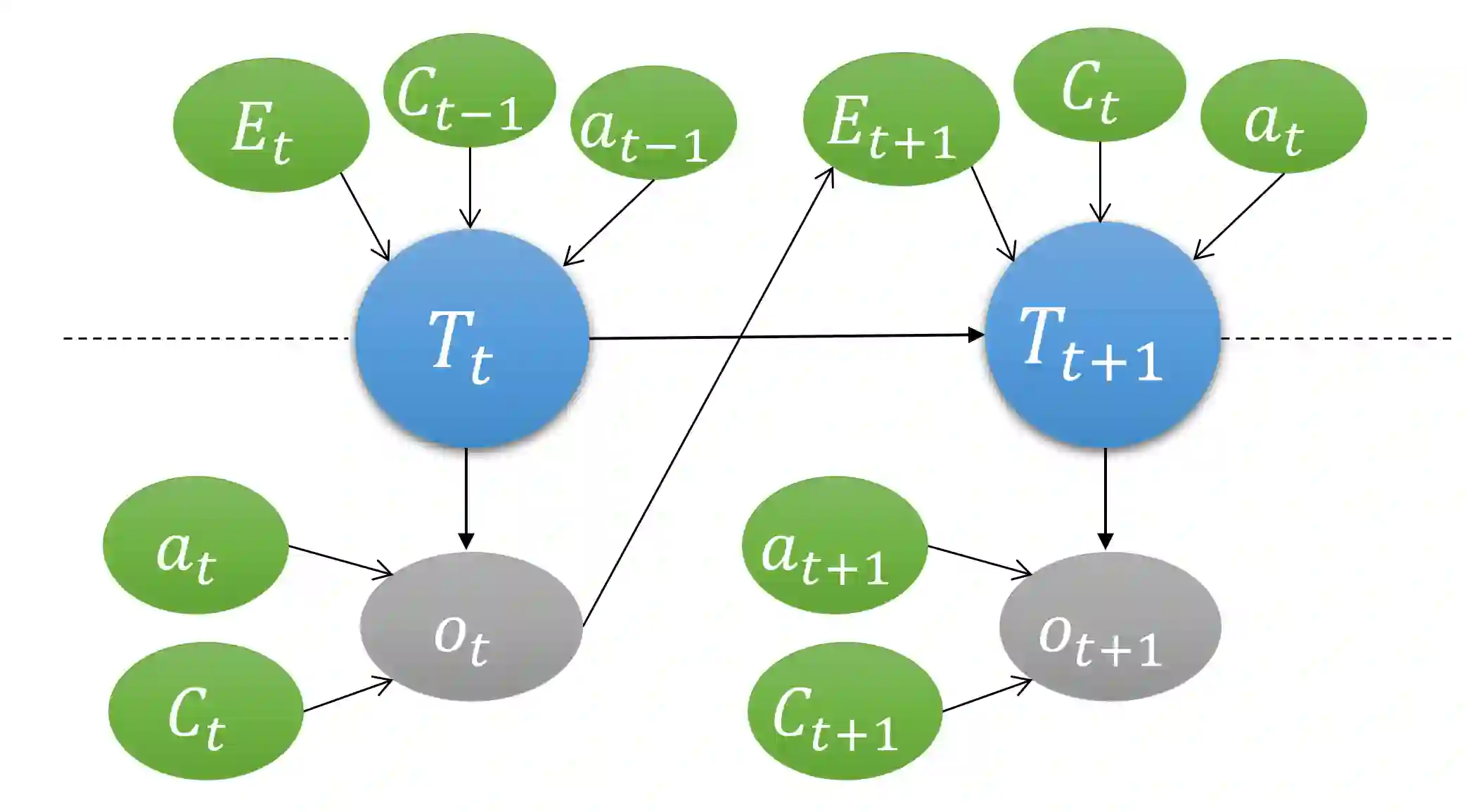
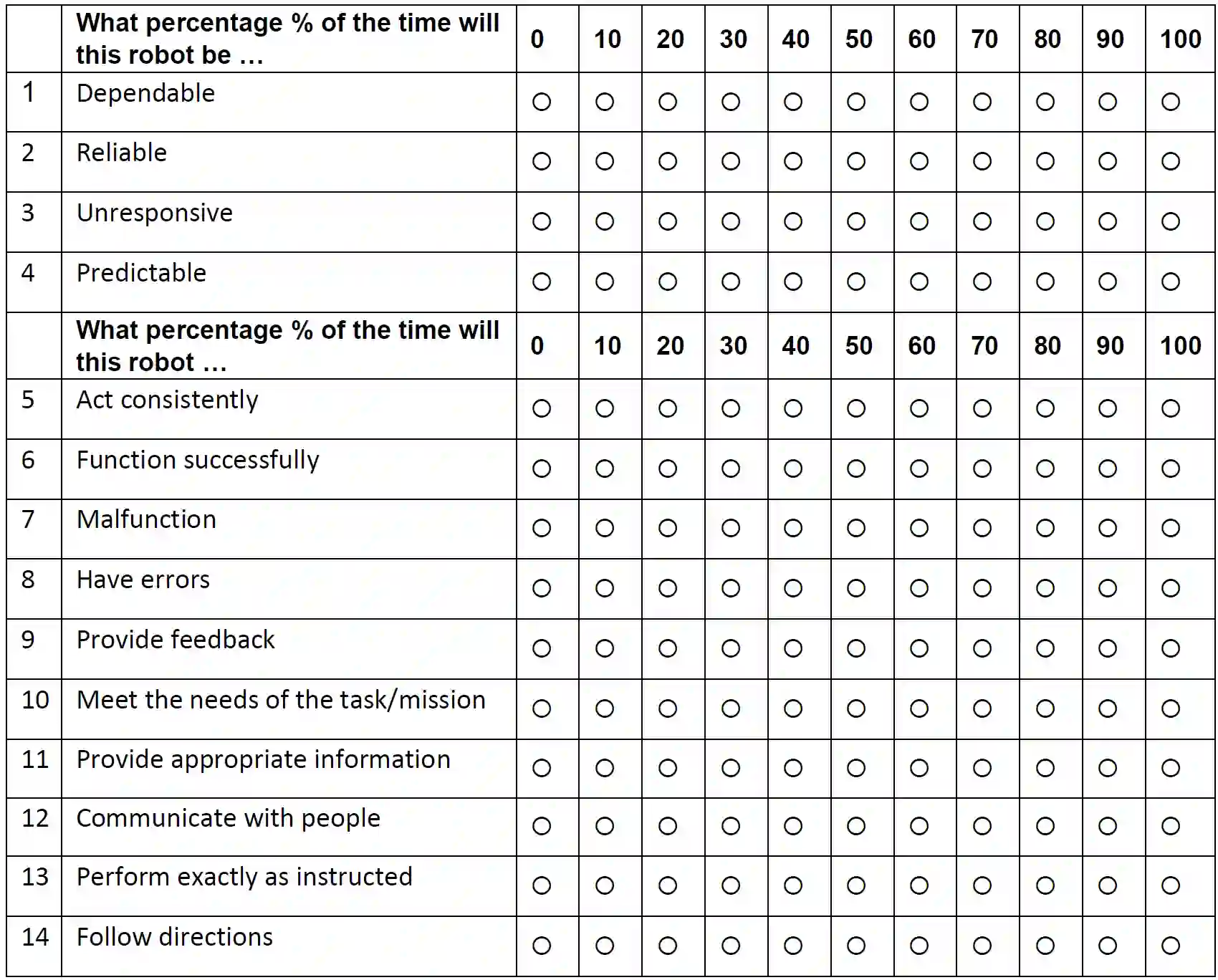
Our goal is to model and experimentally assess trust evolution to predict future beliefs and behaviors of human-robot teams in dynamic environments. Research suggests that maintaining trust among team members in a human-robot team is vital for successful team performance. Research suggests that trust is a multi-dimensional and latent entity that relates to past experiences and future actions in a complex manner. Employing a human-robot collaborative task, we design an optimal assistance-seeking strategy for the robot using a POMDP framework. In the task, the human supervises an autonomous mobile manipulator collecting objects in an environment. The supervisor's task is to ensure that the robot safely executes its task. The robot can either choose to attempt to collect the object or seek human assistance. The human supervisor actively monitors the robot's activities, offering assistance upon request, and intervening if they perceive the robot may fail. In this setting, human trust is the hidden state, and the primary objective is to optimize team performance. We execute two sets of human-robot interaction experiments. The data from the first experiment are used to estimate POMDP parameters, which are used to compute an optimal assistance-seeking policy evaluated in the second experiment. The estimated POMDP parameters reveal that, for most participants, human intervention is more probable when trust is low, particularly in high-complexity tasks. Our estimates suggest that the robot's action of asking for assistance in high-complexity tasks can positively impact human trust. Our experimental results show that the proposed trust-aware policy is better than an optimal trust-agnostic policy. By comparing model estimates of human trust, obtained using only behavioral data, with the collected self-reported trust values, we show that model estimates are isomorphic to self-reported responses.
翻译:本研究旨在建模并实验评估信任演化,以预测动态环境中人机团队的未来信念与行为。现有研究表明,维持人机团队成员间的信任对于团队绩效至关重要。信任是一个多维、潜在的实体,以复杂方式关联着过往经验与未来行为。通过设计人机协作任务,我们采用部分可观测马尔可夫决策过程(POMDP)框架为机器人构建了最优辅助请求策略。在该任务中,人类监督者指挥自主移动机械臂在环境中收集物体,其职责是确保机器人安全执行任务。机器人可选择自主尝试收集物体或请求人工辅助。人类监督者持续监控机器人活动,在收到请求时提供协助,并在预判机器人可能失败时主动干预。在此设定中,人类信任作为隐状态,主要优化目标为团队绩效。我们进行了两组人机交互实验:首组实验数据用于估计POMDP参数,进而计算出的最优辅助请求策略在第二组实验中接受评估。参数估计结果表明,对于多数参与者,当信任度较低时(尤其在复杂任务中)人类干预概率更高。我们的估计显示,机器人在高复杂度任务中主动请求辅助的行为能对信任产生积极影响。实验结果证明,所提出的信任感知策略优于不考虑信任的最优策略。通过对比仅基于行为数据获得的信任模型估计值与收集的自我报告信任值,我们发现模型估计与自我报告响应具有同构性。