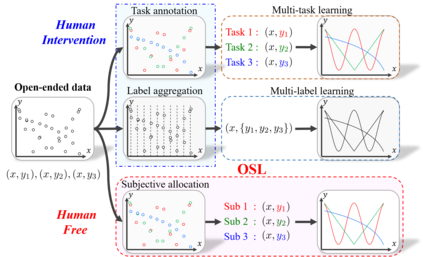
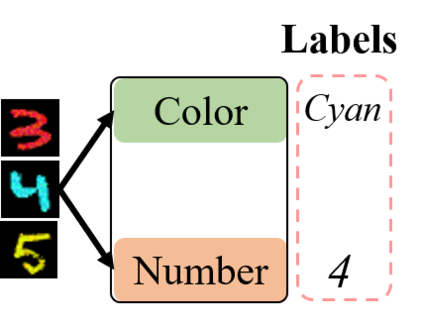
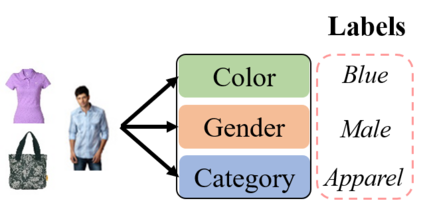
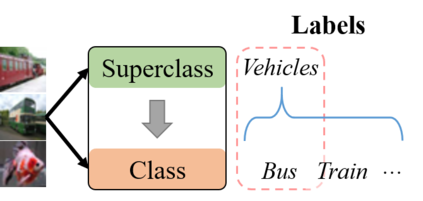
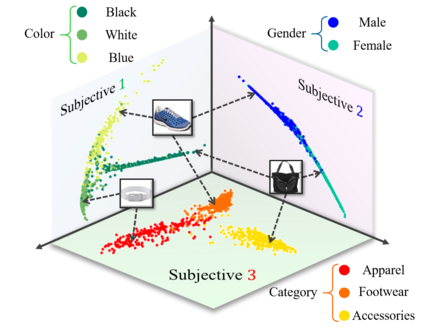
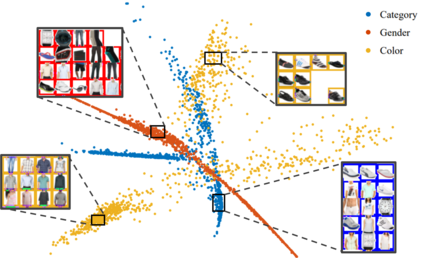
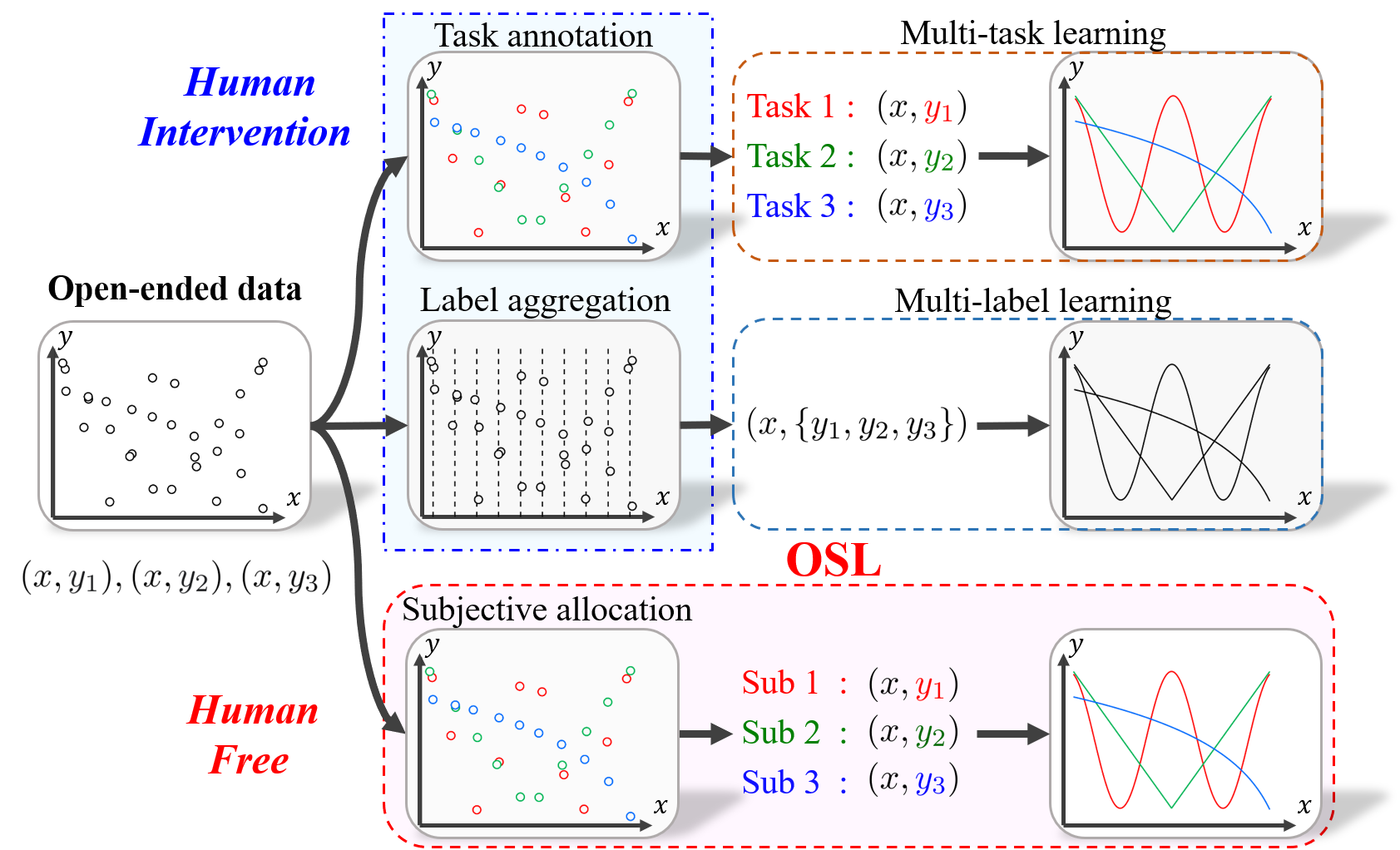
Conventional machine learning methods typically assume that data is split according to tasks, and the data in each task can be modeled by a single target function. However, this assumption is invalid in open-ended environments where no manual task definition is available. In this paper, we present a novel supervised learning paradigm of learning from open-ended data. Open-ended data inherently requires multiple single-valued deterministic mapping functions to capture all its input-output relations, exhibiting an essential structural difference from conventional supervised data. We formally expound this structural property with a novel concept termed as mapping rank, and show that open-ended data poses a fundamental difficulty for conventional supervised learning, since different data samples may conflict with each other if the mapping rank of data is larger than one. To address this issue, we devise an Open-ended Supervised Learning (OSL) framework, of which the key innovation is a subjective function that automatically allocates the data among multiple candidate models to resolve the conflict, developing a natural cognition hierarchy. We demonstrate the efficacy of OSL both theoretically and empirically, and show that OSL achieves human-like task cognition without task-level supervision.
翻译:常规机器学习方法通常假定数据按任务分列,而每项任务中的数据可按单一目标功能建模。然而,这一假设在没有手动任务定义的开放环境中是无效的。在本文件中,我们提出了一个从开放式数据中学习的新颖的受监督的学习范式。不限成员名额数据本身需要多种单一价值的确定性绘图功能来捕捉其所有输入-产出关系,显示与常规监督数据之间的基本结构差异。我们正式用被称为绘图等级的新概念来解释这一结构属性,并表明开放式数据对常规监督学习构成根本困难,因为如果数据绘图级别大于一个,不同的数据样本可能会相互冲突。为了解决这一问题,我们设计了一个开放式超视距学习框架,其中的关键创新功能是自动分配多个候选模型的数据,以解决冲突,形成自然认知等级。我们从理论和经验上展示了OSL的功效,并显示OSL在没有任务级别监督的情况下实现类似任务值的任务值。