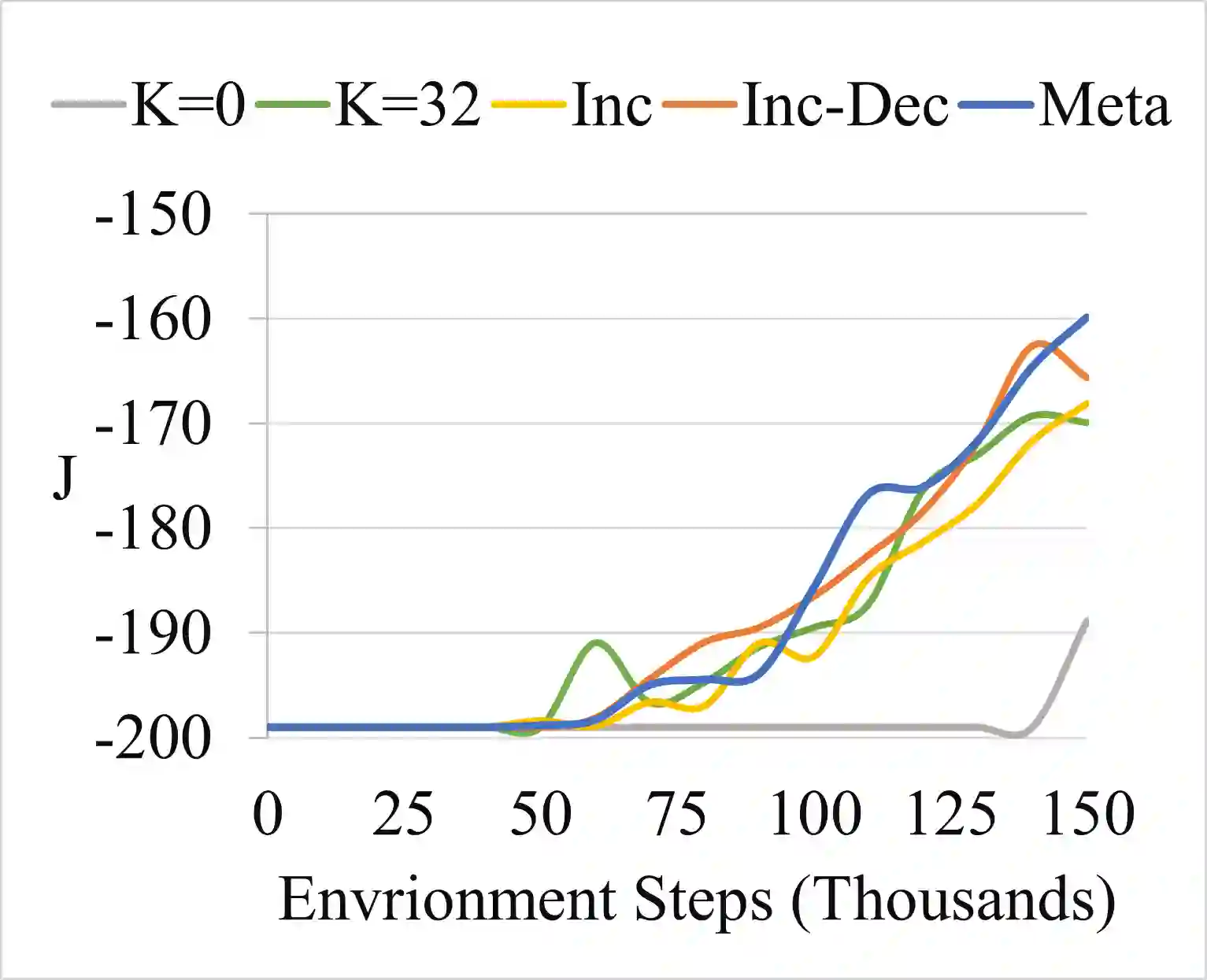
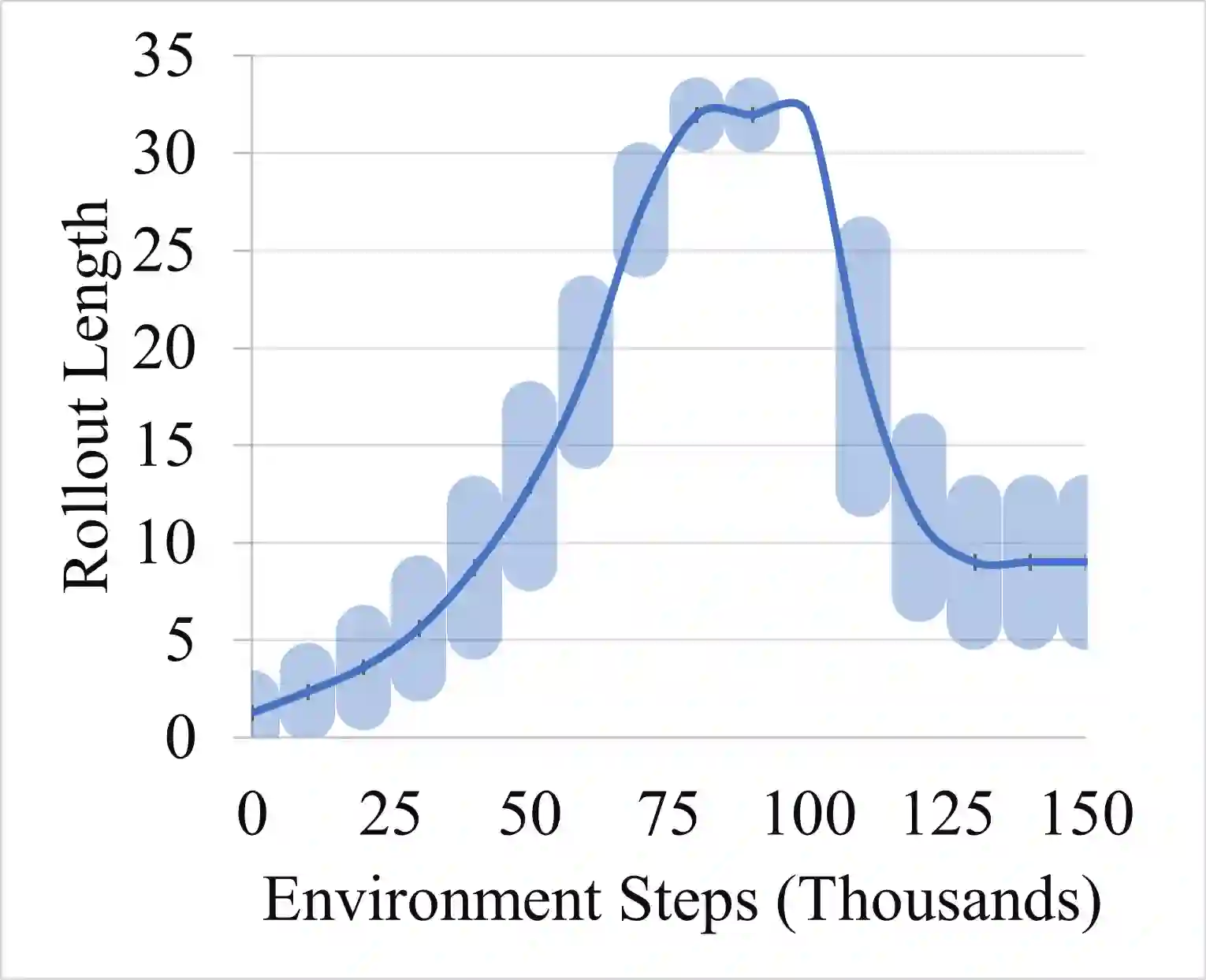
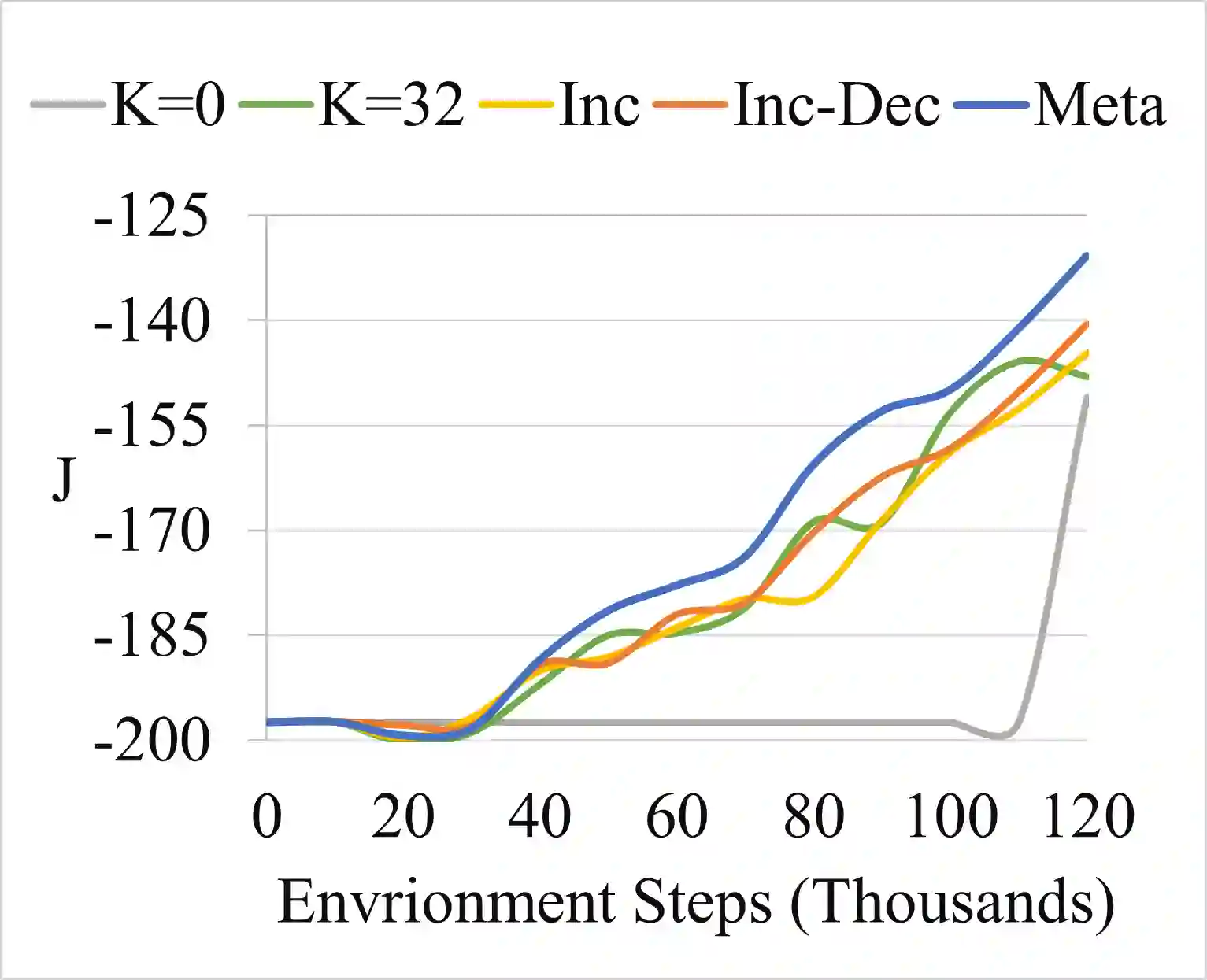
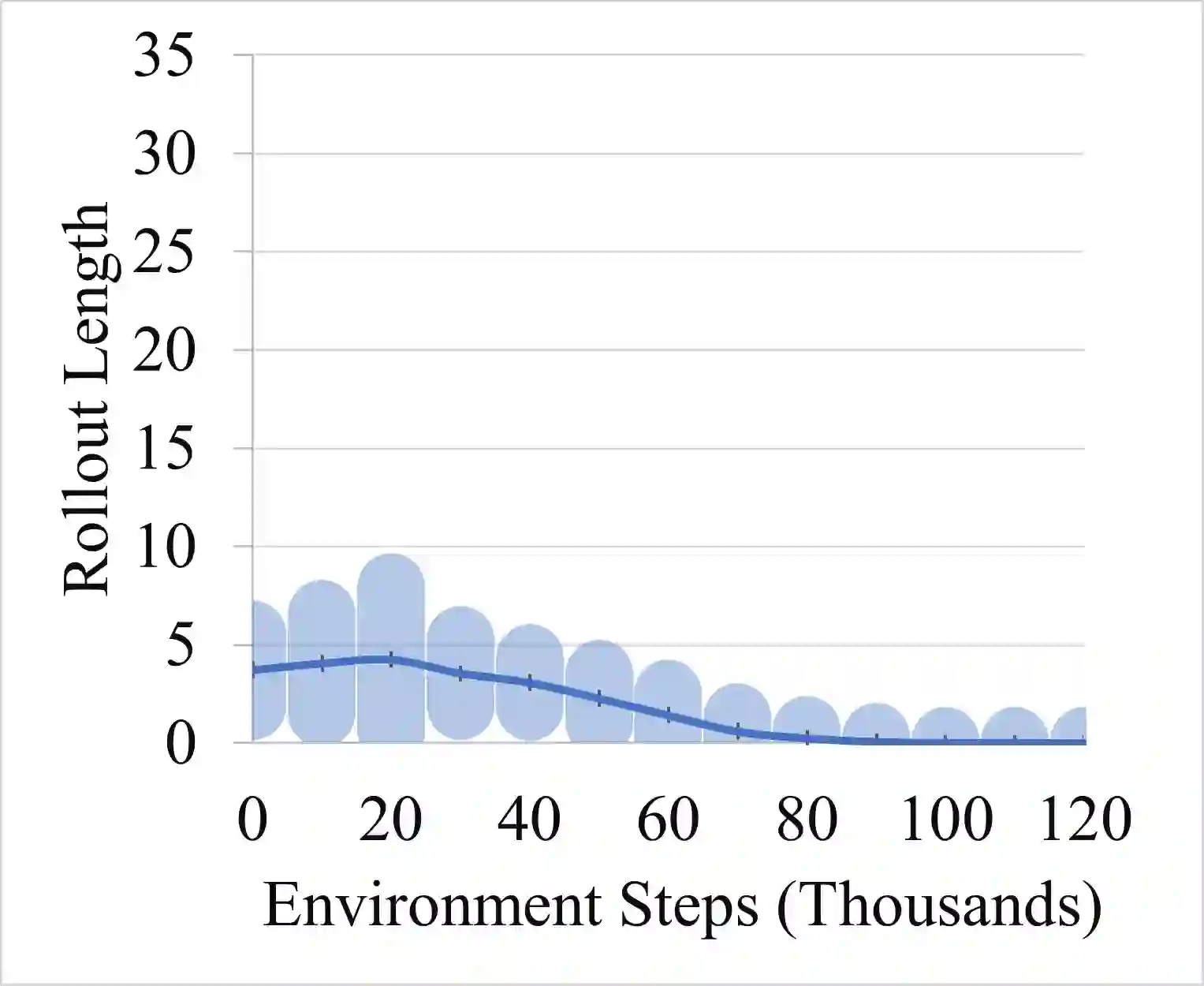
Model-based reinforcement learning promises to learn an optimal policy from fewer interactions with the environment compared to model-free reinforcement learning by learning an intermediate model of the environment in order to predict future interactions. When predicting a sequence of interactions, the rollout length, which limits the prediction horizon, is a critical hyperparameter as accuracy of the predictions diminishes in the regions that are further away from real experience. As a result, with a longer rollout length, an overall worse policy is learned in the long run. Thus, the hyperparameter provides a trade-off between quality and efficiency. In this work, we frame the problem of tuning the rollout length as a meta-level sequential decision-making problem that optimizes the final policy learned by model-based reinforcement learning given a fixed budget of environment interactions by adapting the hyperparameter dynamically based on feedback from the learning process, such as accuracy of the model and the remaining budget of interactions. We use model-free deep reinforcement learning to solve the meta-level decision problem and demonstrate that our approach outperforms common heuristic baselines on two well-known reinforcement learning environments.
翻译:以模型为基础的强化学习承诺从较少的环境互动中学习最佳政策,而通过学习一种中间环境模型来学习一种无模型的强化学习,以预测未来的互动。在预测一系列互动时,由于预测的准确性在距离实际经验更远的区域越来越低,因此,由于预测的准确性是一个至关重要的超参数。因此,由于推出时间较长,从长远来看,一项总体更差的政策已经学到。因此,超参数提供了质量和效率之间的权衡。在这项工作中,我们把调整推出时间的问题定义为一个元层次的顺序决策问题,根据基于模型的强化学习的固定预算,根据学习过程的反馈,如模型的准确性和其余的互动预算,优化通过基于基于模型的反馈,动态调整超光度环境互动的最后政策。我们用没有模型的深层强化学习来解决元级决策问题,并表明我们的方法在两个众所周知的强化学习环境中的超常的超值基线。