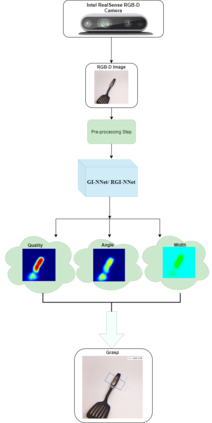
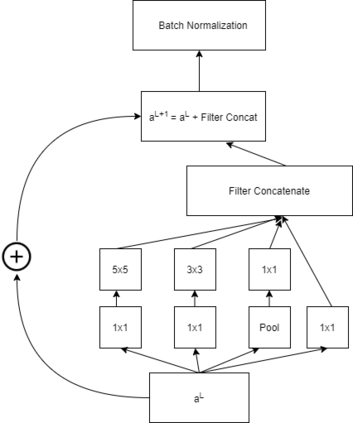
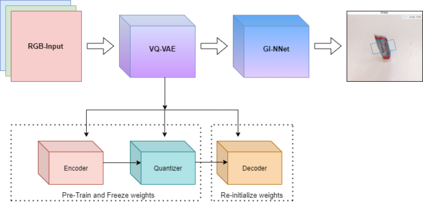
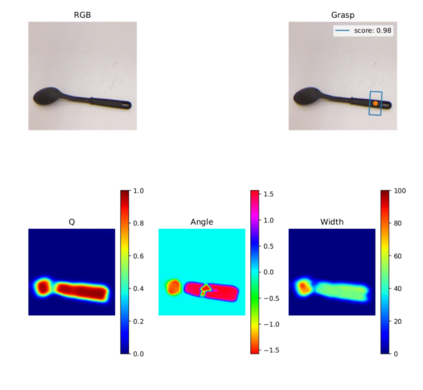
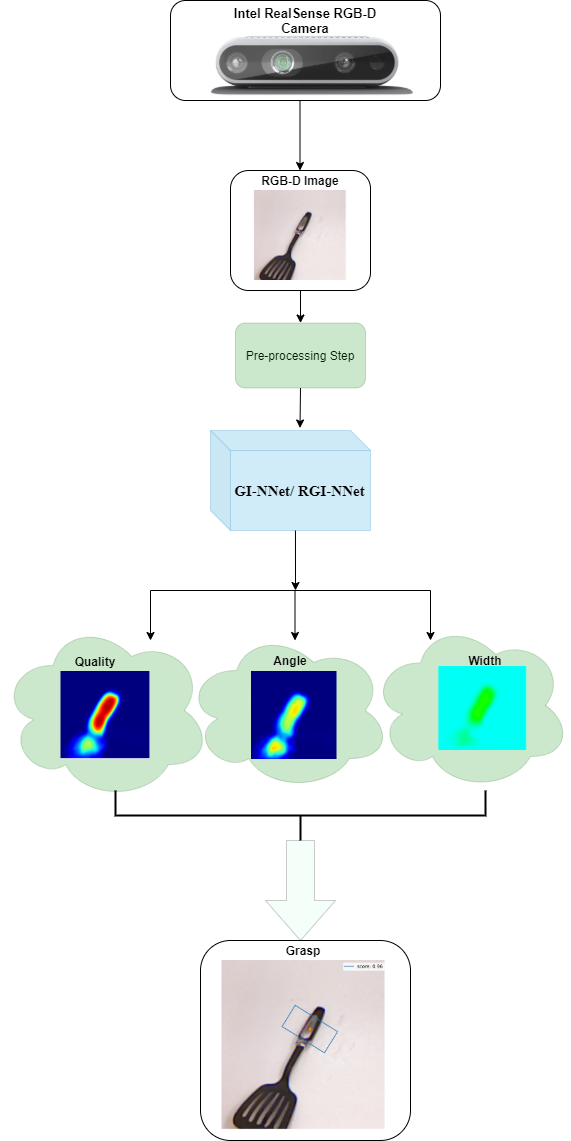
Our way of grasping objects is challenging for efficient, intelligent and optimal grasp by COBOTs. To streamline the process, here we use deep learning techniques to help robots learn to generate and execute appropriate grasps quickly. We developed a Generative Inception Neural Network (GI-NNet) model, capable of generating antipodal robotic grasps on seen as well as unseen objects. It is trained on Cornell Grasping Dataset (CGD) and attained 98.87% grasp pose accuracy for detecting both regular and irregular shaped objects from RGB-Depth (RGB-D) images while requiring only one third of the network trainable parameters as compared to the existing approaches. However, to attain this level of performance the model requires the entire 90% of the available labelled data of CGD keeping only 10% labelled data for testing which makes it vulnerable to poor generalization. Furthermore, getting sufficient and quality labelled dataset is becoming increasingly difficult keeping in pace with the requirement of gigantic networks. To address these issues, we attach our model as a decoder with a semi-supervised learning based architecture known as Vector Quantized Variational Auto Encoder (VQVAE), which works efficiently when trained both with the available labelled and unlabelled data. The proposed model, which we name as Representation based GI-NNet (RGI-NNet), has been trained with various splits of label data on CGD with as minimum as 10% labelled dataset together with latent embedding generated from VQVAE up to 50% labelled data with latent embedding obtained from VQVAE. The performance level, in terms of grasp pose accuracy of RGI-NNet, varies between 92.13% to 95.6% which is far better than several existing models trained with only labelled dataset. For the performance verification of both GI-NNet and RGI-NNet models, we use Anukul (Baxter) hardware cobot.
翻译:为了简化程序,我们使用深层次学习技术帮助机器人学习如何生成和快速执行适当的抓取。 我们开发了一个导出感知神经网络(GI-NNet)模型, 能够生成在可见和不可见天体上的抗波机器人抓取功能。 它在Cornell Grash Dataset(CGD)上接受培训, 并达到98.87%的抓取率, 能够探测 RGB- Depeh (RGB-D) 图像的常规和异常形状对象, 同时只需要三分之一的网络可训练参数, 而与现有方法相比,我们只需要三分之一的网络可训练的网络精确度参数。 然而,要达到这一水平, 模型需要整个90%的CGD(GN-NNet) 标签数据只保留10%的标签数据,使得它容易被忽略。 此外, 获得充足和高质量的标签数据集越来越难以跟上巨型网络的要求 。 为了解决这些问题, 我们把模型与一个半监督的学习架构连接起来, 被称为 Victor NQ- QQ, 与经过训练的 IMLO- dald GI- dal Q Q 数据库 数据库的运行的运行 数据库运行数据运行 和 数据库的运行的运行的运行, 以10个数据都以高效的运行为基数据 。