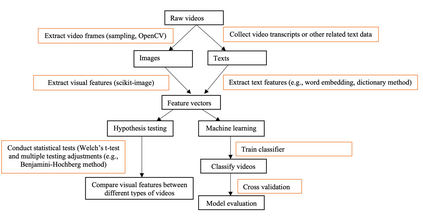
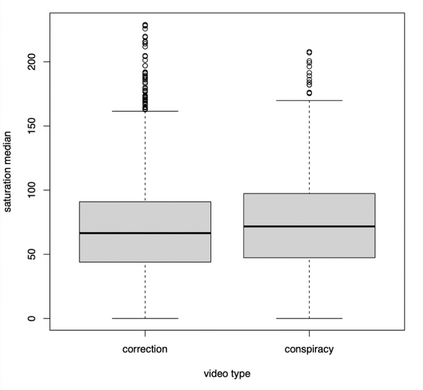
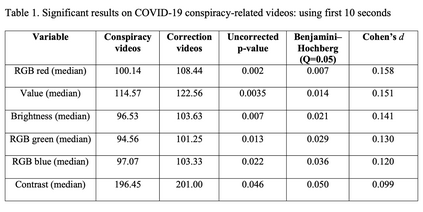
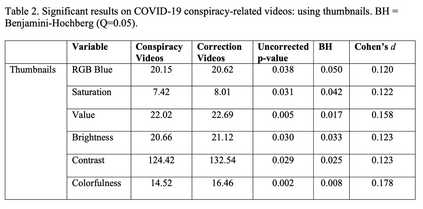
Recent years have witnessed an explosion of science conspiracy videos on the Internet, challenging science epistemology and public understanding of science. Scholars have started to examine the persuasion techniques used in conspiracy messages such as uncertainty and fear yet, little is understood about the visual narratives, especially how visual narratives differ in videos that debunk conspiracies versus those that propagate conspiracies. This paper addresses this gap in understanding visual framing in conspiracy videos through analyzing millions of frames from conspiracy and counter-conspiracy YouTube videos using computational methods. We found that conspiracy videos tended to use lower color variance and brightness, especially in thumbnails and earlier parts of the videos. This paper also demonstrates how researchers can integrate textual and visual features in machine learning models to study conspiracies on social media and discusses the implications of computational modeling for scholars interested in studying visual manipulation in the digital era. The analysis of visual and textual features presented in this paper could be useful for future studies focused on designing systems to identify conspiracy content on the Internet.
翻译:近些年来,互联网上出现了科学阴谋录像的爆炸,科学认知学和公众对科学的认知和理解。学者们开始研究阴谋信息(例如不确定性和恐惧)中使用的说服技巧,然而,对于视觉叙事,特别是揭发阴谋与传播阴谋的视频中的视觉叙事有何不同,人们对此知之甚少。本文通过利用计算方法分析阴谋和反阴谋YouTube视频中的数百万个框架,解决了对阴谋录像中视觉框架的理解差距。我们发现,阴谋录像往往使用更低的颜色差异和亮度,特别是在缩略图和早期的视频中。本文还展示了研究人员如何将文字和视觉特征纳入机器学习模型,以研究社会媒体上的阴谋,并讨论计算模型对有兴趣研究数字时代视觉操纵的学者的影响。本文对视觉和文字特征的分析对于今后研究重点设计系统以确定互联网上的阴谋内容可能很有帮助。