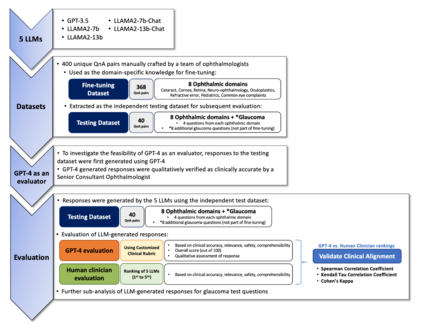
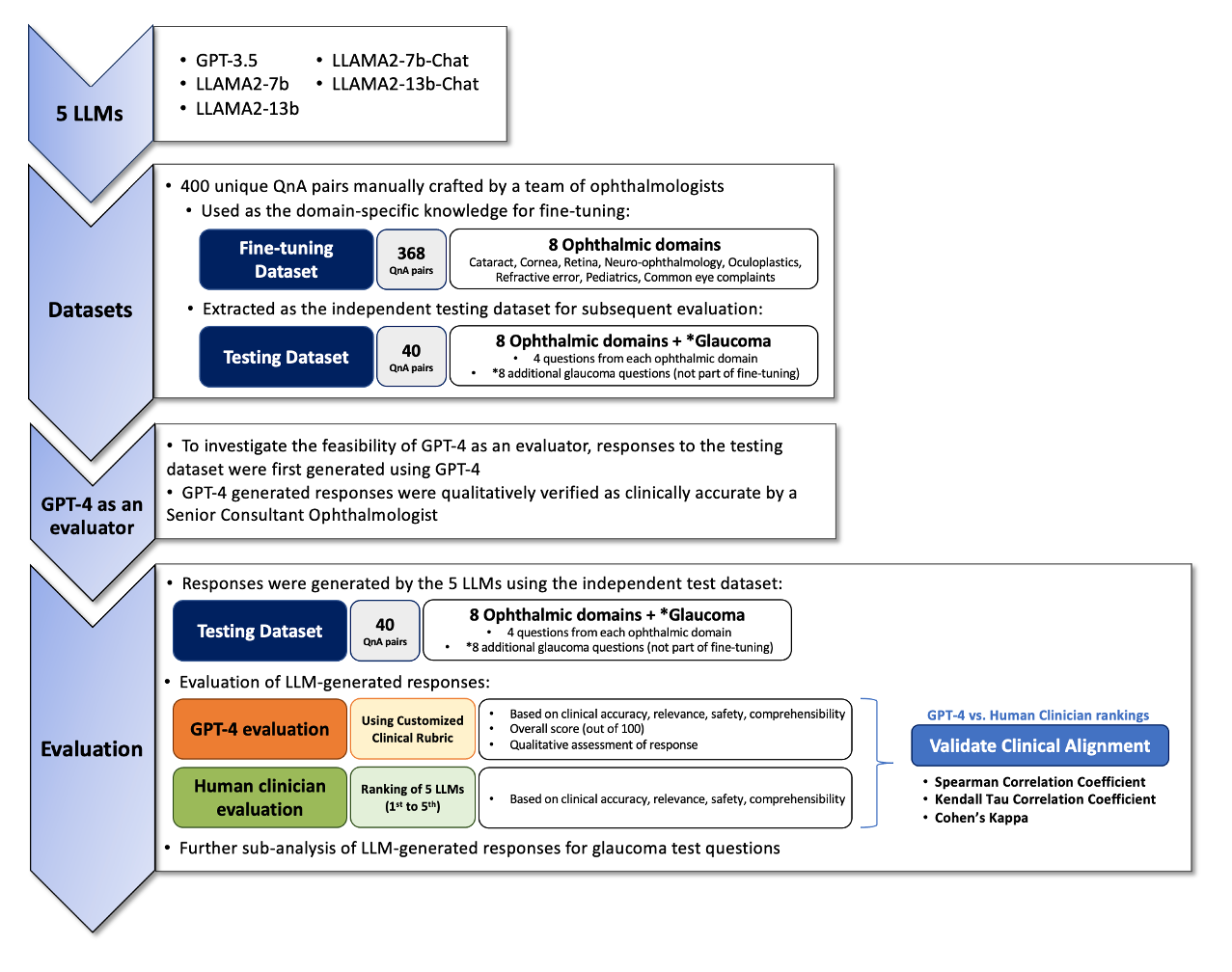
Purpose: To assess the alignment of GPT-4-based evaluation to human clinician experts, for the evaluation of responses to ophthalmology-related patient queries generated by fine-tuned LLM chatbots. Methods: 400 ophthalmology questions and paired answers were created by ophthalmologists to represent commonly asked patient questions, divided into fine-tuning (368; 92%), and testing (40; 8%). We find-tuned 5 different LLMs, including LLAMA2-7b, LLAMA2-7b-Chat, LLAMA2-13b, and LLAMA2-13b-Chat. For the testing dataset, additional 8 glaucoma QnA pairs were included. 200 responses to the testing dataset were generated by 5 fine-tuned LLMs for evaluation. A customized clinical evaluation rubric was used to guide GPT-4 evaluation, grounded on clinical accuracy, relevance, patient safety, and ease of understanding. GPT-4 evaluation was then compared against ranking by 5 clinicians for clinical alignment. Results: Among all fine-tuned LLMs, GPT-3.5 scored the highest (87.1%), followed by LLAMA2-13b (80.9%), LLAMA2-13b-chat (75.5%), LLAMA2-7b-Chat (70%) and LLAMA2-7b (68.8%) based on the GPT-4 evaluation. GPT-4 evaluation demonstrated significant agreement with human clinician rankings, with Spearman and Kendall Tau correlation coefficients of 0.90 and 0.80 respectively; while correlation based on Cohen Kappa was more modest at 0.50. Notably, qualitative analysis and the glaucoma sub-analysis revealed clinical inaccuracies in the LLM-generated responses, which were appropriately identified by the GPT-4 evaluation. Conclusion: The notable clinical alignment of GPT-4 evaluation highlighted its potential to streamline the clinical evaluation of LLM chatbot responses to healthcare-related queries. By complementing the existing clinician-dependent manual grading, this efficient and automated evaluation could assist the validation of future developments in LLM applications for healthcare.
翻译:暂无翻译