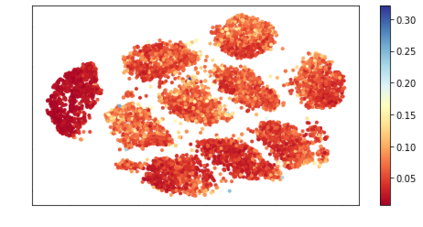
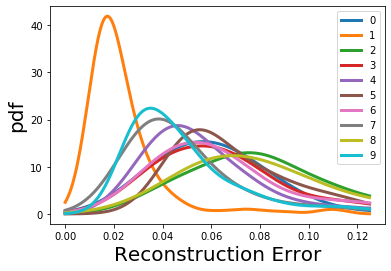
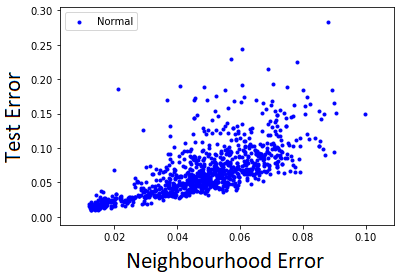
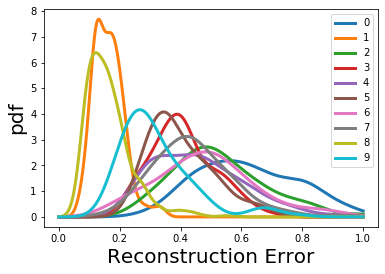
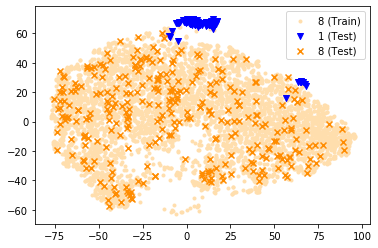
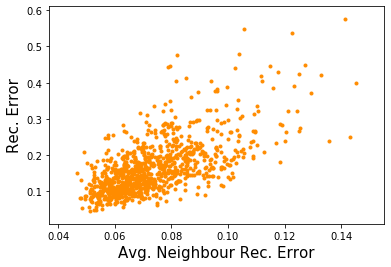
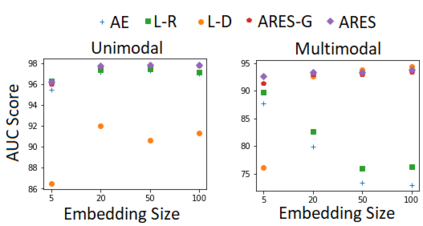
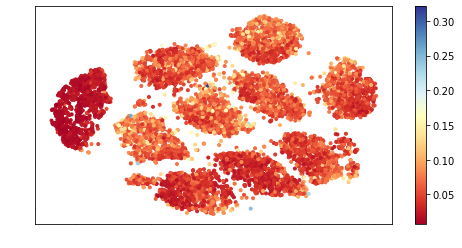
How can we detect anomalies: that is, samples that significantly differ from a given set of high-dimensional data, such as images or sensor data? This is a practical problem with numerous applications and is also relevant to the goal of making learning algorithms more robust to unexpected inputs. Autoencoders are a popular approach, partly due to their simplicity and their ability to perform dimension reduction. However, the anomaly scoring function is not adaptive to the natural variation in reconstruction error across the range of normal samples, which hinders their ability to detect real anomalies. In this paper, we empirically demonstrate the importance of local adaptivity for anomaly scoring in experiments with real data. We then propose our novel Adaptive Reconstruction Error-based Scoring approach, which adapts its scoring based on the local behaviour of reconstruction error over the latent space. We show that this improves anomaly detection performance over relevant baselines in a wide variety of benchmark datasets.
翻译:我们怎样才能发现异常点:即与图像或感官数据等一组高维数据差异很大的样本?这是许多应用中的一个实际问题,也与使学习算法对意外输入更加强大的目标相关。自动算术是一种流行的方法,部分由于它们简单,并且有能力进行尺寸缩小。然而,异常评分功能并不适应正常样本中重建错误的自然变化,这妨碍了它们探测真实异常点的能力。在本文中,我们从经验上表明,在用真实数据进行实验时,地方适应性对于异常点评的重要性。我们然后提出我们的新颖的适应性重建错误计分法,根据潜在空间的当地重建错误行为调整其评分。我们表明,这改善了各种基准数据集中相关基线的异常检测性。