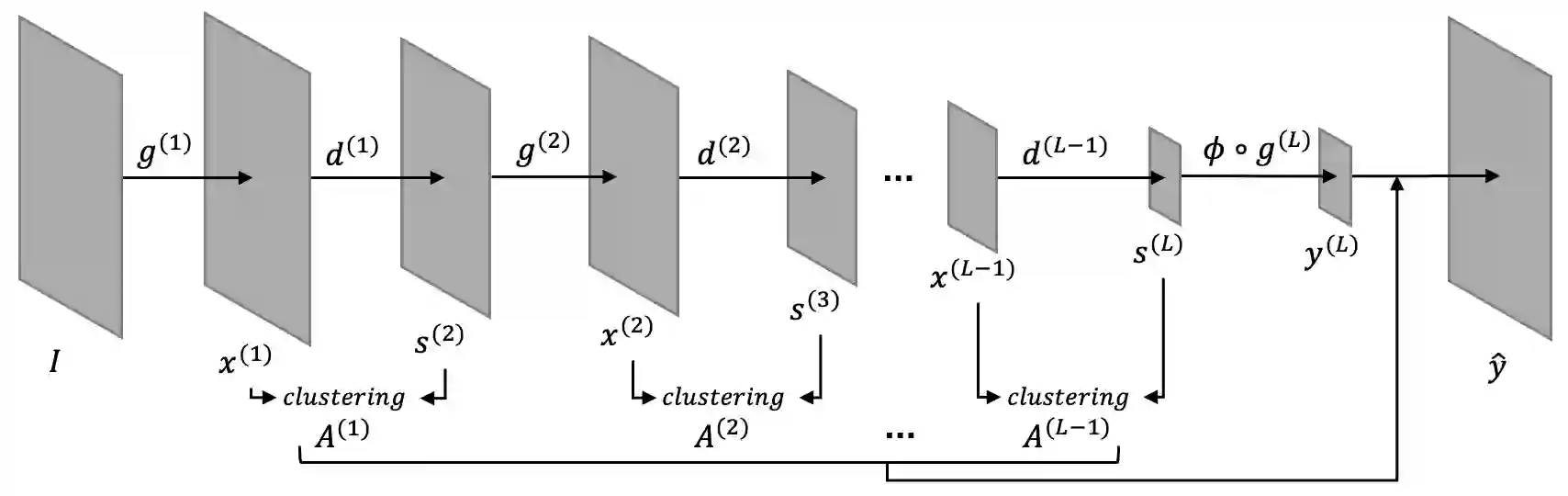
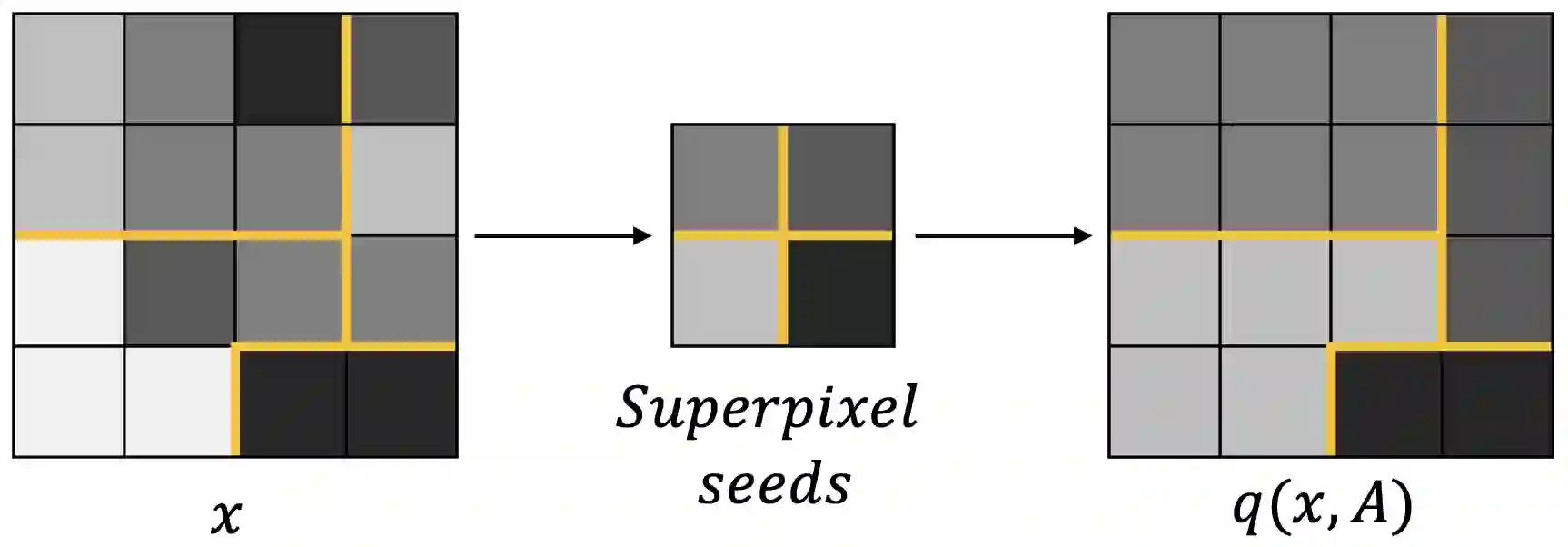
Semantic segmentation is the task of classifying each pixel in an image. Training a segmentation model achieves best results using annotated images, where each pixel is annotated with the corresponding class. When obtaining fine annotations is difficult or expensive, it may be possible to acquire coarse annotations, e.g. by roughly annotating pixels in an images leaving some pixels around the boundaries between classes unlabeled. Segmentation with coarse annotations is difficult, in particular when the objective is to optimize the alignment of boundaries between classes. This paper proposes a regularization method for models with an encoder-decoder architecture with superpixel based upsampling. It encourages the segmented pixels in the decoded image to be SLIC-superpixels, which are based on pixel color and position, independent of the segmentation annotation. The method is applied to FCN-16 fully convolutional network architecture and evaluated on the SUIM, Cityscapes, and PanNuke data sets. It is shown that the boundary recall improves significantly compared to state-of-the-art models when trained on coarse annotations.
翻译:语义分割任务旨在对图像中的每个像素进行分类。使用标注图像训练分割模型可获得最佳效果,其中每个像素均标注了相应的类别。当获取精细标注困难或成本高昂时,可采用粗标注方式,例如粗略标注图像中的像素,而将类别边界周围的某些像素留为未标注状态。基于粗标注的分割具有挑战性,尤其是在优化类别间边界对齐的目标下。本文提出一种针对编码器-解码器架构的正则化方法,该方法采用基于超像素的上采样策略。该方法促使解码图像中的分割像素形成SLIC超像素——这类超像素仅依据像素颜色与空间位置生成,与分割标注无关。本方法应用于FCN-16全卷积网络架构,并在SUIM、Cityscapes和PanNuke数据集上进行评估。实验表明,在粗标注训练条件下,该方法相比现有最优模型能显著提升边界召回率。