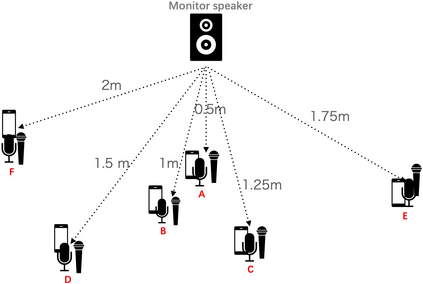
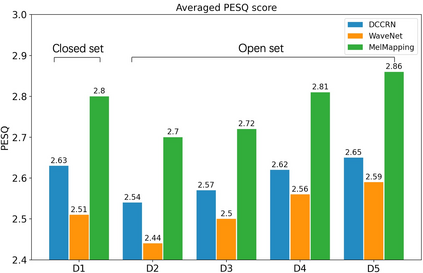
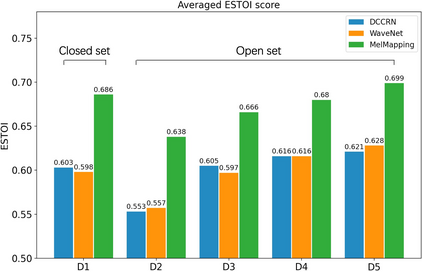
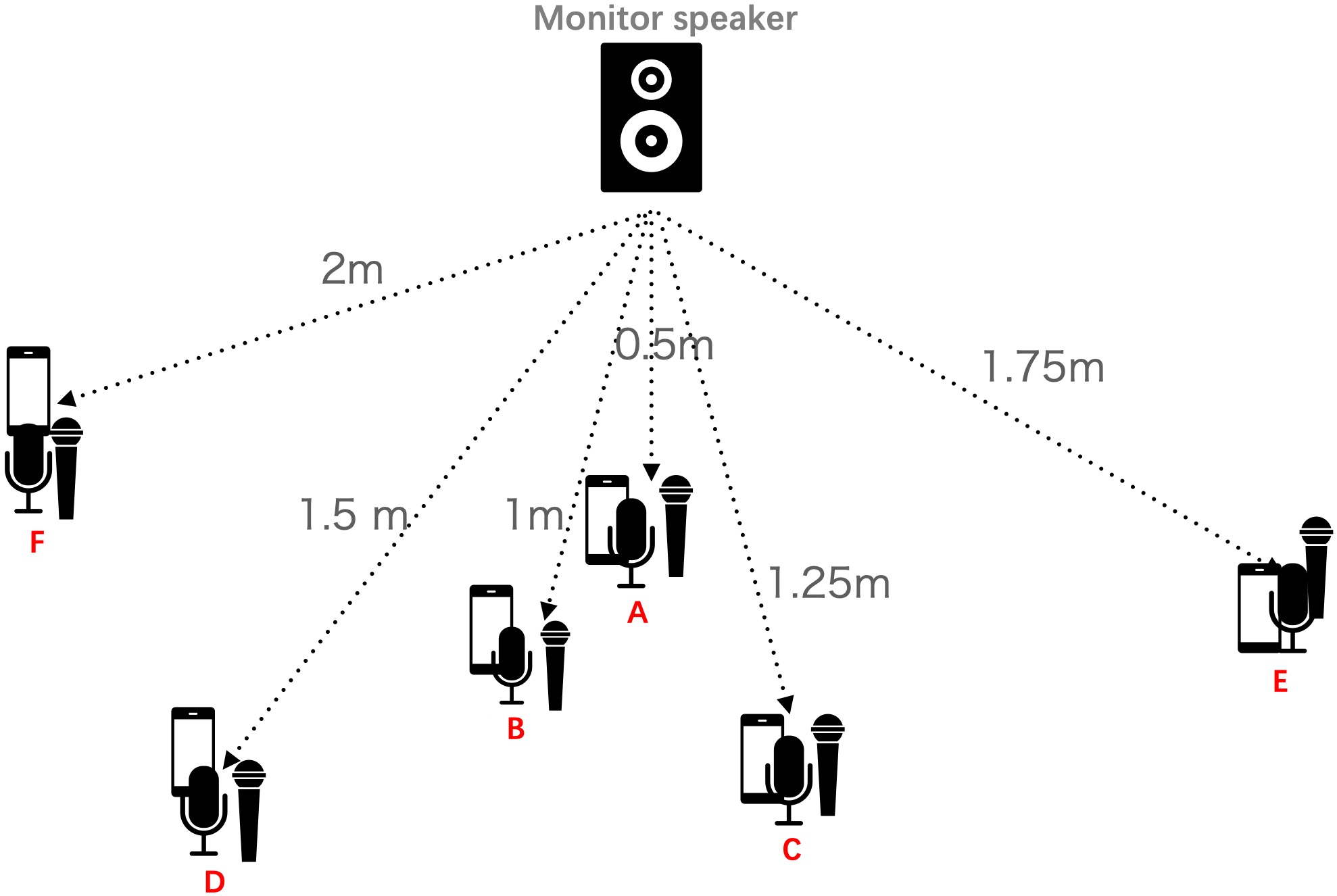
A large and growing amount of speech content in real-life scenarios is being recorded on common consumer devices in uncontrolled environments, resulting in degraded speech quality. Transforming such low-quality device-degraded speech into high-quality speech is a goal of speech enhancement (SE). This paper introduces a new speech dataset, DDS, to facilitate the research on SE. DDS provides aligned parallel recordings of high-quality speech (recorded in professional studios) and a number of versions of low-quality speech, producing approximately 2,000 hours speech data. The DDS dataset covers 27 realistic recording conditions by combining diverse acoustic environments and microphone devices, and each version of a condition consists of multiple recordings from six different microphone positions to simulate various signal-to-noise ratio (SNR) and reverberation levels. We also test several SE baseline systems on the DDS dataset and show the impact of recording diversity on performance.
翻译:在不受控制的环境中,在普通消费设备上记录到大量且越来越多的现实生活中的语音内容,导致语言质量下降; 将这种低质量设备降级的语音转换为高质量语音,是加强语音的一个目标; 本文介绍了一个新的语音数据集DDS, 以便利对SE的研究。 DDS提供高质量演讲(在专业工作室中记录)和若干版本的低质量语音的一致平行录音,产生大约2 000小时语音数据; DDS数据集结合多种声音环境和麦克风装置,涵盖27个现实的录音条件,每个条件的版本由六个不同麦克风位置的多个录音组成,以模拟各种信号对音比和回响水平。 我们还测试了DDS数据集上的若干S基线系统,并显示记录多样性对性能的影响。