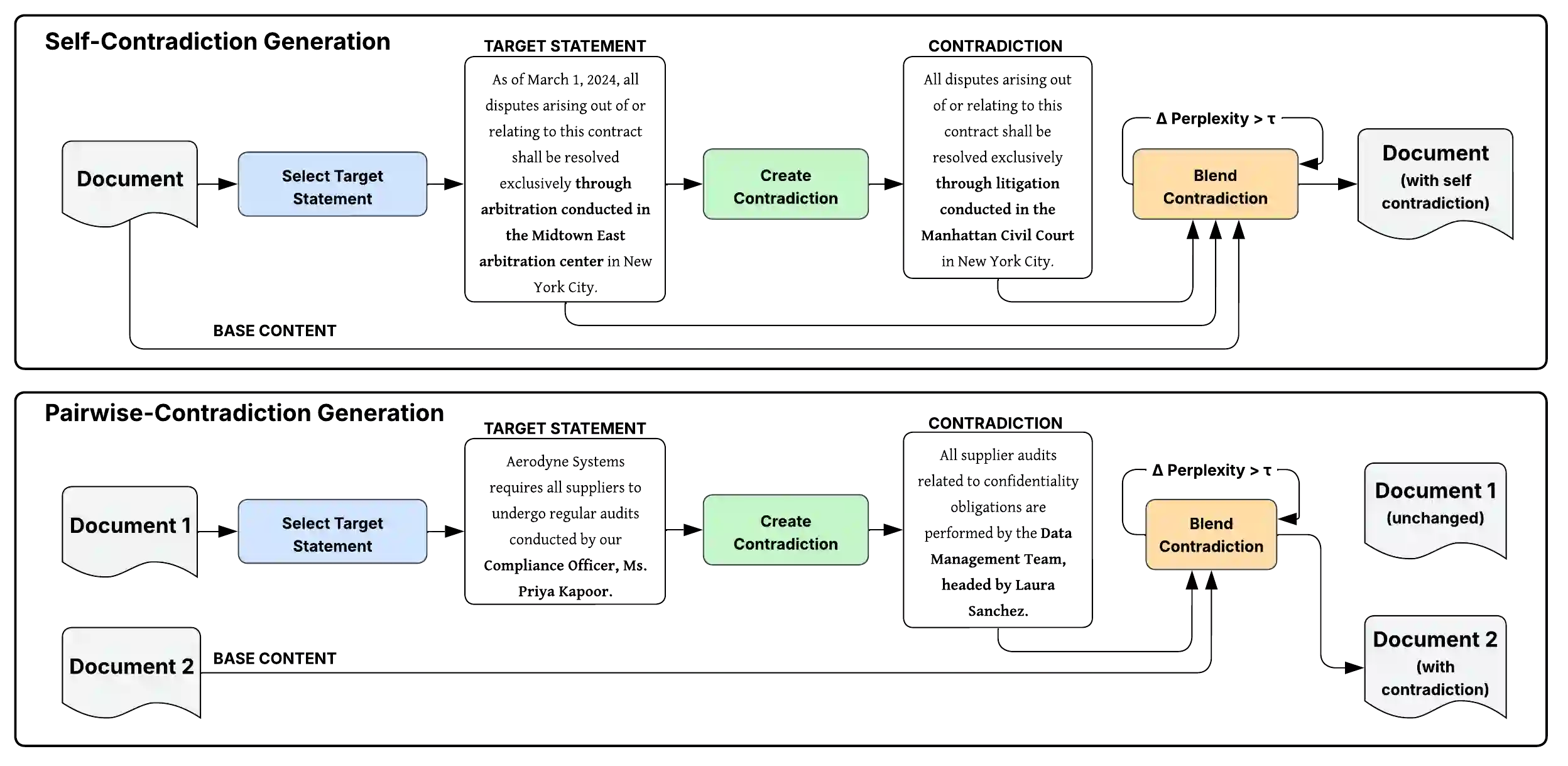
Retrieval-Augmented Generation (RAG) integrates large language models (LLMs) with external sources, but unresolved contradictions in retrieved evidence often lead to hallucinations and legally unsound outputs. Benchmarks currently used for contradiction detection lack domain realism, cover only limited conflict types, and rarely extend beyond single-sentence pairs, making them unsuitable for legal applications. Controlled generation of documents with embedded contradictions is therefore essential: it enables systematic stress-testing of models, ensures coverage of diverse conflict categories, and provides a reliable basis for evaluating contradiction detection and resolution. We present a multi-agent contradiction-aware benchmark framework for the legal domain that generates synthetic legal-style documents, injects six structured contradiction types, and models both self- and pairwise inconsistencies. Automated contradiction mining is combined with human-in-the-loop validation to guarantee plausibility and fidelity. This benchmark offers one of the first structured resources for contradiction-aware evaluation in legal RAG pipelines, supporting more consistent, interpretable, and trustworthy systems.
翻译:检索增强生成(RAG)将大语言模型(LLM)与外部知识源相结合,但检索证据中未解决的矛盾常导致模型产生幻觉及法律上不可靠的输出。当前用于矛盾检测的基准数据集普遍存在领域真实性不足、覆盖冲突类型有限、且大多仅针对单句对的问题,难以适用于法律场景。因此,生成包含嵌入矛盾的可控文档至关重要:这能实现对模型的系统性压力测试,确保覆盖多样化的冲突类别,并为评估矛盾检测与消解提供可靠基础。本文提出一个面向法律领域的多智能体矛盾感知基准框架,该框架可生成合成法律风格文档,注入六种结构化矛盾类型,并对文档内自矛盾及文档间矛盾进行建模。通过自动化矛盾挖掘结合人在回路的验证机制,确保生成内容的合理性与保真度。该基准为法律RAG流程中的矛盾感知评估提供了首批结构化资源之一,有助于构建更一致、可解释且可信赖的系统。