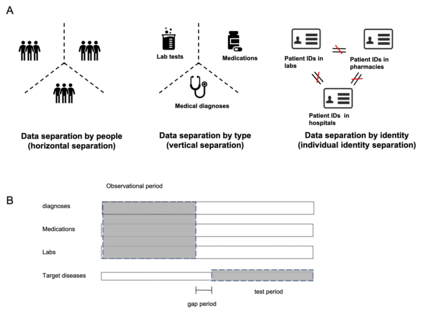
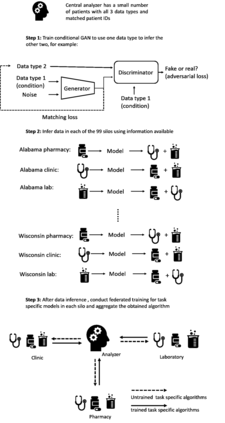
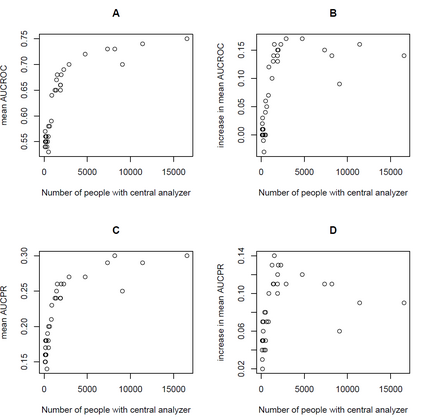
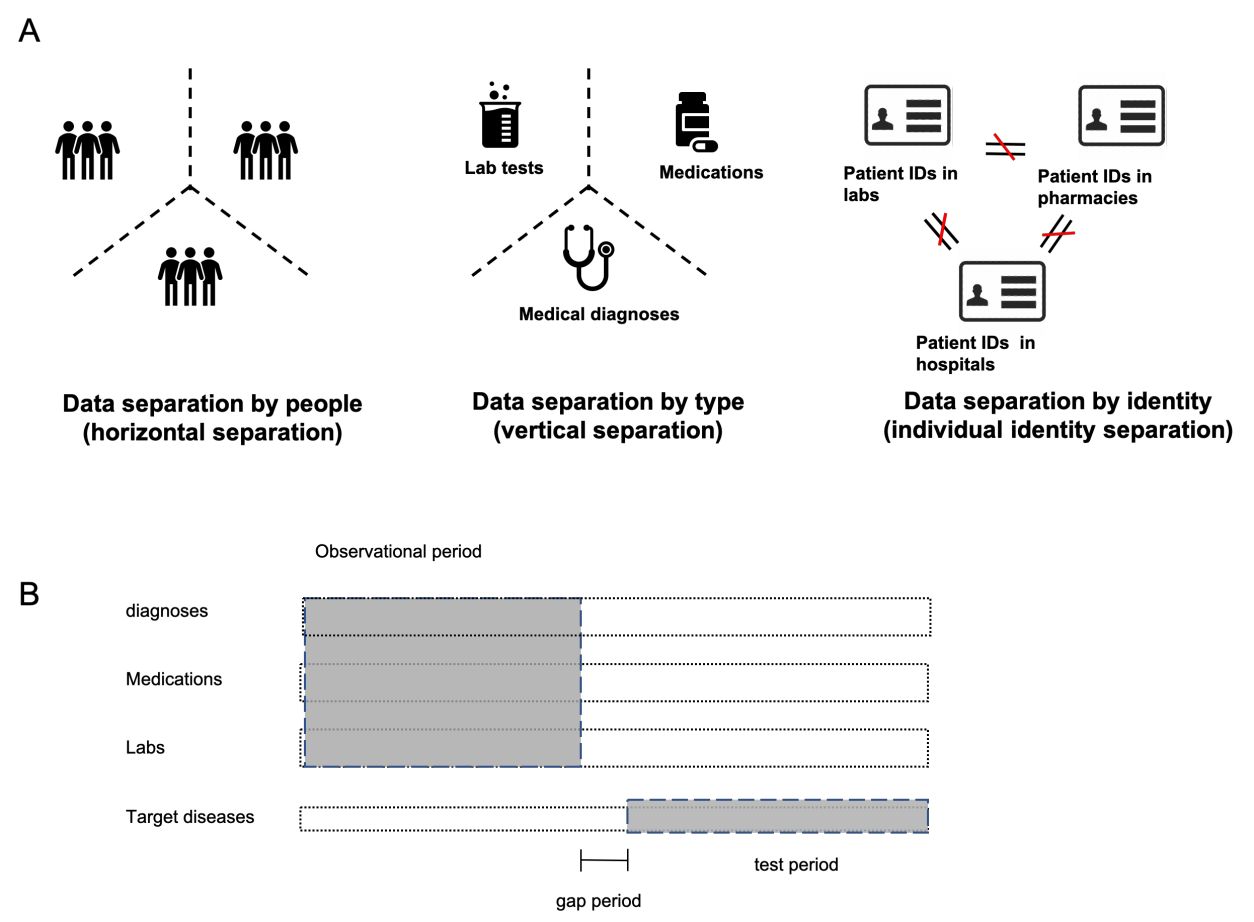
Health information is generally fragmented across silos. Though it is technically feasible to unite data for analysis in a manner that underpins a rapid learning healthcare system, privacy concerns and regulatory barriers limit data centralization. Machine learning can be conducted in a federated manner on patient datasets with the same set of variables, but separated across sites of care. But federated learning cannot handle the situation where different data types for a given patient are separated vertically across different organizations and when patient ID matching across different institutions is difficult. We call methods that enable machine learning model training on data separated by two or more degrees confederated machine learning. We proposed and evaluated a confederated learning to training machine learning model to stratify the risk of several diseases among when data are horizontally separated by individual, vertically separated by data type, and separated by identity without patient ID matching.
翻译:健康信息一般分散于各个保险井。虽然在技术上,将数据集中用于分析是可行的,可以支持快速学习保健体系,但隐私问题和监管障碍限制了数据集中。机器学习可以采用同一组变量的病人数据集联合方式进行,但可以在不同护理地点进行。但是,联邦学习无法处理以下情况:特定病人的不同数据类型在不同的组织之间垂直分离,不同机构之间的病人身份匹配很困难。我们称之为使机器学习模式培训能够通过两个或两个以上水平的联结机器学习分离的数据得以进行的方法。我们提议并评价一种联结式学习,用于培训机器学习模式,以在数据按个人、数据类型纵向分离以及没有病人身份匹配的身份分离时,分辨出几种疾病的风险。