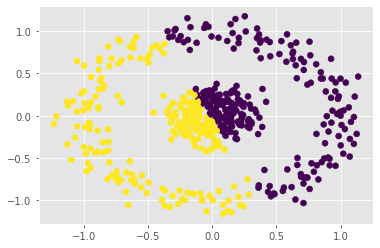
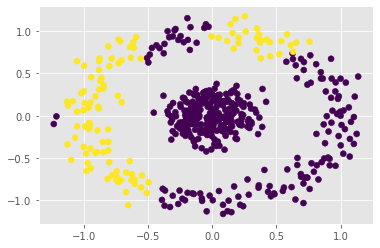
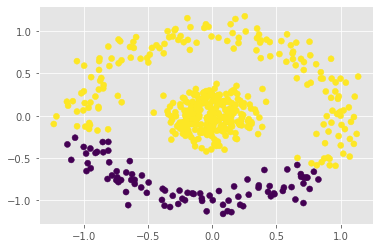
The power method is a classical algorithm with broad applications in machine learning tasks, including streaming PCA, spectral clustering, and low-rank matrix approximation. The distilled purpose of the vanilla power method is to determine the largest eigenvalue (in absolute modulus) and its eigenvector of a matrix. A momentum-based scheme can be used to accelerate the power method, but achieving an optimal convergence rate with existing algorithms critically relies on additional spectral information that is unavailable at run-time, and sub-optimal initializations can result in divergence. In this paper, we provide a pair of novel momentum-based power methods, which we call the delayed momentum power method (DMPower) and a streaming variant, the delayed momentum streaming method (DMStream). Our methods leverage inexact deflation and are capable of achieving near-optimal convergence with far less restrictive hyperparameter requirements. We provide convergence analyses for both algorithms through the lens of perturbation theory. Further, we experimentally demonstrate that DMPower routinely outperforms the vanilla power method and that both algorithms match the convergence speed of an oracle running existing accelerated methods with perfect spectral knowledge.
翻译:动力法是一种古典算法,在机器学习任务中广泛应用,包括流成的五氯苯甲醚、光谱聚集和低级矩阵近似。香草动力法的蒸馏目的是确定最大动力值(绝对模量)及其母体的成因。一个基于动力的方法可以用来加速动力法,但与现有算法实现最佳趋同率则关键依赖于在运行时无法获得的额外光谱信息,而亚最佳初始化则可能导致差异。在本文中,我们提供了一对新型动力法,我们称之为延迟动力法(DMPower)和一个流变体,即延迟动力流法(DMStream)。我们的方法具有超自然通缩效应,能够实现接近最佳的趋同,而限制性要少得多的超光谱仪要求。我们通过扰动理论的透镜为这两种算法提供趋同分析。此外,我们实验性地证明,DMPower经常超越了香草动力法,而且这两种算法都符合加速的趋同率或快速的光谱。