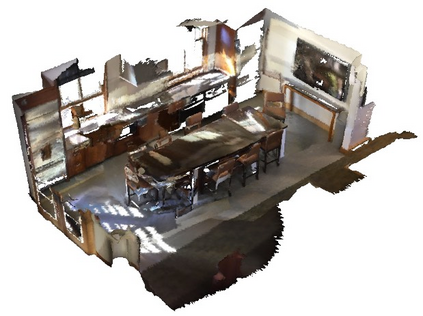
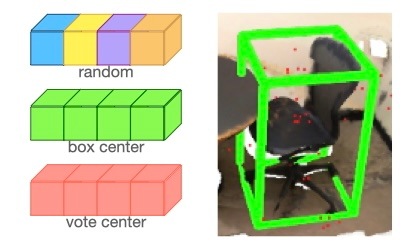
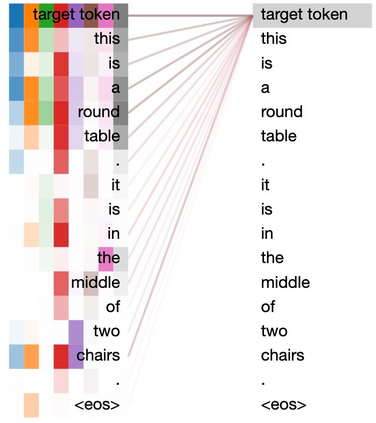
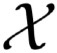Dense captioning in 3D point clouds is an emerging vision-and-language task involving object-level 3D scene understanding. Apart from coarse semantic class prediction and bounding box regression as in traditional 3D object detection, 3D dense captioning aims at producing a further and finer instance-level label of natural language description on visual appearance and spatial relations for each scene object of interest. To detect and describe objects in a scene, following the spirit of neural machine translation, we propose a transformer-based encoder-decoder architecture, namely SpaCap3D, to transform objects into descriptions, where we especially investigate the relative spatiality of objects in 3D scenes and design a spatiality-guided encoder via a token-to-token spatial relation learning objective and an object-centric decoder for precise and spatiality-enhanced object caption generation. Evaluated on two benchmark datasets, ScanRefer and ReferIt3D, our proposed SpaCap3D outperforms the baseline method Scan2Cap by 4.94% and 9.61% in CIDEr@0.5IoU, respectively. Our project page with source code and supplementary files is available at https://SpaCap3D.github.io/ .
翻译:3D点云层的浓度字幕是一个新兴的视觉和语言任务,涉及对象级 3D 场景理解。除了传统的 3D 物体探测中粗略的语义类预测和捆绑框回归外, 3D 稠密字幕旨在为每个感兴趣的场景对象制作关于视觉外观和空间关系的自然语言描述的进一步和细微实例级实例级标签。 要在一个场景中探测和描述对象,遵循神经机器翻译的精神, 我们提议一个基于变压器的编码器-解码结构, 即 Spa Cap3D, 将对象转换为描述, 以便特别调查 3D 场景中天体的相对空间性, 并设计一个空间指导编码器, 通过象征性到点的空间关系学习目标, 以及一个精确和空间增强的物体标题生成对象中心解码。 我们提议的 Spa Cap3D 将基准方法Scamp2Cap 转换为4.94 % 和 9.61% CIDER@ 0.5DU.