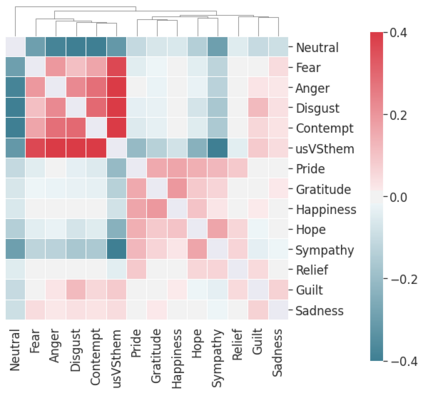
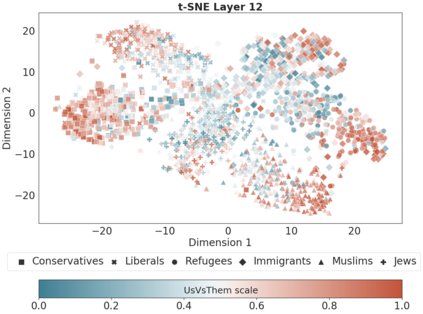
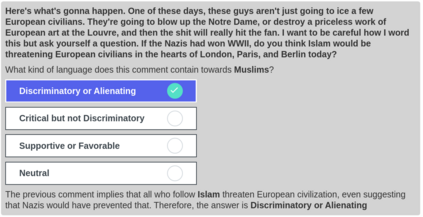
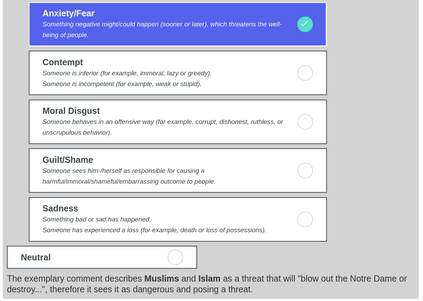
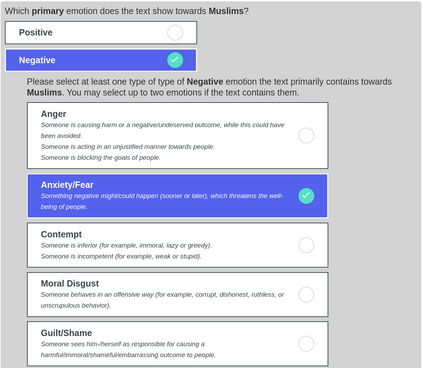
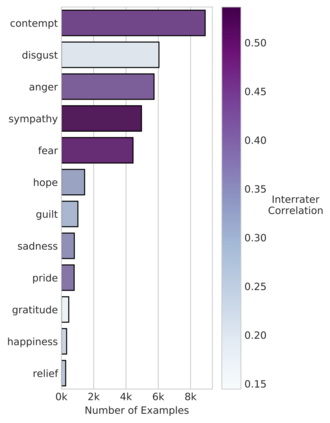
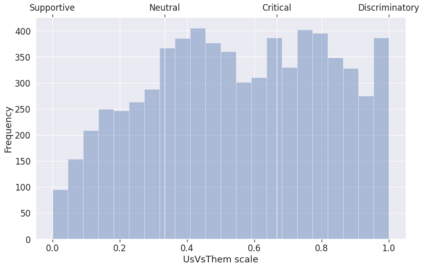
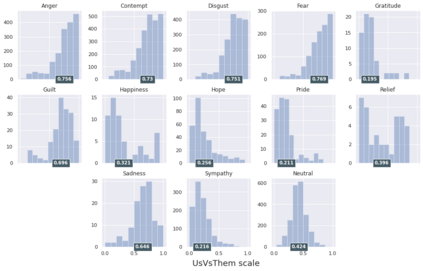
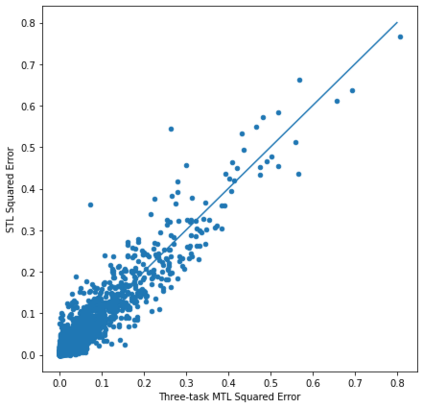
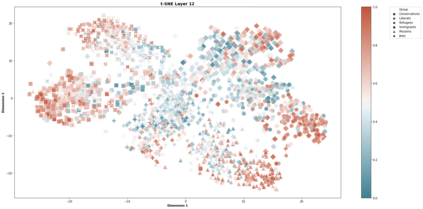
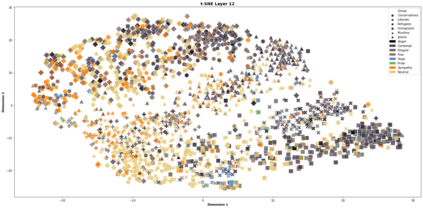
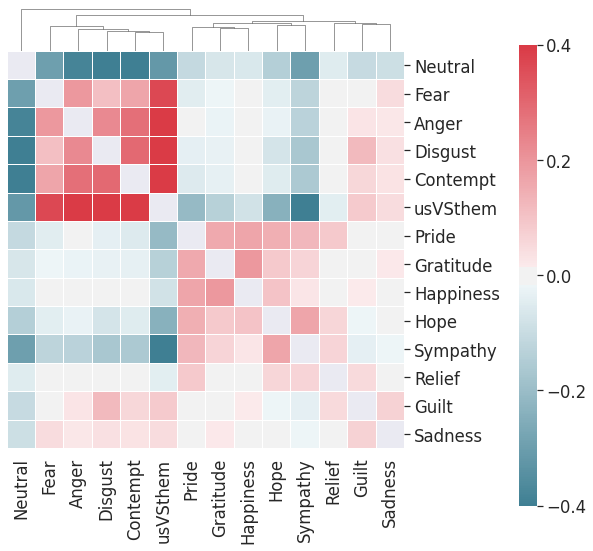
Computational modelling of political discourse tasks has become an increasingly important area of research in natural language processing. Populist rhetoric has risen across the political sphere in recent years; however, computational approaches to it have been scarce due to its complex nature. In this paper, we present the new Us vs. Them dataset, consisting of 6861 Reddit comments annotated for populist attitudes and the first large-scale computational models of this phenomenon. We investigate the relationship between populist mindsets and social groups, as well as a range of emotions typically associated with these. We set a baseline for two tasks related to populist attitudes and present a set of multi-task learning models that leverage and demonstrate the importance of emotion and group identification as auxiliary tasks.
翻译:政治话语任务的计算模型已成为自然语言处理研究中日益重要的领域。近年来,民粹主义言论在政治领域抬头;然而,由于其复杂性质,对它采取的计算方法很少。我们在本文件中介绍了新的Us诉Them数据集,其中包括6861篇关于民粹主义态度的注释评论和这一现象的第一个大规模计算模型。我们调查民粹主义思想与社会群体之间的关系,以及通常与此相关的一系列情感。我们为与民粹主义态度有关的两项任务确定了基准,并提出了一套多任务学习模式,这些模式利用并展示了情感和群体识别作为辅助任务的重要性。