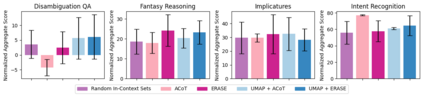
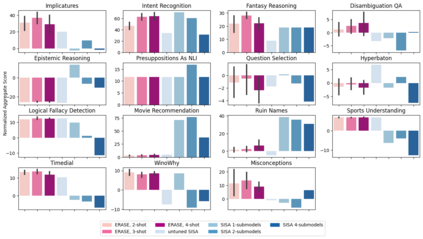
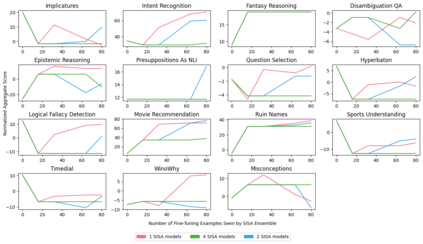
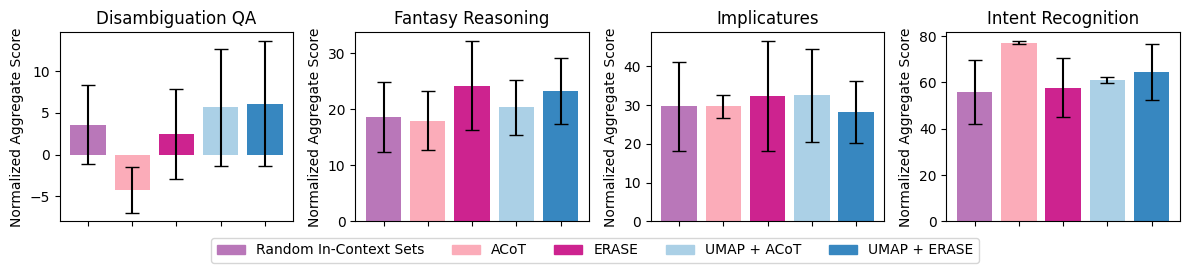
Machine unlearning is a desirable operation as models get increasingly deployed on data with unknown provenance. However, achieving exact unlearning -- obtaining a model that matches the model distribution when the data to be forgotten was never used -- is challenging or inefficient, often requiring significant retraining. In this paper, we focus on efficient unlearning methods for the task adaptation phase of a pretrained large language model (LLM). We observe that an LLM's ability to do in-context learning for task adaptation allows for efficient exact unlearning of task adaptation training data. We provide an algorithm for selecting few-shot training examples to prepend to the prompt given to an LLM (for task adaptation), ERASE, whose unlearning operation cost is independent of model and dataset size, meaning it scales to large models and datasets. We additionally compare our approach to fine-tuning approaches and discuss the trade-offs between the two approaches. This leads us to propose a new holistic measure of unlearning cost which accounts for varying inference costs, and conclude that in-context learning can often be more favourable than fine-tuning for deployments involving unlearning requests.
翻译:暂无翻译