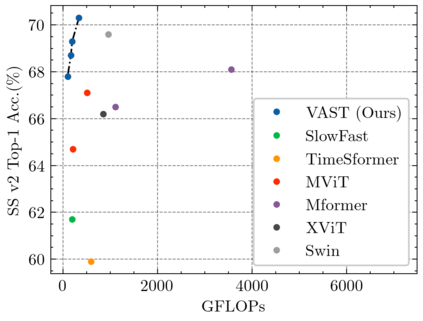
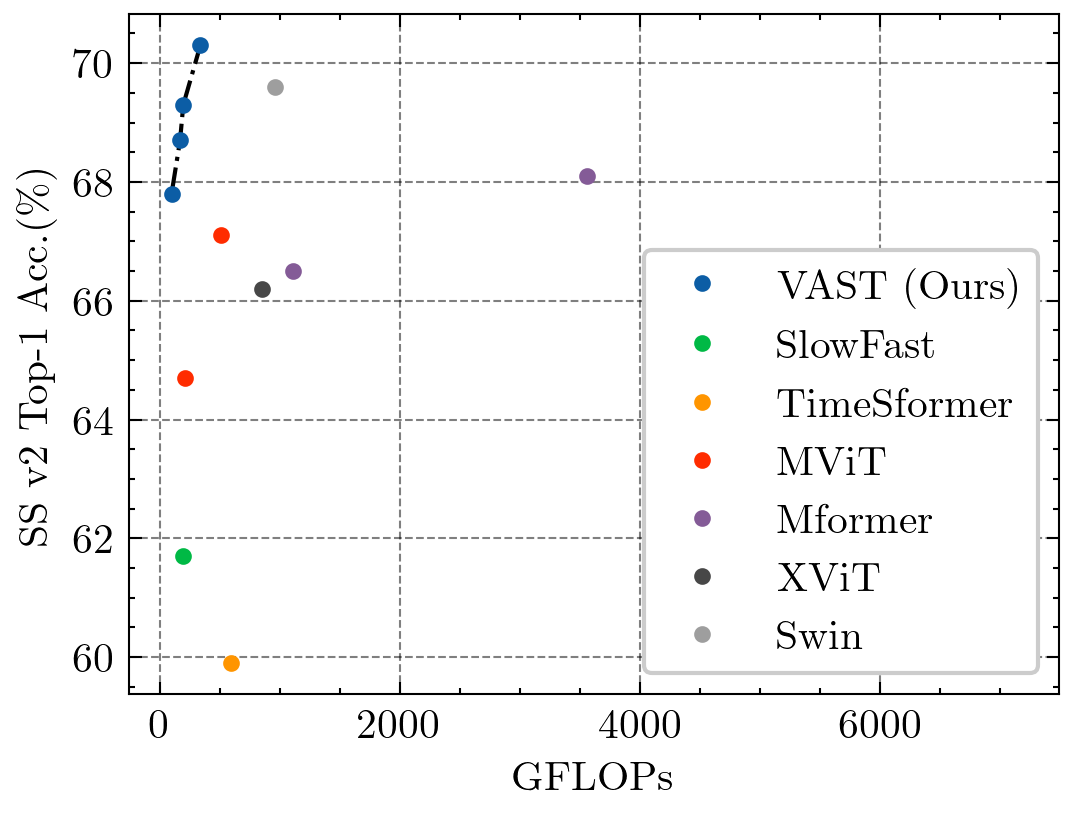
This paper tackles the problem of efficient video recognition. In this area, video transformers have recently dominated the efficiency (top-1 accuracy vs FLOPs) spectrum. At the same time, there have been some attempts in the image domain which challenge the necessity of the self-attention operation within the transformer architecture, advocating the use of simpler approaches for token mixing. However, there are no results yet for the case of video recognition, where the self-attention operator has a significantly higher impact (compared to the case of images) on efficiency. To address this gap, in this paper, we make the following contributions: (a) we construct a highly efficient \& accurate attention-free block based on the shift operator, coined Affine-Shift block, specifically designed to approximate as closely as possible the operations in the MHSA block of a Transformer layer. Based on our Affine-Shift block, we construct our Affine-Shift Transformer and show that it already outperforms all existing shift/MLP--based architectures for ImageNet classification. (b) We extend our formulation in the video domain to construct Video Affine-Shift Transformer (VAST), the very first purely attention-free shift-based video transformer. (c) We show that VAST significantly outperforms recent state-of-the-art transformers on the most popular action recognition benchmarks for the case of models with low computational and memory footprint. Code will be made available.
翻译:本文解决了高效视频识别的问题。 在这一领域, 视频变压器最近控制了效率( 顶层-1 准确性相对于 FLOPs) 频谱。 同时, 在图像域中也有一些尝试, 挑战变压器结构内自我关注操作的必要性, 主张使用更简单的方法进行象征性混合。 但是, 在视频识别方面还没有结果, 自我关注操作器对效率的影响( 与图像相比) 显著提高 。 为了解决这一差距, 我们在本文件中做出以下贡献:(a) 我们根据变换操作器, 创建了一个高效的 准确的无关注区块。 创建了 Affine- Shift 区, 具体旨在尽可能接近变压器层中 MHSA 块的操作。 但是, 在我们的 Affine- Shift 区块上, 我们建造了我们的 Affine- Shift 变压器, 显示它已经超越了所有基于大众变压/ MLP 的图像网络分类架构 。 (b) 我们将最新的变压式变压式变压式变压式变压式变压式变压器动作的模型的模型的配置, 将大大地显示变压式变压式变压式变压式变压式变压式的图像网络。