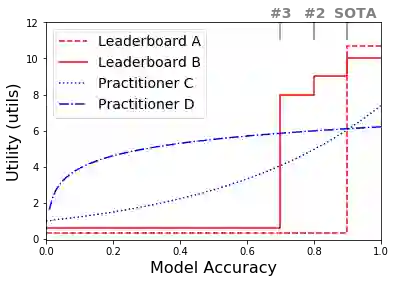
Benchmarks such as GLUE have helped drive advances in NLP by incentivizing the creation of more accurate models. While this leaderboard paradigm has been remarkably successful, a historical focus on performance-based evaluation has been at the expense of other qualities that the NLP community values in models, such as compactness, fairness, and energy efficiency. In this opinion paper, we study the divergence between what is incentivized by leaderboards and what is useful in practice through the lens of microeconomic theory. We frame both the leaderboard and NLP practitioners as consumers and the benefit they get from a model as its utility to them. With this framing, we formalize how leaderboards -- in their current form -- can be poor proxies for the NLP community at large. For example, a highly inefficient model would provide less utility to practitioners but not to a leaderboard, since it is a cost that only the former must bear. To allow practitioners to better estimate a model's utility to them, we advocate for more transparency on leaderboards, such as the reporting of statistics that are of practical concern (e.g., model size, energy efficiency, and inference latency).
翻译:GLUE等基准通过激励创建更准确的模式,推动了国家劳工政策的进展。虽然这一领导板模式非常成功,但以往对业绩评估的重视一直以牺牲国家劳工政策社区在模型中的价值的其他品质为代价,如紧凑性、公平性和能源效率等。在本意见文件中,我们研究了由领导板激励的因素与从微观经济理论的角度来看实际有用的因素之间的差异。我们把领导板和全国劳工政策执行者看成是消费者,他们从一个模型中获得的收益是他们的效用。有了这一框架,我们正式确定领导板 -- -- 以其目前的形式 -- -- 如何成为整个国家劳工政策社区贫穷的代用品。例如,一个效率极高的模式将减少从业人员的效用,而不是领导板,因为只有前者必须承担成本。为了让执行者更好地估计一个模型对它们的效用,我们主张在领导板上增加透明度,例如报告具有实际关注的统计资料(例如,模型大小、能源效率)等。