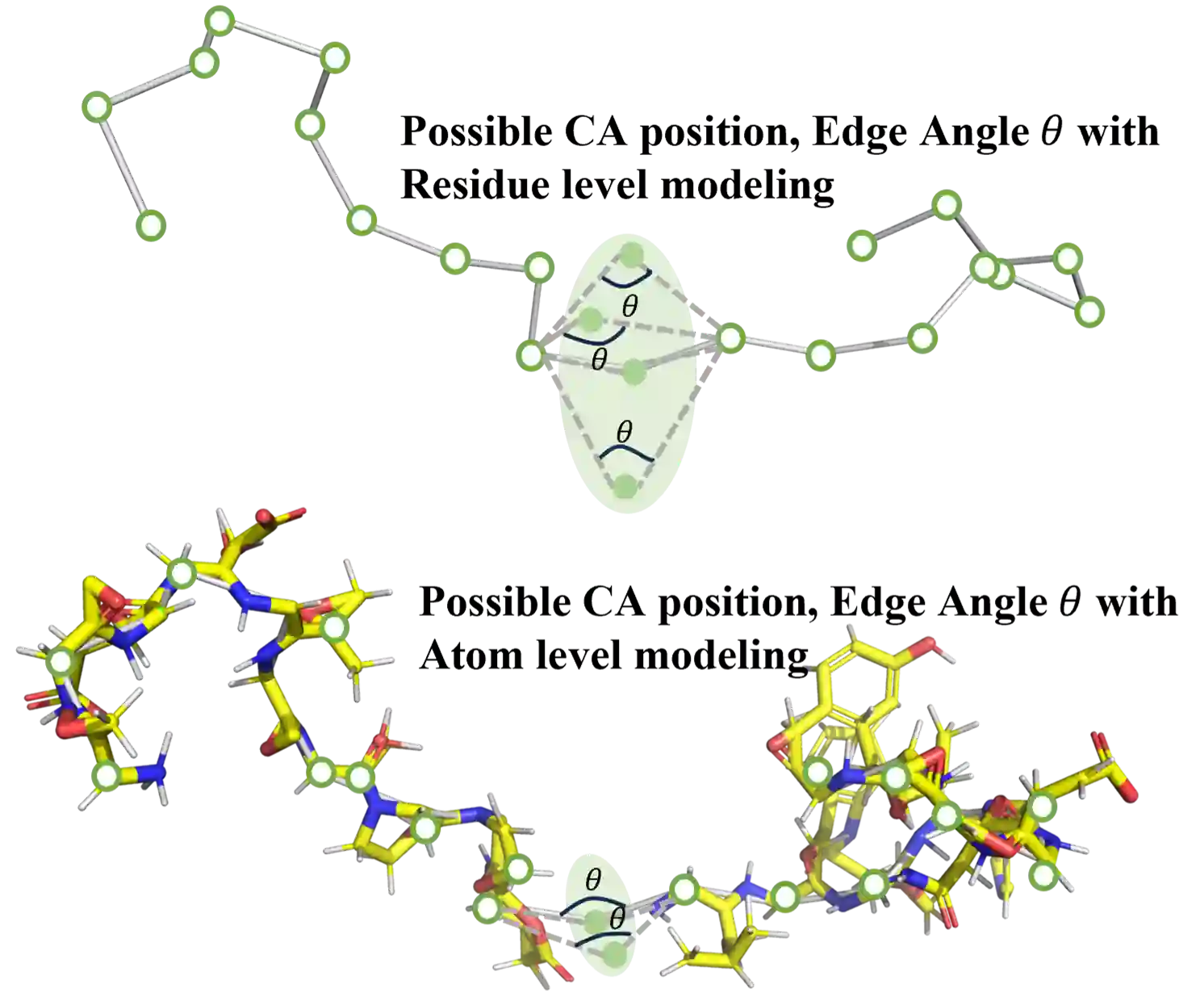
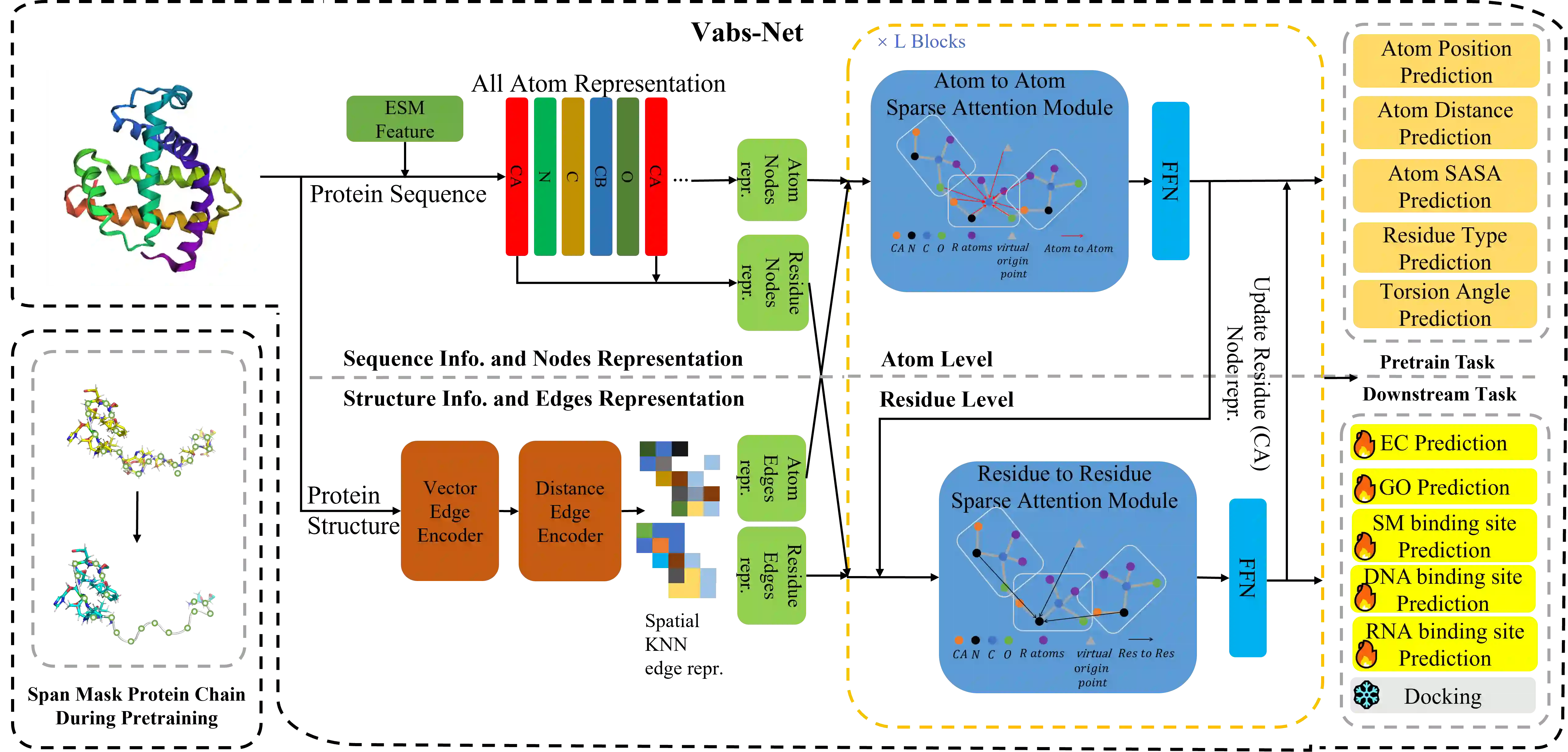
In recent years, there has been a surge in the development of 3D structure-based pre-trained protein models, representing a significant advancement over pre-trained protein language models in various downstream tasks. However, most existing structure-based pre-trained models primarily focus on the residue level, i.e., alpha carbon atoms, while ignoring other atoms like side chain atoms. We argue that modeling proteins at both residue and atom levels is important since the side chain atoms can also be crucial for numerous downstream tasks, for example, molecular docking. Nevertheless, we find that naively combining residue and atom information during pre-training typically fails. We identify a key reason is the information leakage caused by the inclusion of atom structure in the input, which renders residue-level pre-training tasks trivial and results in insufficiently expressive residue representations. To address this issue, we introduce a span mask pre-training strategy on 3D protein chains to learn meaningful representations of both residues and atoms. This leads to a simple yet effective approach to learning protein representation suitable for diverse downstream tasks. Extensive experimental results on binding site prediction and function prediction tasks demonstrate our proposed pre-training approach significantly outperforms other methods. Our code will be made public.
翻译:暂无翻译