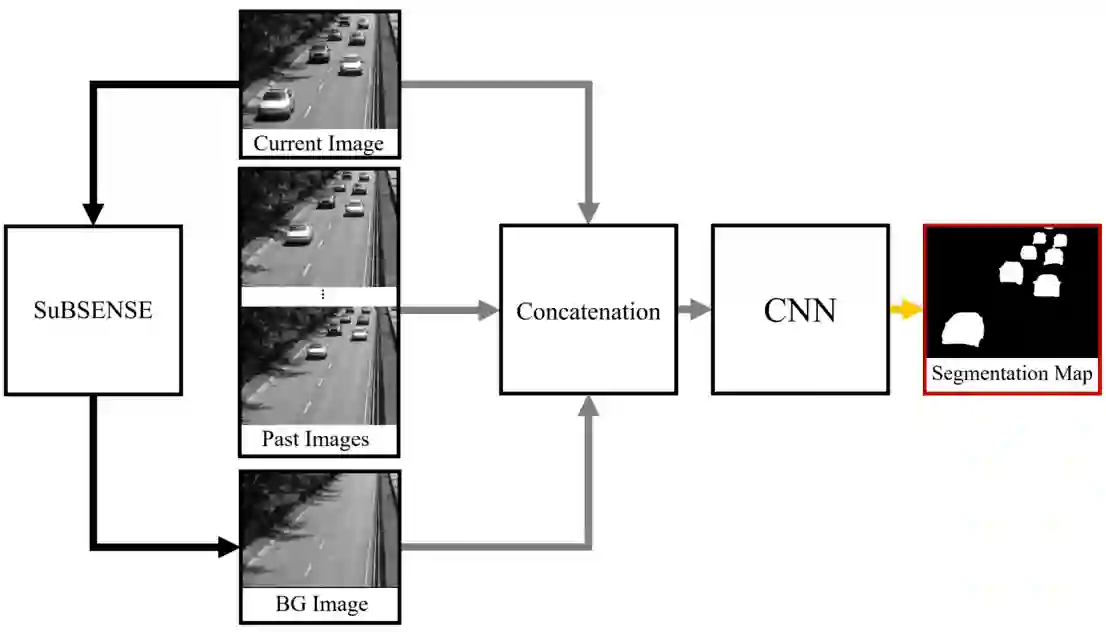
Visual surveillance aims to stably detect a foreground object using a continuous image acquired from a fixed camera. Recent deep learning methods based on supervised learning show superior performance compared to classical background subtraction algorithms. However, there is still a room for improvement in static foreground, dynamic background, hard shadow, illumination changes, camouflage, etc. In addition, most of the deep learning-based methods operates well on environments similar to training. If the testing environments are different from training ones, their performance degrades. As a result, additional training on those operating environments is required to ensure a good performance. Our previous work which uses spatio-temporal input data consisted of a number of past images, background images and current image showed promising results in different environments from training, although it uses a simple U-NET structure. In this paper, we propose a data augmentation technique suitable for visual surveillance for additional performance improvement using the same network used in our previous work. In deep learning, most data augmentation techniques deal with spatial-level data augmentation techniques for use in image classification and object detection. In this paper, we propose a new method of data augmentation in the spatio-temporal dimension suitable for our previous work. Two data augmentation methods of adjusting background model images and past images are proposed. Through this, it is shown that performance can be improved in difficult areas such as static foreground and ghost objects, compared to previous studies. Through quantitative and qualitative evaluation using SBI, LASIESTA, and our own dataset, we show that it gives superior performance compared to deep learning-based algorithms and background subtraction algorithms.
翻译:视觉监控的目的是利用从固定相机中获取的连续图像,对浅色物体进行细微的探测。最近根据监督下的学习方法显示,与古典背景减色算法相比,我们以往的深层学习方法表现优异。然而,静地前景、动态背景、硬阴影、照明变化、迷彩等方面仍有改进的空间。此外,大多数深层学习方法在与培训相似的环境中运作良好。如果测试环境与培训环境不同,其性能会退化。因此,需要对这些操作环境进行更多的培训,以确保良好的性能。我们以前使用时空输入数据数据的数据数据数据数据数据显示在不同的环境中,包括一些过去的图像、背景图像和当前图像。尽管它使用简单的 U-NET 结构。此外,我们在本文中提议了一种数据增强技术,以便利用与培训相同的网络进行更多的性能监测。在深层学习中,大多数数据增强技术处理空间级数据增强技术,用于图像的更深层分类和对象检测。在本文中,我们提出了一种新的数据增强方法,在空间-时间-时间-时间输入新的数据模型模型,在从深层-图像中显示自上比较的高级的性分析,在以往的图像中,我们所显示的性平面上显示的改进的性能的性平面图像,在以往的性能方面,可以显示的性能分析,在以往的性能方面,我们所显示的性能上显示的性能的性能的性能的性能的性能的性能的性能的性能评估。