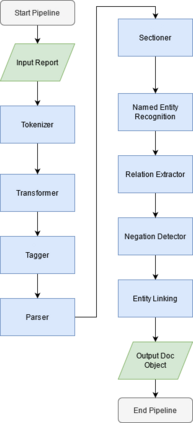
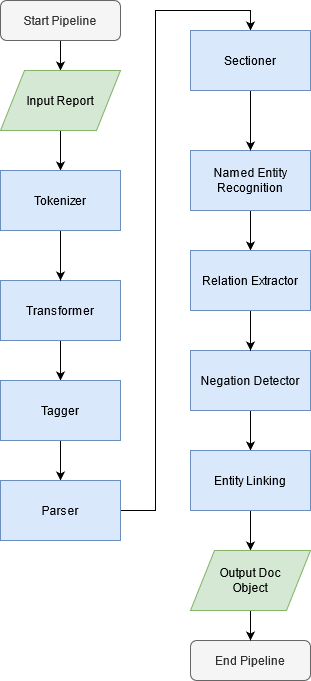
The use of electronic health records in medical research is difficult because of the unstructured format. Extracting information within reports and summarising patient presentations in a way amenable to downstream analysis would be enormously beneficial for operational and clinical research. In this work we present a natural language processing pipeline for information extraction of radiological reports in neurology. Our pipeline uses a hybrid sequence of rule-based and artificial intelligence models to accurately extract and summarise neurological reports. We train and evaluate a custom language model on a corpus of 150000 radiological reports from National Hospital for Neurology and Neurosurgery, London MRI imaging. We also present results for standard NLP tasks on domain-specific neuroradiology datasets. We show our pipeline, called `neuroNLP', can reliably extract clinically relevant information from these reports, enabling downstream modelling of reports and associated imaging on a heretofore unprecedented scale.
翻译:在医学研究中使用电子健康记录是困难的,因为没有结构化的格式。在报告内提取信息,并以适合下游分析的方式对病人的介绍进行总结,对业务和临床研究大有裨益。在这项工作中,我们提出了神经学辐射报告信息提取的自然语言处理管道。我们的管道使用基于规则的和人工的智能模型混合序列来准确提取和总结神经学报告。我们培训和评价了一套15万份来自伦敦神经学和神经外科国家医院的放射报告集的定制语言模型。我们还介绍了用于具体领域神经放射学数据集的标准国家实验室任务的结果。我们展示了我们的管道,称为“NeuroNLP”,能够可靠地从这些报告中提取与临床相关的信息,从而能够以前所未有的规模对报告和相关成像进行下游建模。