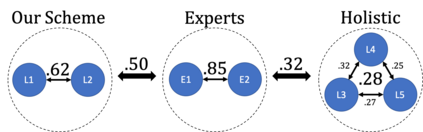
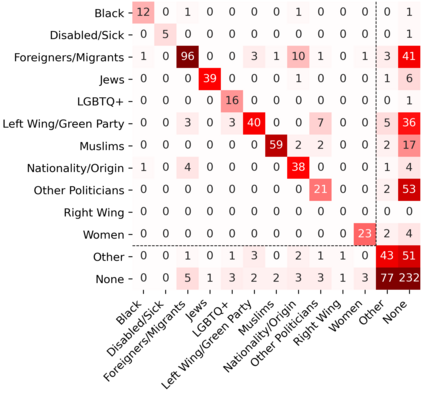
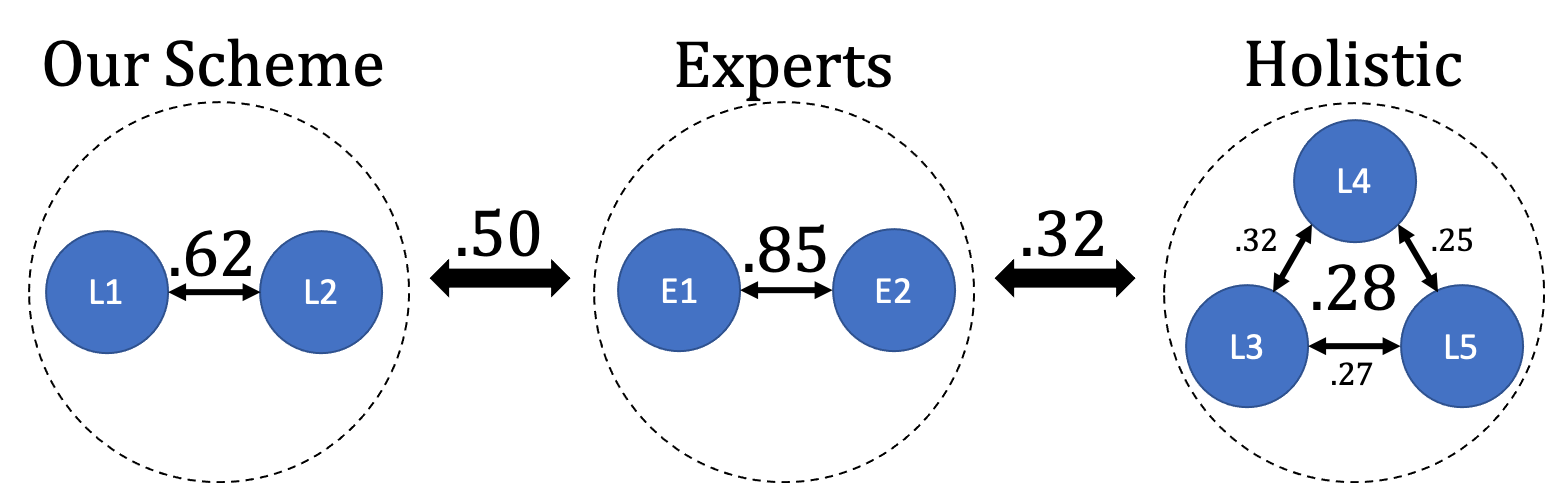
We propose a 'legal approach' to hate speech detection by operationalization of the decision as to whether a post is subject to criminal law into an NLP task. Comparing existing regulatory regimes for hate speech, we base our investigation on the European Union's framework as it provides a widely applicable legal minimum standard. Accurately judging whether a post is punishable or not usually requires legal training. We show that, by breaking the legal assessment down into a series of simpler sub-decisions, even laypersons can annotate consistently. Based on a newly annotated dataset, our experiments show that directly learning an automated model of punishable content is challenging. However, learning the two sub-tasks of `target group' and `targeting conduct' instead of an end-to-end approach to punishability yields better results. Overall, our method also provides decisions that are more transparent than those of end-to-end models, which is a crucial point in legal decision-making.
翻译:我们建议采取“法律办法”来发现仇恨言论,具体做法是将关于某一职位是否受刑法约束的决定落实到国家语言网站的任务中。比较现有的关于仇恨言论的监管制度,我们根据欧洲联盟框架进行调查,因为欧盟框架提供了广泛适用的法律最低标准。准确地判断某一职位是否应予处罚或通常不需要法律培训。我们表明,通过将法律评估打破为一系列更简单的次级决定,甚至非专业人士也能够始终不断地进行批注。根据新的附加说明的数据集,我们的实验表明,直接学习一个自动的、可惩罚的内容模式是具有挑战性的。然而,学习“目标群体”和“定向行为”的两种次级任务,而不是以端对端方法来惩罚效果更好。总的来说,我们的方法也提供了比端对端模式更透明的决定,这是法律决策的一个关键点。