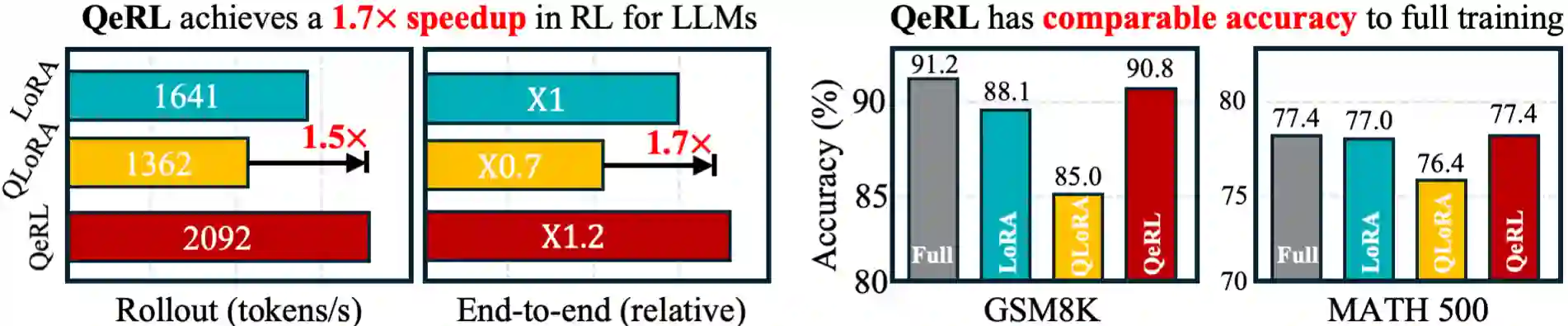
We propose QeRL, a Quantization-enhanced Reinforcement Learning framework for large language models (LLMs). While RL is essential for LLMs' reasoning capabilities, it is resource-intensive, requiring substantial GPU memory and long rollout durations. QeRL addresses these issues by combining NVFP4 quantization with Low-Rank Adaptation (LoRA), accelerating rollout phase of RL while reducing memory overhead. Beyond efficiency, our findings show that quantization noise increases policy entropy, enhancing exploration, and enabling the discovery of better strategies during RL. To further optimize exploration, QeRL introduces an Adaptive Quantization Noise (AQN) mechanism, which dynamically adjusts noise during training. Experiments demonstrate that QeRL delivers over 1.5 times speedup in the rollout phase. Moreover, this is the first framework to enable RL training of a 32B LLM on a single H100 80GB GPU, while delivering overall speedups for RL training. It also achieves faster reward growth and higher final accuracy than 16-bit LoRA and QLoRA, while matching the performance of full-parameter fine-tuning on mathematical benchmarks such as GSM8K (90.8%) and MATH 500 (77.4%) in the 7B model. These results establish QeRL as an efficient and effective framework for RL training in LLMs.
翻译:我们提出了QeRL,一种面向大语言模型(LLMs)的量化增强强化学习框架。虽然强化学习对于LLMs的推理能力至关重要,但其资源消耗巨大,需要大量的GPU内存和较长的推演时长。QeRL通过结合NVFP4量化与低秩适应(LoRA),解决了这些问题,加速了强化学习的推演阶段,同时降低了内存开销。除了效率提升之外,我们的研究发现量化噪声增加了策略熵,从而增强了探索能力,使得在强化学习过程中能够发现更优的策略。为了进一步优化探索,QeRL引入了自适应量化噪声(AQN)机制,该机制在训练过程中动态调整噪声。实验表明,QeRL在推演阶段实现了超过1.5倍的加速。此外,这是首个能够在单张H100 80GB GPU上对320亿参数LLM进行强化学习训练的框架,同时为强化学习训练带来了整体加速。与16位LoRA和QLoRA相比,它实现了更快的奖励增长和更高的最终准确率,并且在7B模型上,在GSM8K(90.8%)和MATH 500(77.4%)等数学基准测试中,其性能与全参数微调相当。这些结果确立了QeRL作为一个高效且有效的LLM强化学习训练框架的地位。