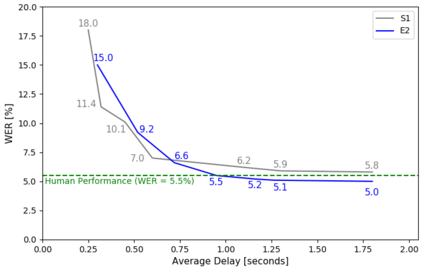
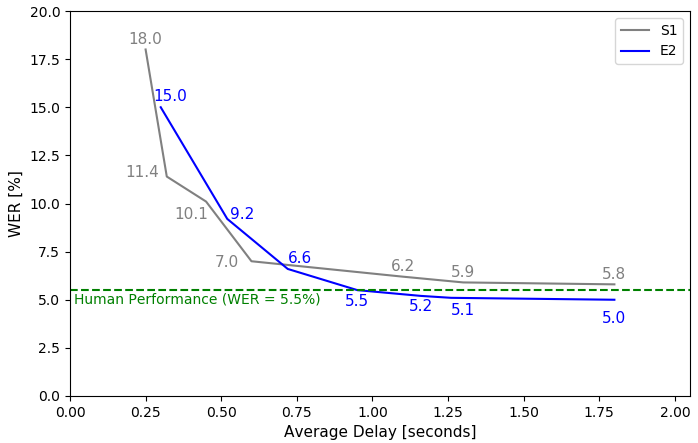
Achieving super-human performance in recognizing human speech has been a goal for several decades, as researchers have worked on increasingly challenging tasks. In the 1990's it was discovered, that conversational speech between two humans turns out to be considerably more difficult than read speech as hesitations, disfluencies, false starts and sloppy articulation complicate acoustic processing and require robust handling of acoustic, lexical and language context, jointly. Early attempts with statistical models could only reach error rates over 50% and far from human performance (WER of around 5.5%). Neural hybrid models and recent attention-based encoder-decoder models have considerably improved performance as such contexts can now be learned in an integral fashion. However, processing such contexts requires an entire utterance presentation and thus introduces unwanted delays before a recognition result can be output. In this paper, we address performance as well as latency. We present results for a system that can achieve super-human performance (at a WER of 5.0%, over the Switchboard conversational benchmark) at a word based latency of only 1 second behind a speaker's speech. The system uses multiple attention-based encoder-decoder networks integrated within a novel low latency incremental inference approach.
翻译:数十年来,随着研究人员致力于越来越具有挑战性的任务,在承认人类言论方面实现超人性表现一直是一项目标。在1990年代,人们发现,由于犹豫、失常、虚假开场和草率的表达使声学处理复杂化,共同需要严格处理声学、词汇和语言背景,因此两个人之间的谈话演讲比阅读演讲困难得多。早期的统计模型尝试只能达到50%以上的误差率,远远达不到人类的性能(5.5%左右)。神经混合模型和最近基于注意力的编码脱coder模型大大改进了性能,因为现在可以以整体的方式学习这种环境。然而,处理这种背景需要整个发声演示,从而造成不必要的延误,然后才能产生确认结果。在本文中,我们谈到性能和耐久性。我们为能够实现超人性性能的系统(5.0%的WER,超过交换台的谈话基准)提供了结果,只有1秒长的词本,在演讲者演讲后才使用惯性词。系统使用多种基于注意的编码网络,在低小的语音中采用渐进式网络内使用多重的递增度。