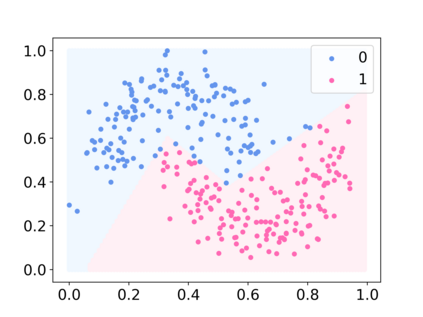
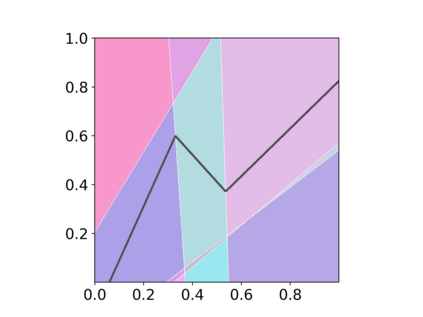
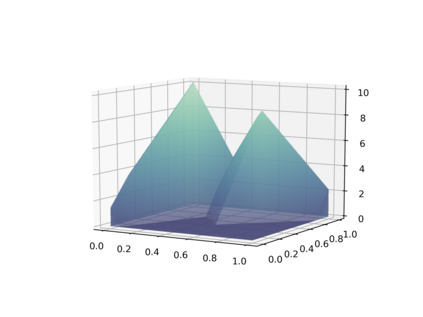
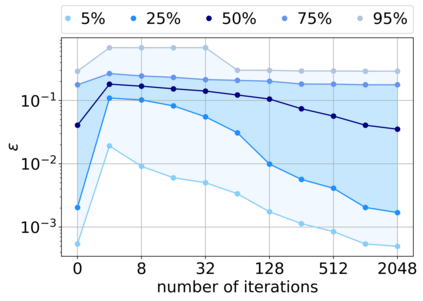
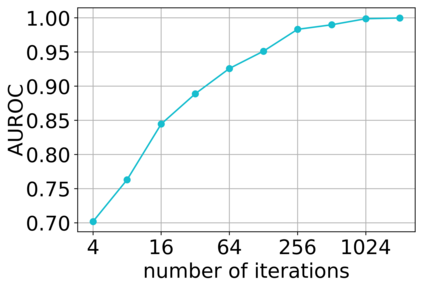
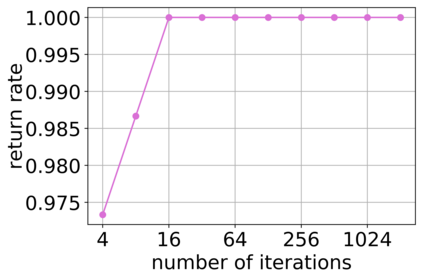
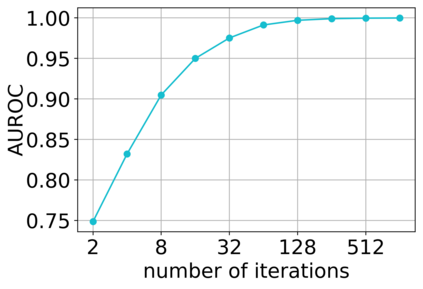
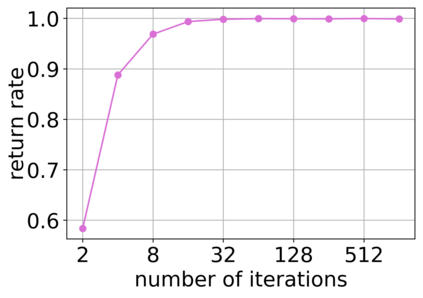
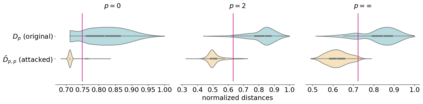
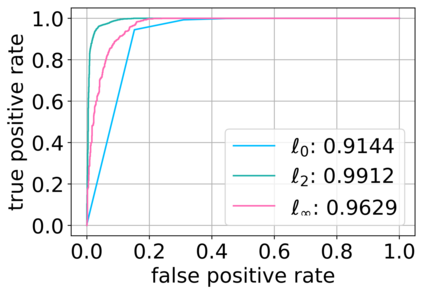
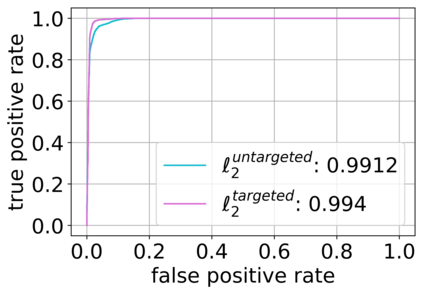
Deep neural networks (DNNs) have proven to be powerful tools for processing unstructured data. However for high-dimensional data, like images, they are inherently vulnerable to adversarial attacks. Small almost invisible perturbations added to the input can be used to fool DNNs. Various attacks, hardening methods and detection methods have been introduced in recent years. Notoriously, Carlini-Wagner (CW) type attacks computed by iterative minimization belong to those that are most difficult to detect. In this work we outline a mathematical proof that the CW attack can be used as a detector itself. That is, under certain assumptions and in the limit of attack iterations this detector provides asymptotically optimal separation of original and attacked images. In numerical experiments, we experimentally validate this statement and furthermore obtain AUROC values up to 99.73% on CIFAR10 and ImageNet. This is in the upper part of the spectrum of current state-of-the-art detection rates for CW attacks.
翻译:深神经网络(DNNS)已被证明是处理非结构化数据的有力工具。 然而,对于高维数据,例如图像,它们本身就容易受到对抗性攻击。输入中添加的几乎看不见的微小扰动可以用来愚弄DNNS。近年来,已经采用了各种攻击、加固方法和探测方法。值得注意的是,通过迭代最小化计算出来的Carlini-Wagner(CW)型攻击属于最难以探测的。在这项工作中,我们勾勒出一个数学证据,证明CW攻击可以用作探测器本身。根据某些假设和攻击性迭代的限度,该探测器提供原始图像和被攻击图像的无症状最佳分离。在数字实验中,我们实验性地验证了这一声明,并在CIFAR10和图像网络中获得了高达99.73%的AUROC值。这是目前CW攻击的状态探测率最高峰。