NeurIPS 2018最佳论文发布:华为诺亚方舟实验室等获奖,加拿大实力凸显
夏乙 问耕 发自 凹非寺
量子位 出品 | 公众号 QbitAI

第31届神经信息处理系统大会(NeurIPS 2018),今天正式开幕。
刚刚,4篇最佳论文奖、1篇时间检验奖悉数颁出。今年的最佳论文共有四篇。
其中有一篇的一作,来自华为诺亚方舟实验室,另外这四篇论文以及作者的履历,大多与加拿大的大学有关,凸显了加拿大在人工智能领域的实力。
这个大会,就是原来的人工智能顶级会议NIPS,今年不仅有了全新简称NeurIPS,还有全新LOGO:左上角的N变成了一个Vr。
我们先来看看今年的奖项都发给了谁。
最佳论文s
下面我们分别介绍下这四篇论文。
第一篇被揭晓的是:Neural Ordinary Differential Equations
作者:Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud。
这篇论文来自加拿大多伦多大学Vector Institute,一作Ricky (Tian Qi) CHEN,本硕毕业于加拿大不列颠哥伦比亚大学,2017年迄今在多伦多大学读博。
这篇论文开发了时间序列建模、监督学习和密度估计的新模型,研究了黑盒ODE求解器作为模型组件的使用。这些模型是自适应评估的,并允许明确控制计算速度和准确度之间的权衡。最后,作者推导了变量公式变化的瞬时版本,并开发了连续归一化流程,而且可以拓展到更大的层尺寸。
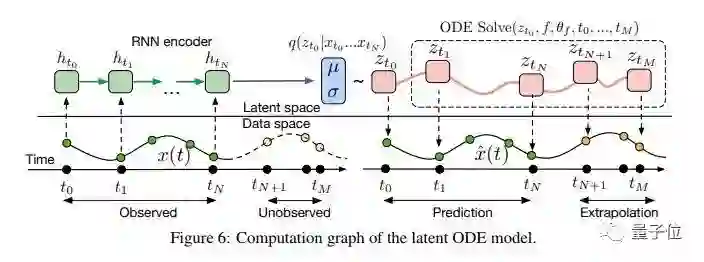
摘要:
We introduce a new family of deep neural network models. Instead of specifying a discrete sequence of hidden layers, we parameterize the derivative of the hidden state using a neural network. The output of the network is computed using a black-box differential equation solver. These continuous-depth models have constant memory cost, adapt their evaluation strategy to each input, and can explicitly trade numerical precision for speed. We demonstrate these properties in continuous-depth residual networks and continuous-time latent variable models. We also construct continuous normalizing flows, a generative model that can train by maximum likelihood, without partitioning or ordering the data dimensions. For training, we show how to scalably backpropagate through any ODE solver, without access to its internal operations. This allows end-to-end training of ODEs within larger models.
论文地址:
https://arxiv.org/abs/1806.07366
第二篇最佳论文:Nearly Tight Sample Complexity Bounds for Learning Mixtures of Gaussians via Sample Compression Schemes
作者:Hassan Ashtiani、Shai Ben-David、Nicholas Harvey、Christopher Liaw、Abbas Mehrabian、Yaniv Plan。他们来自加拿大麦克马斯特大学、滑铁卢大学、不列颠哥伦比亚大学、麦吉尔大学等。
在这篇论文里,作者谈到分布式学习和密度估计的一个核心问题,是表征学习分布类的样本复杂性。在二元分类中, Littlestone-Warmuth压缩的组合概念被证明对学习是足够和必要的,在这项工作中,作者发现新的相关分布压缩足以进行分布式学习。
摘要:
We prove that Θ(kd2/ε2) samples are necessary and sufficient for learning a mixture of k Gaussians in Rd, up to error ε in total variation distance. This improves both the known upper bounds and lower bounds for this problem. For mixtures of axis-aligned Gaussians, we show that Θ(kd2/ε2) samples suffice, matching a known lower bound.
The upper bound is based on a novel technique for distribution learning based on a notion of sample compression. Any class of distributions that allows such a sample compression scheme can also be learned with few samples. Moreover, if a class of distributions has such a compression scheme, then so do the classes of products and mixtures of those distributions. The core of our main result is showing that the class of Gaussians in Rd has an efficient sample compression.
论文地址:
https://papers.nips.cc/paper/7601-nearly-tight-sample-complexity-bounds-for-learning-mixtures-of-gaussians-via-sample-compression-schemes.pdf
第三篇最佳论文:Optimal Algorithms for Non-Smooth Distributed Optimization in Networks
作者:Kevin Scaman、Francis Bach、Sébastien Bubeck、Yin Tat Lee、Laurent Massoulié。他们来自华为诺亚方舟实验室、INRIA、微软研究院、华盛顿大学等机构。
在这篇论文中,作者在两种情况下为非光滑和凸分布式优化提供了最优收敛速度:全局目标函数的Lipschitz连续性和局部个体函数的Lipschitz连续性。此外,作者还提供了第一个最优分散算法:多步原始对偶(MSPD)。
摘要:
In this work, we consider the distributed optimization of non-smooth convex functions using a network of computing units. We investigate this problem under two regularity assumptions: (1) the Lipschitz continuity of the global objective function, and (2) the Lipschitz continuity of local individual functions. Under the local regularity assumption, we provide the first optimal first-order decentralized algorithm called multi-step primal-dual (MSPD) and its corresponding optimal convergence rate. A notable aspect of this result is that, for non-smooth functions, while the dominant term of the error is in O(1/√t), the structure of the communication network only impacts a second-order term in O(1/t), where t is time. In other words, the error due to limits in communication resources decreases at a fast rate even in the case of non-strongly-convex objective functions. Under the global regularity assumption, we provide a simple yet efficient algorithm called distributed randomized smoothing (DRS) based on a local smoothing of the objective function, and show that DRS is within a d1/4 multiplicative factor of the optimal convergence rate, where d is the underlying dimension.
论文地址:
https://arxiv.org/abs/1806.00291
第四篇最佳论文:Non-Delusional Q-Learning and Value-Iteration
作者:Tyler Lu、Dale Schuurmans、Craig Boutilier,他们全都来自Google AI。其中一作Tyler Lu本硕毕业于加拿大滑铁卢大学,博士毕业于多伦多大学。
在这篇论文中,作者指出妄想偏见(delusional bias)成为Q-Learning部署中的一个重要问题,而他们开发并分析了一个新的方法,可以完全消除妄想偏见。作者还提出了几种针对大规模强化学习问题的实用启发式方法,以减轻妄想偏差的影响。
摘要:
We identify a fundamental source of error in Q-learning and other forms of dynamic programming with function approximation. Delusional bias arises when the approximation architecture limits the class of expressible greedy policies. Since standard Q-updates make globally uncoordinated action choices with respect to the expressible policy class, inconsistent or even conflicting Q-value estimates can result, leading to pathological behaviour such as over/under-estimation, instability and even divergence. To solve this problem, we introduce a new notion of policy consistency and define a local backup process that ensures global consistency through the use of information sets—-sets that record constraints on policies consistent with backed-up Q-values. We prove that both the model-based and model-free algorithms using this backup remove delusional bias, yielding the first known algorithms that guarantee optimal results under general conditions. These algorithms furthermore only require polynomially many information sets (from a potentially exponential support). Finally, we suggest other practical heuristics for value-iteration and Q-learning that attempt to reduce delusional bias.
论文地址:
https://papers.nips.cc/paper/8200-non-delusional-q-learning-and-value-iteration
时间检验奖
今年的时间检验奖,颁发给2007年的一篇论文:The Tradeoffs of Large-Scale Learning。
作者:Leon Bottou、Olivier Bousquet,分别来自NEC美国实验室和Google。
在这篇论文中,作者考虑到实例数量和计算时间的预算约束,发现了小规模学习系统和大规模学习系统的泛化性能之间存在质的差异。作者指出,大规模学习系统的泛化属性,取决于估计过程的统计特性和优化算法的计算特性。
摘要:
This contribution develops a theoretical framework that takes into account the effect of approximate optimization on learning algorithms. The analysis shows distinct tradeoffs for the case of small-scale and large-scale learning problems. Small-scale learning problems are subject to the usual approximation–estimation tradeoff. Large-scale learning problems are subject to a qualitatively different tradeoff involving the computational complexity of the underlying optimization algorithms in non-trivial ways.
论文地址:
https://papers.nips.cc/paper/3323-the-tradeoffs-of-large-scale-learning.pdf
想提高入选概率?放源代码呀
除了颁奖之外,NeurIPS大会的组织者们还公布了不少有意思的数据。
首先就是肉眼已然可见的热度。今年参加NeurIPS的,有8000多人,比去年稍多一点点。
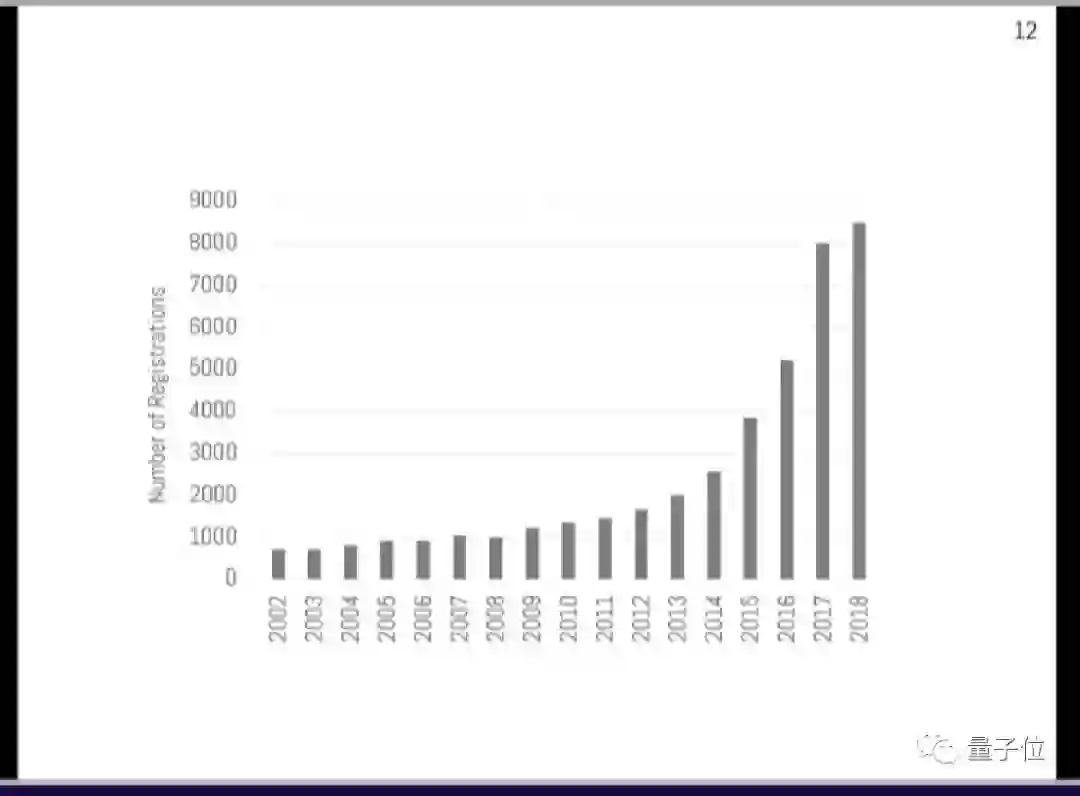
之所以没有暴涨,大概是受场地所限。毕竟,今年NeurIPS放票的时候,11分38秒就已经售罄,比火人节的票还难抢。不过大会的程序主席Hanna Wallach说,还是比碧昂丝演唱会卖得慢嘛。
不仅参加人数多,NeurIPS 2018收到的投稿也涨到了4854篇,不仅和去年相比大幅增长,还是今年ICML的两倍。
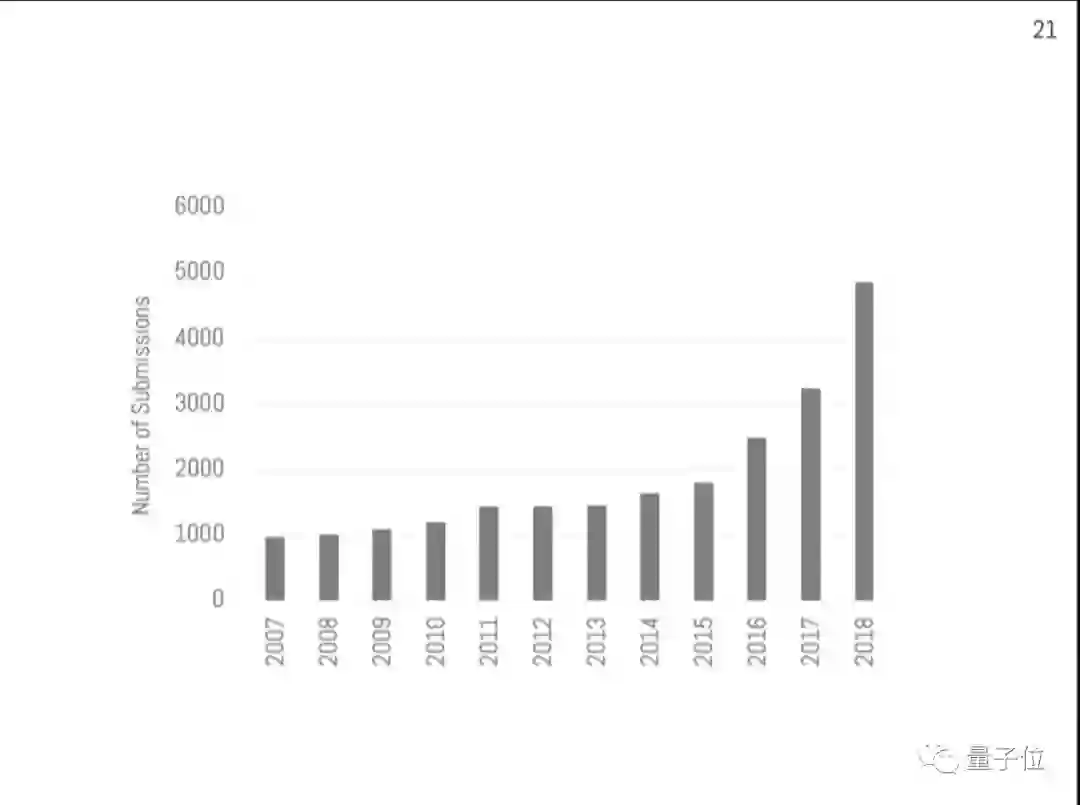
从这些论文所在的领域来看,最火的出人意料,竟然并非大家都在谈的深度学习,而是稍微宽泛一点的“算法”。另外,强化学习的热度虽然高的并不明显,但比去年有大幅上升。

然后是论文的评审情况。
在4834名评审给出15000多条评审意见之后,NeurIPS 2018接收了1010篇论文,其中30篇oral、168篇spotlight、812篇poster。
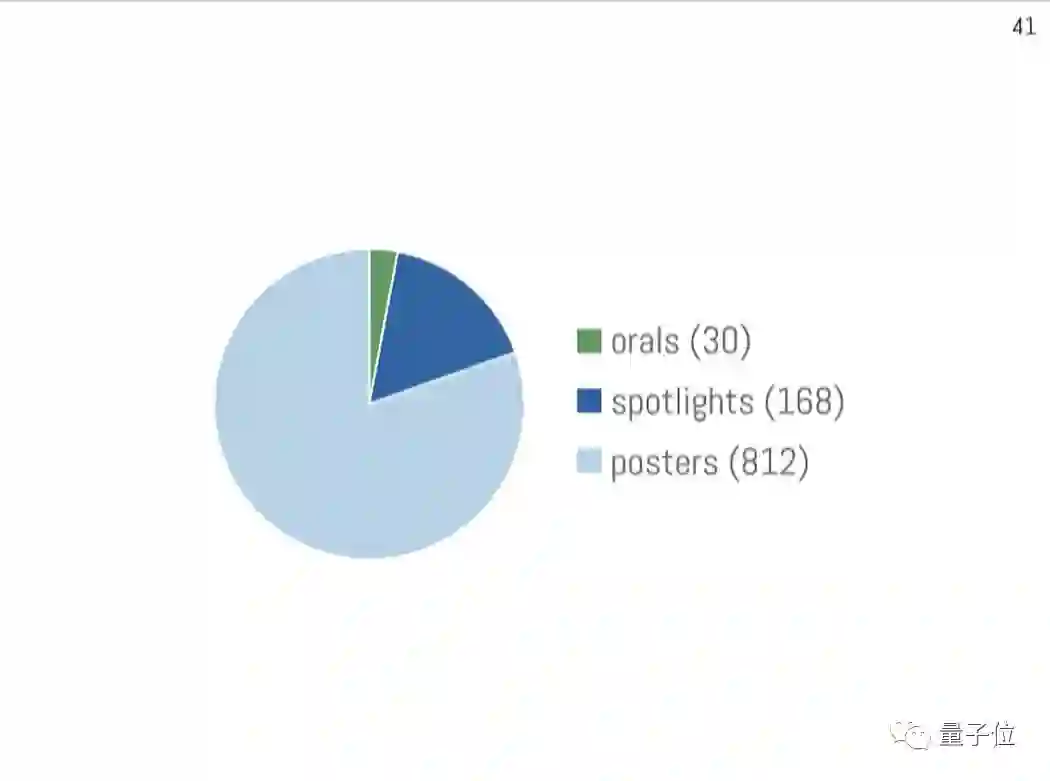
虽然投稿多了不少,但是大会维持着和去年一样的接收率,21%。
不过,这里还有一点人生经验需要传授:如果你顺便开源了代码放出了数据,或者先把论文发到了arXiv上,中NeurIPS的概率就会有一定程度的提升。
不是量子位胡说的,有大会Co-Chair Hugo Larochelle列出的数据为证。他说,如果你提前把论文发在网上,还被至少一位评审者看到了,那么接收率会达到34%;如果你提供了代码或者数据,接收率会达到44%。
在今年的投稿中,有69%的作者说打算开源代码,42%说要放出数据,56%提前把自己的论文发到了网上,其中又有35%被评审人看到了。
One More Thing
今年大会全部论文见:
Advances in Neural Information Processing Systems 31 (NIPS 2018) pre-proceedings
https://papers.nips.cc/book/advances-in-neural-information-processing-systems-31-2018
各大厂照例整理了自家的NeurIPS论文,下面是一系列传送门:
Google
https://ai.googleblog.com/2018/12/google-at-neurips-2018.html
Facebook
https://research.fb.com/facebook-at-neurips-2018/
微软
https://www.microsoft.com/en-us/research/event/neurips-2018/
腾讯
— 完 —
年度评选申请

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态





