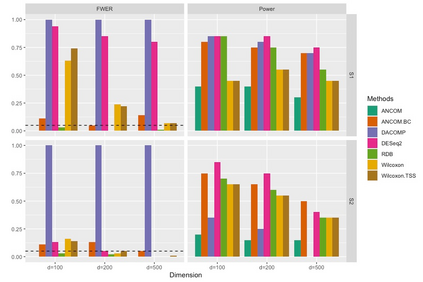
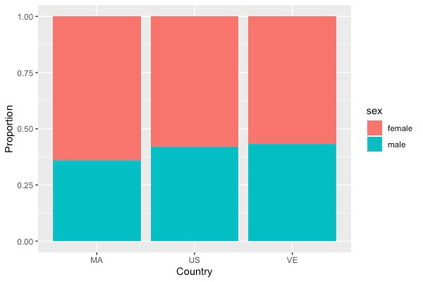
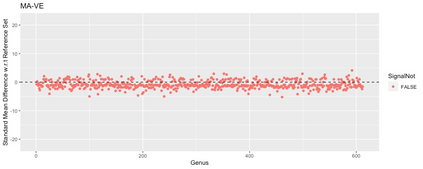
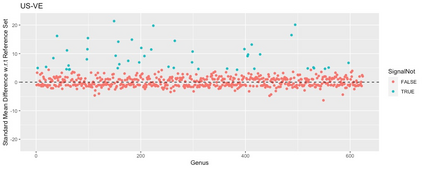
Differential abundance tests in the compositional data are essential and fundamental tasks in various biomedical applications, such as single-cell, bulk RNA-seq, and microbiome data analysis. Despite the recent developments in the fields, differential abundance analysis in the compositional data is still a complicated and unsolved statistical problem because of the compositional constraint and prevalent zero counts in the dataset. A new differential abundance test is introduced in this paper to address these challenges, referred to as the robust differential abundance (RDB) test. Compared with existing methods, the RDB test 1) is simple and computationally efficient, 2) is robust to prevalent zero counts in compositional datasets, 3) can take the data's compositional nature into account, and 4) has a theoretical guarantee to control false discoveries in a general setting. Furthermore, in the presence of observed covariates, the RDB test can work with the covariate balancing techniques to remove the potential confounding effects and draw reliable conclusions. To demonstrate its practical merits, we apply the new test to several numerical examples using both simulated and real datasets.
翻译:组成数据中的不同丰度测试是各种生物医学应用,如单细胞、成批RNA-seq和微生物数据分析中的基本和基本任务。尽管最近在这些领域有了发展,但组成数据中的不同丰度分析仍是一个复杂和未解决的统计问题,因为数据集中存在组成限制和普遍零计现象。本文件引入了新的差异丰度测试,以应对这些挑战,称为强力差异丰度(RDB)测试。与现有方法相比,RDB测试1是简单和具有计算效率的,2)在组成数据集中普遍达到零计数,3)可以将数据的组成性质考虑在内,4)在理论上保证在一般环境中控制错误的发现。此外,在观察到的共变式的情况下,REDB测试可以与共变平衡技术合作,以消除潜在的混结效应并得出可靠的结论。为了证明它的实际价值,我们用模拟和真实的数据集对几个数字实例进行新的测试。