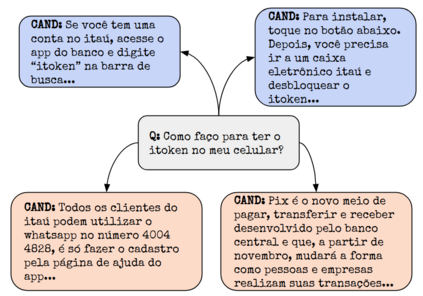
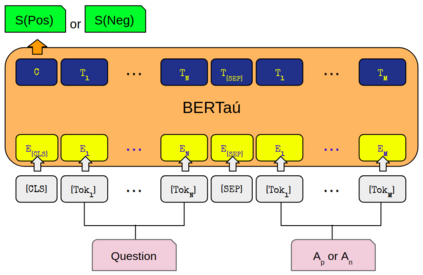
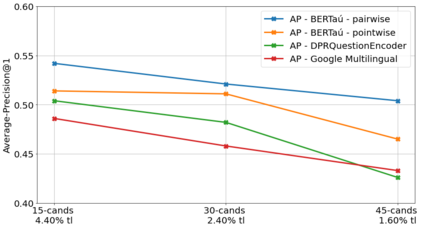
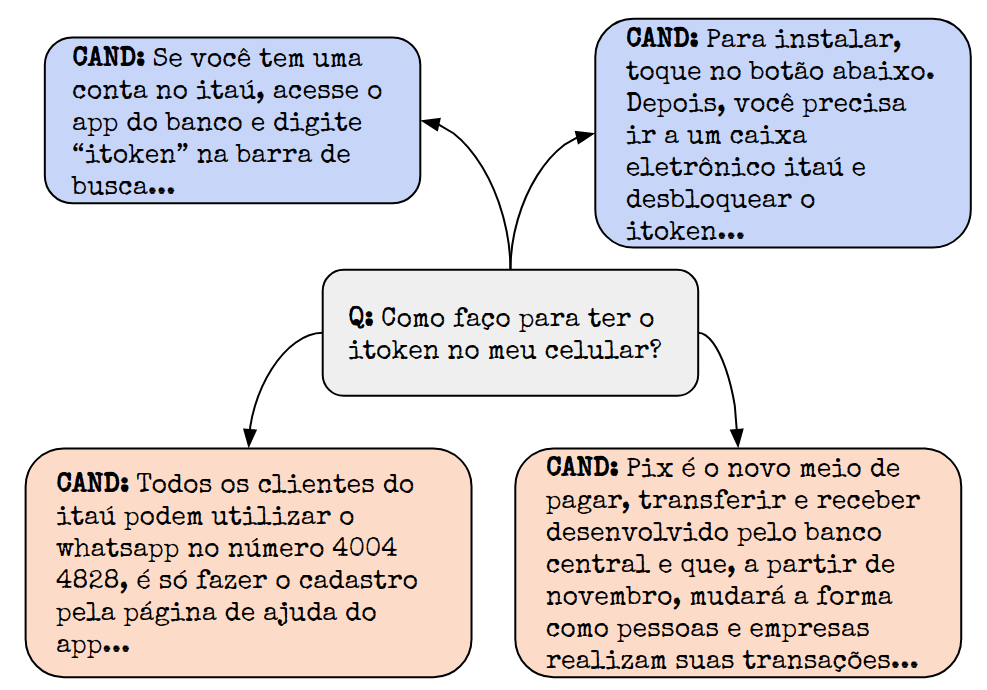
In the last few years, three major topics received increased interest: deep learning, NLP and conversational agents. Bringing these three topics together to create an amazing digital customer experience and indeed deploy in production and solve real-world problems is something innovative and disruptive. We introduce a new Portuguese financial domain language representation model called BERTa\'u. BERTa\'u is an uncased BERT-base trained from scratch with data from the Ita\'u virtual assistant chatbot solution. Our novel contribution is that BERTa\'u pretrained language model requires less data, reached state-of-the-art performance in three NLP tasks, and generates a smaller and lighter model that makes the deployment feasible. We developed three tasks to validate our model: information retrieval with Frequently Asked Questions (FAQ) from Ita\'u bank, sentiment analysis from our virtual assistant data, and a NER solution. All proposed tasks are real-world solutions in production on our environment and the usage of a specialist model proved to be effective when compared to Google BERT multilingual and the DPRQuestionEncoder from Facebook, available at Hugging Face. The BERTa\'u improves the performance in 22% of FAQ Retrieval MRR metric, 2.1% in Sentiment Analysis F1 score, 4.4% in NER F1 score and can also represent the same sequence in up to 66% fewer tokens when compared to "shelf models".
翻译:在过去几年里,三个主要议题受到越来越多的关注:深层次的学习、NLP和谈话代理人。将这三个主题结合起来,以创造惊人的数字客户经验,并实际在生产和解决现实世界问题中部署,是创新和破坏性的。我们引入了一个新的葡萄牙金融域语言代表模式,名为BERTa\'u。BERTa\'u是一个非案例的BERT数据库,从头开始,用Ita\'u 虚拟助理聊天室解决方案的数据进行感应分析。我们的新贡献是,BERTa\'u预先培训的语言模型需要较少的数据,在三项NLP任务中达到最新艺术表现,并产生一个更小、更轻的模型。我们开发了三个任务来验证我们的模型:用Ita\'u银行的常见问题检索信息,从我们的虚拟助理数据中进行情绪分析,以及NER解决方案。所有拟议的任务都是我们环境中生产的真实世界模式,使用专家模型证明,与Google BERT多语种和DPR Vender Encoder相比是有效的,在22的FPR1 RUDSBrieal AS deal Procial AS,也代表了22的F Rup的F Rupriebriew Ex的Briew Ex Excial Excial 1 Excial Sapplement,在Facebook上改进了22的Brippres Brial 1,在F Rus dr drup 1 drupal 1,在22 Basal Stal 1,在Facebook上,在22 Bropplyment 1 drupal 1 drupment 1 drupal Strippal 1,在22的BAbbal Stribal 1,在22 Bal Stribal Stribal Stal 1,在Facebook上,在22 dia 1 Stal Stal Stal Stal Stal Stabal Stal Stal Stal 1到22的BAbal Stal Stal Stabal dia上可以使用。